⏳️ Loading...
class: title, self-paced Introduction<br/>to Containers<br/> .nav[*Self-paced version*] .debug[ ``` ``` These slides have been built from commit: 5f8277d [shared/title.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/title.md)] --- class: title, in-person Introduction<br/>to Containers<br/><br/></br> .footnote[ **Slides[:](https://www.youtube.com/watch?v=h16zyxiwDLY) https://container.training/** ] <!-- WiFi: **Something**<br/> Password: **Something** **Be kind to the WiFi!**<br/> *Use the 5G network.* *Don't use your hotspot.*<br/> *Don't stream videos or download big files during the workshop*<br/> *Thank you!* --> .debug[[shared/title.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/title.md)] --- ## Accessing these slides now - We recommend that you open these slides in your browser: https://container.training/ - This is a public URL, you're welcome to share it with others! - Use arrows to move to next/previous slide (up, down, left, right, page up, page down) - Type a slide number + ENTER to go to that slide - The slide number is also visible in the URL bar (e.g. .../#123 for slide 123) .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## These slides are open source - The sources of these slides are available in a public GitHub repository: https://github.com/jpetazzo/container.training - These slides are written in Markdown - You are welcome to share, re-use, re-mix these slides - Typos? Mistakes? Questions? Feel free to hover over the bottom of the slide ... .footnote[👇 Try it! The source file will be shown and you can view it on GitHub and fork and edit it.] <!-- .lab[ ```open https://github.com/jpetazzo/container.training/tree/master/slides/common/about-slides.md``` ] --> .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## Accessing these slides later - Slides will remain online so you can review them later if needed (let's say we'll keep them online at least 1 year, how about that?) - You can download the slides using this URL: https://container.training/slides.zip (then open the file `intro-selfpaced.yml.html`) - You can also generate a PDF of the slides (by printing them to a file; but be patient with your browser!) .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## These slides are constantly updated - They are maintained by [Jérôme Petazzoni](https://hachyderm.io/@jpetazzo/) and [multiple contributors](https://github.com/jpetazzo/container.training/graphs/contributors) - Feel free to check the GitHub repository for updates: https://github.com/jpetazzo/container.training - Look for branches named YYYY-MM-... - You can also find specific decks and other resources on: https://container.training/ .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- class: extra-details ## Extra details - This slide has a little magnifying glass in the top left corner - This magnifying glass indicates slides that provide extra details - Feel free to skip them if: - you are in a hurry - you are new to this and want to avoid cognitive overload - you want only the most essential information - You can review these slides another time if you want, they'll be waiting for you ☺ .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## Slides ≠ documentation - We tried to include a lot of information in these slides - But they don't replace or compete with the documentation! - Treat these slides as yet another pillar to support your learning experience - Don't hesitate to frequently read the documentations ([Docker documentation][docker-docs], [Kubernetes documentation][k8s-docs]) - And online communities (e.g.: [Docker forums][docker-forums], [Docker on StackOverflow][docker-so], [Kubernetes on StackOverflow][k8s-so]) [docker-docs]: https://docs.docker.com/ [k8s-docs]: https://kubernetes.io/docs/ [docker-forums]: https://forums.docker.com/ [docker-so]: http://stackoverflow.com/questions/tagged/docker [k8s-so]: http://stackoverflow.com/questions/tagged/kubernetes .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- class: title *Tell me and I forget.* <br/> *Teach me and I remember.* <br/> *Involve me and I learn.* Misattributed to Benjamin Franklin [(Probably inspired by Chinese Confucian philosopher Xunzi)](https://www.barrypopik.com/index.php/new_york_city/entry/tell_me_and_i_forget_teach_me_and_i_may_remember_involve_me_and_i_will_lear/) .debug[[shared/handson.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/handson.md)] --- ## Hands-on, you shall practice - Nobody ever became a Jedi by spending their lives reading Wookiepedia - Someone can: - read all the docs - watch all the videos - attend all the workshops and live classes - ...This won't be enough to become an expert! - We think one needs to *put the concepts in practice* to truly memorize them - But, how? .debug[[shared/handson.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/handson.md)] --- ## Hands-on labs - These slides include *tons* of demos, examples, and exercises - Don't follow along passively; try to reproduce the demos and examples! - Each time you see a gray rectangle like this, it indicates a demo or example .lab[ - This is a command that we're gonna run: ```bash echo hello world ``` ] - Don't hesitate to try them in your environment - Don't hesitate to improvise, deviate from the script... And see what happens! .debug[[shared/handson.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/handson.md)] --- ## Running your own lab environments - If you are doing or re-doing this course on your own, you can: - install [Docker Desktop][docker-desktop] or [Podman Desktop][podman-desktop] <br/>(available for Linux, Mac, Windows; provides a nice GUI) - install [Docker CE][docker-ce] or [Podman][podman] <br/>(for intermediate/advanced users who prefer the CLI) - use an online platform like [KodeKloud] <br/>(if you can't/won't install anything locally) [docker-desktop]: https://docs.docker.com/desktop/ [podman-desktop]: https://podman-desktop.io/downloads [docker-ce]: https://docs.docker.com/engine/install/ [podman]: https://podman.io/docs/installation#installing-on-linux [KodeKloud]: https://kodekloud.com/free-labs/docker/ .debug[[containers/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/labs-async.md)] --- name: toc-part-1 ## Part 1 - [Docker 30,000ft overview](#toc-docker-ft-overview) - [History of containers ... and Docker](#toc-history-of-containers--and-docker) - [Installing Docker](#toc-installing-docker) - [Our first containers](#toc-our-first-containers) - [Background containers](#toc-background-containers) - [Restarting and attaching to containers](#toc-restarting-and-attaching-to-containers) .debug[(auto-generated TOC)] --- name: toc-part-2 ## Part 2 - [Understanding Docker images](#toc-understanding-docker-images) - [Building images interactively](#toc-building-images-interactively) - [Building Docker images with a Dockerfile](#toc-building-docker-images-with-a-dockerfile) - [`CMD` and `ENTRYPOINT`](#toc-cmd-and-entrypoint) - [Copying files during the build](#toc-copying-files-during-the-build) - [Exercise — writing Dockerfiles](#toc-exercise--writing-dockerfiles) .debug[(auto-generated TOC)] --- name: toc-part-3 ## Part 3 - [Reducing image size](#toc-reducing-image-size) - [Multi-stage builds](#toc-multi-stage-builds) - [Publishing images to the Docker Hub](#toc-publishing-images-to-the-docker-hub) - [Tips for efficient Dockerfiles](#toc-tips-for-efficient-dockerfiles) - [Dockerfile examples](#toc-dockerfile-examples) - [Exercise — multi-stage builds](#toc-exercise--multi-stage-builds) .debug[(auto-generated TOC)] --- name: toc-part-4 ## Part 4 - [Naming and inspecting containers](#toc-naming-and-inspecting-containers) - [Labels](#toc-labels) - [Getting inside a container](#toc-getting-inside-a-container) .debug[(auto-generated TOC)] --- name: toc-part-5 ## Part 5 - [Container networking basics](#toc-container-networking-basics) - [Container network drivers](#toc-container-network-drivers) - [The Container Network Model](#toc-the-container-network-model) - [Service discovery with containers](#toc-service-discovery-with-containers) - [Ambassadors](#toc-ambassadors) .debug[(auto-generated TOC)] --- name: toc-part-6 ## Part 6 - [Local development workflow with Docker](#toc-local-development-workflow-with-docker) - [Windows Containers](#toc-windows-containers) - [Working with volumes](#toc-working-with-volumes) - [Gentle introduction to YAML](#toc-gentle-introduction-to-yaml) - [Compose for development stacks](#toc-compose-for-development-stacks) - [Exercise — writing a Compose file](#toc-exercise--writing-a-compose-file) - [Managing hosts with Docker Machine](#toc-managing-hosts-with-docker-machine) .debug[(auto-generated TOC)] --- name: toc-part-7 ## Part 7 - [Advanced Dockerfile Syntax](#toc-advanced-dockerfile-syntax) - [Buildkit](#toc-buildkit) - [Exercise — BuildKit cache mounts](#toc-exercise--buildkit-cache-mounts) - [Init systems and PID 1](#toc-init-systems-and-pid-) - [Application Configuration](#toc-application-configuration) - [Logging](#toc-logging) - [Limiting resources](#toc-limiting-resources) .debug[(auto-generated TOC)] --- name: toc-part-8 ## Part 8 - [Deep dive into container internals](#toc-deep-dive-into-container-internals) - [Control groups](#toc-control-groups) - [Namespaces](#toc-namespaces) - [Security features](#toc-security-features) - [Copy-on-write filesystems](#toc-copy-on-write-filesystems) - [Building containers from scratch](#toc-building-containers-from-scratch) - [Security models](#toc-security-models) - [Rootless Networking](#toc-rootless-networking) - [Deep Dive Into Images](#toc-deep-dive-into-images) .debug[(auto-generated TOC)] --- name: toc-part-9 ## Part 9 - [Docker Engine and other container engines](#toc-docker-engine-and-other-container-engines) - [Container Super-structure](#toc-container-super-structure) - [The container ecosystem](#toc-the-container-ecosystem) - [Orchestration, an overview](#toc-orchestration-an-overview) - [Links and resources](#toc-links-and-resources) .debug[(auto-generated TOC)] .debug[[shared/toc.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/toc.md)] --- class: pic .interstitial[] --- name: toc-docker-ft-overview class: title Docker 30,000ft overview .nav[ [Previous part](#toc-) | [Back to table of contents](#toc-part-1) | [Next part](#toc-history-of-containers--and-docker) ] .debug[(automatically generated title slide)] --- # Docker 30,000ft overview In this lesson, we will learn about: * Why containers (non-technical elevator pitch) * Why containers (technical elevator pitch) * How Docker helps us to build, ship, and run * The history of containers We won't actually run Docker or containers in this chapter (yet!). Don't worry, we will get to that fast enough! .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## Elevator pitch ### (for your manager, your boss...) .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## OK... Why the buzz around containers? * The software industry has changed * Before: * monolithic applications * long development cycles * single environment * slowly scaling up * Now: * decoupled services * fast, iterative improvements * multiple environments * quickly scaling out .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## Deployment becomes very complex * Many different stacks: * languages * frameworks * databases * Many different targets: * individual development environments * pre-production, QA, staging... * production: on prem, cloud, hybrid .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## The deployment problem 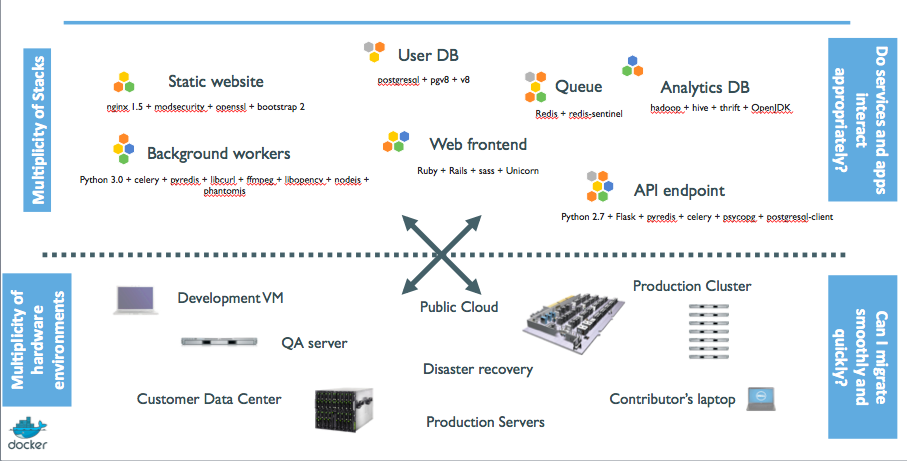 .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## The matrix from hell  .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## The parallel with the shipping industry  .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## Intermodal shipping containers 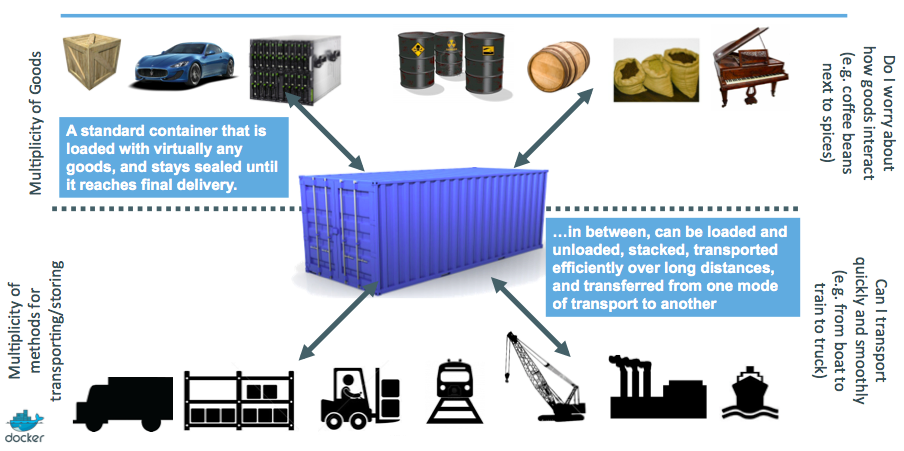 .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## A new shipping ecosystem  .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## A shipping container system for applications 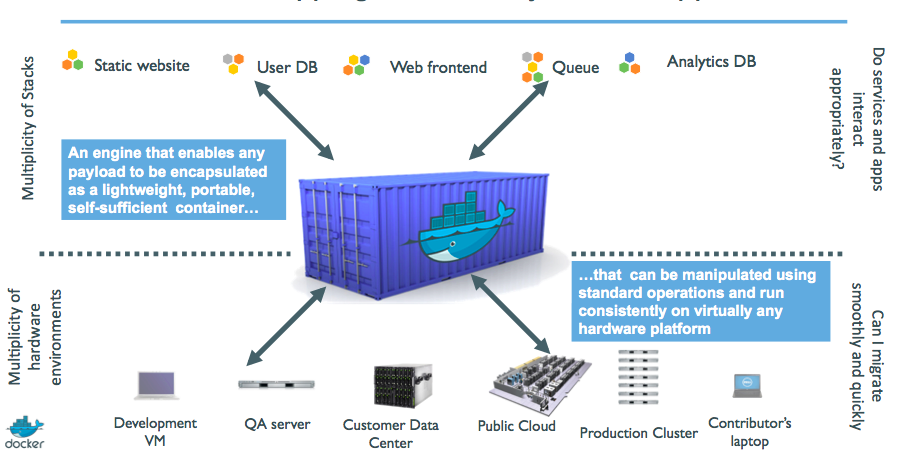 .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic ## Eliminate the matrix from hell 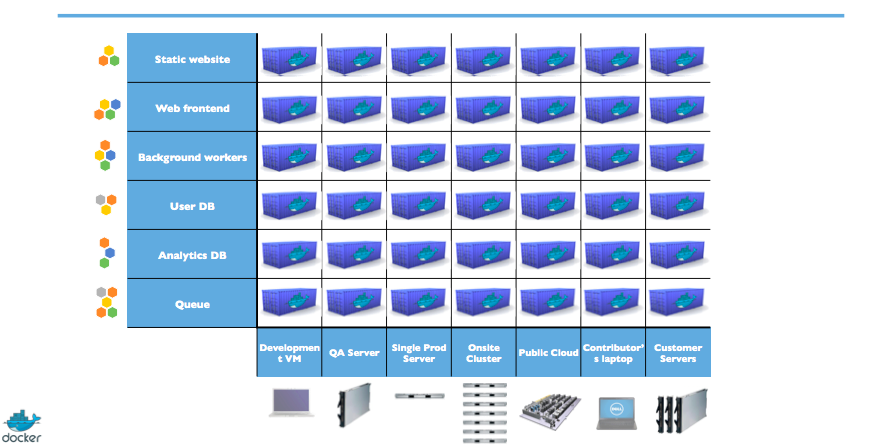 .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## Results * [Dev-to-prod reduced from 9 months to 15 minutes (ING)]( https://gallant-turing-d0d520.netlify.com/docker-case-studies/CS_ING_01.25.2015_1.pdf) * [Continuous integration job time reduced by more than 60% (BBC)]( https://gallant-turing-d0d520.netlify.com/docker-case-studies/CS_BBCNews_01.25.2015_1.pdf) * [Deploy 100 times a day instead of once a week (GILT)]( https://gallant-turing-d0d520.netlify.com/docker-case-studies/CS_Gilt_Groupe_03.18.2015_0.pdf) * [70% infrastructure consolidation (MetLife)]( https://www.youtube.com/watch?v=Bwt3xigvlj0) * etc. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## Elevator pitch ### (for your fellow devs and ops) .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## Escape dependency hell 1. Write installation instructions into an `INSTALL.txt` file 2. Using this file, write an `install.sh` script that works *for you* 3. Turn this file into a `Dockerfile`, test it on your machine 4. If the Dockerfile builds on your machine, it will build *anywhere* 5. Rejoice as you escape dependency hell and "works on my machine" Never again "worked in dev - ops problem now!" .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- ## On-board developers and contributors rapidly 1. Write Dockerfiles for your application components 2. Use pre-made images from the Docker Hub (mysql, redis...) 3. Describe your stack with a Compose file 4. On-board somebody with two commands: ```bash git clone ... docker-compose up ``` With this, you can create development, integration, QA environments in minutes! .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Implement reliable CI easily 1. Build test environment with a Dockerfile or Compose file 2. For each test run, stage up a new container or stack 3. Each run is now in a clean environment 4. No pollution from previous tests Way faster and cheaper than creating VMs each time! .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Use container images as build artefacts 1. Build your app from Dockerfiles 2. Store the resulting images in a registry 3. Keep them forever (or as long as necessary) 4. Test those images in QA, CI, integration... 5. Run the same images in production 6. Something goes wrong? Rollback to previous image 7. Investigating old regression? Old image has your back! Images contain all the libraries, dependencies, etc. needed to run the app. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Decouple "plumbing" from application logic 1. Write your code to connect to named services ("db", "api"...) 2. Use Compose to start your stack 3. Docker will setup per-container DNS resolver for those names 4. You can now scale, add load balancers, replication ... without changing your code Note: this is not covered in this intro level workshop! .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## What did Docker bring to the table? ### Docker before/after .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Formats and APIs, before Docker * No standardized exchange format. <br/>(No, a rootfs tarball is *not* a format!) * Containers are hard to use for developers. <br/>(Where's the equivalent of `docker run debian`?) * As a result, they are *hidden* from the end users. * No re-usable components, APIs, tools. <br/>(At best: VM abstractions, e.g. libvirt.) Analogy: * Shipping containers are not just steel boxes. * They are steel boxes that are a standard size, with the same hooks and holes. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Formats and APIs, after Docker * Standardize the container format, because containers were not portable. * Make containers easy to use for developers. * Emphasis on re-usable components, APIs, ecosystem of standard tools. * Improvement over ad-hoc, in-house, specific tools. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Shipping, before Docker * Ship packages: deb, rpm, gem, jar, homebrew... * Dependency hell. * "Works on my machine." * Base deployment often done from scratch (debootstrap...) and unreliable. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Shipping, after Docker * Ship container images with all their dependencies. * Images are bigger, but they are broken down into layers. * Only ship layers that have changed. * Save disk, network, memory usage. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Example Layers: * CentOS * JRE * Tomcat * Dependencies * Application JAR * Configuration .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Devs vs Ops, before Docker * Drop a tarball (or a commit hash) with instructions. * Dev environment very different from production. * Ops don't always have a dev environment themselves ... * ... and when they do, it can differ from the devs'. * Ops have to sort out differences and make it work ... * ... or bounce it back to devs. * Shipping code causes frictions and delays. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: extra-details ## Devs vs Ops, after Docker * Drop a container image or a Compose file. * Ops can always run that container image. * Ops can always run that Compose file. * Ops still have to adapt to prod environment, but at least they have a reference point. * Ops have tools allowing to use the same image in dev and prod. * Devs can be empowered to make releases themselves more easily. .debug[[containers/Docker_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Overview.md)] --- class: pic .interstitial[] --- name: toc-history-of-containers--and-docker class: title History of containers ... and Docker .nav[ [Previous part](#toc-docker-ft-overview) | [Back to table of contents](#toc-part-1) | [Next part](#toc-installing-docker) ] .debug[(automatically generated title slide)] --- # History of containers ... and Docker .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## First experimentations * [IBM VM/370 (1972)](https://en.wikipedia.org/wiki/VM_%28operating_system%29) * [Linux VServers (2001)](http://www.solucorp.qc.ca/changes.hc?projet=vserver) * [Solaris Containers (2004)](https://en.wikipedia.org/wiki/Solaris_Containers) * [FreeBSD jails (1999-2000)](https://www.freebsd.org/cgi/man.cgi?query=jail&sektion=8&manpath=FreeBSD+4.0-RELEASE) Containers have been around for a *very long time* indeed. (See [this excellent blog post by Serge Hallyn](https://s3hh.wordpress.com/2018/03/22/history-of-containers/) for more historic details.) .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- class: pic ## The VPS age (until 2007-2008) 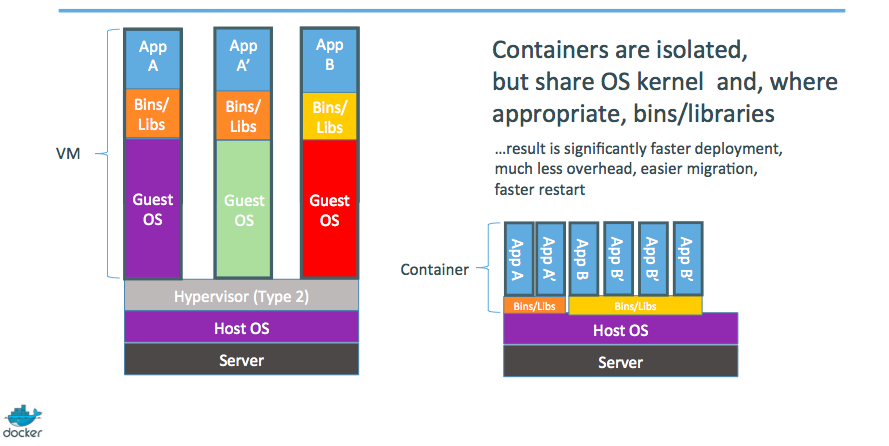 .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Containers = cheaper than VMs * Users: hosting providers. * Highly specialized audience with strong ops culture. .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- class: pic ## The PAAS period (2008-2013)  .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Containers = easier than VMs * I can't speak for Heroku, but containers were (one of) dotCloud's secret weapon * dotCloud was operating a PaaS, using a custom container engine. * This engine was based on OpenVZ (and later, LXC) and AUFS. * It started (circa 2008) as a single Python script. * By 2012, the engine had multiple (~10) Python components. <br/>(and ~100 other micro-services!) * End of 2012, dotCloud refactors this container engine. * The codename for this project is "Docker." .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## First public release of Docker * March 2013, PyCon, Santa Clara: <br/>"Docker" is shown to a public audience for the first time. * It is released with an open source license. * Very positive reactions and feedback! * The dotCloud team progressively shifts to Docker development. * The same year, dotCloud changes name to Docker. * In 2014, the PaaS activity is sold. .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Docker early days (2013-2014) .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## First users of Docker * PAAS builders (Flynn, Dokku, Tsuru, Deis...) * PAAS users (those big enough to justify building their own) * CI platforms * developers, developers, developers, developers .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Positive feedback loop * In 2013, the technology under containers (cgroups, namespaces, copy-on-write storage...) had many blind spots. * The growing popularity of Docker and containers exposed many bugs. * As a result, those bugs were fixed, resulting in better stability for containers. * Any decent hosting/cloud provider can run containers today. * Containers become a great tool to deploy/move workloads to/from on-prem/cloud. .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Maturity (2015-2016) .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Docker becomes an industry standard * Docker reaches the symbolic 1.0 milestone. * Existing systems like Mesos and Cloud Foundry add Docker support. * Standardization around the OCI (Open Containers Initiative). * Other container engines are developed. * Creation of the CNCF (Cloud Native Computing Foundation). .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Docker becomes a platform * The initial container engine is now known as "Docker Engine." * Other tools are added: * Docker Compose (formerly "Fig") * Docker Machine * Docker Swarm * Kitematic * Docker Cloud (formerly "Tutum") * Docker Datacenter * etc. * Docker Inc. launches commercial offers. .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- ## Standardization of container runtimes - Docker 1.11 (2016) introduces containerd and runc - [Kubernetes 1.5 (2016)](https://kubernetes.io/blog/2016/12/kubernetes-1-5-supporting-production-workloads/) introduces the CRI - First releases of CRI-O (2017), kata containers... .debug[[containers/Docker_History.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_History.md)] --- class: pic .interstitial[] --- name: toc-installing-docker class: title Installing Docker .nav[ [Previous part](#toc-history-of-containers--and-docker) | [Back to table of contents](#toc-part-1) | [Next part](#toc-our-first-containers) ] .debug[(automatically generated title slide)] --- class: title # Installing Docker  .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Objectives At the end of this lesson, you will know: * How to install Docker. * When to use `sudo` when running Docker commands. *Note:* if you were provided with a training VM for a hands-on tutorial, you can skip this chapter, since that VM already has Docker installed, and Docker has already been setup to run without `sudo`. .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Installing Docker There are many ways to install Docker. We can arbitrarily distinguish: * Installing Docker on an existing Linux machine (physical or VM) * Installing Docker on macOS or Windows * Installing Docker on a fleet of cloud VMs .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Installing Docker on Linux * The recommended method is to install the packages supplied by Docker Inc : - add Docker Inc.'s package repositories to your system configuration - install the Docker Engine * Detailed installation instructions (distro by distro) are available on: https://docs.docker.com/engine/installation/ * You can also install from binaries (if your distro is not supported): https://docs.docker.com/engine/installation/linux/docker-ce/binaries/ * To quickly setup a dev environment, Docker provides a convenience install script: ```bash curl -fsSL get.docker.com | sh ``` .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- class: extra-details ## Docker Inc. packages vs distribution packages * Docker Inc. releases new versions monthly (edge) and quarterly (stable) * Releases are immediately available on Docker Inc.'s package repositories * Linux distros don't always update to the latest Docker version (Sometimes, updating would break their guidelines for major/minor upgrades) * Sometimes, some distros have carried packages with custom patches * Sometimes, these patches added critical security bugs ☹ * Installing through Docker Inc.'s repositories is a bit of extra work … … but it is generally worth it! .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Installing Docker on macOS and Windows * On macOS, the recommended method is to use Docker Desktop for Mac: https://docs.docker.com/docker-for-mac/install/ * On Windows 10 Pro, Enterprise, and Education, you can use Docker Desktop for Windows: https://docs.docker.com/docker-for-windows/install/ * On older versions of Windows, you can use the Docker Toolbox: https://docs.docker.com/toolbox/toolbox_install_windows/ * On Windows Server 2016, you can also install the native engine: https://docs.docker.com/install/windows/docker-ee/ .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Docker Desktop * Special Docker edition available for Mac and Windows * Integrates well with the host OS: * installed like normal user applications on the host * provides user-friendly GUI to edit Docker configuration and settings * Only support running one Docker VM at a time ... ... but we can use `docker-machine`, the Docker Toolbox, VirtualBox, etc. to get a cluster. .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- class: extra-details ## Docker Desktop internals * Leverages the host OS virtualization subsystem (e.g. the [Hypervisor API](https://developer.apple.com/documentation/hypervisor) on macOS) * Under the hood, runs a tiny VM (transparent to our daily use) * Accesses network resources like normal applications (and therefore, plays better with enterprise VPNs and firewalls) * Supports filesystem sharing through volumes (we'll talk about this later) .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Running Docker on macOS and Windows When you execute `docker version` from the terminal: * the CLI connects to the Docker Engine over a standard socket, * the Docker Engine is, in fact, running in a VM, * ... but the CLI doesn't know or care about that, * the CLI sends a request using the REST API, * the Docker Engine in the VM processes the request, * the CLI gets the response and displays it to you. All communication with the Docker Engine happens over the API. This will also allow to use remote Engines exactly as if they were local. .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- ## Important PSA about security * If you have access to the Docker control socket, you can take over the machine (Because you can run containers that will access the machine's resources) * Therefore, on Linux machines, the `docker` user is equivalent to `root` * You should restrict access to it like you would protect `root` * By default, the Docker control socket belongs to the `docker` group * You can add trusted users to the `docker` group * Otherwise, you will have to prefix every `docker` command with `sudo`, e.g.: ```bash sudo docker version ``` .debug[[containers/Installing_Docker.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Installing_Docker.md)] --- class: pic .interstitial[] --- name: toc-our-first-containers class: title Our first containers .nav[ [Previous part](#toc-installing-docker) | [Back to table of contents](#toc-part-1) | [Next part](#toc-background-containers) ] .debug[(automatically generated title slide)] --- class: title # Our first containers  .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Objectives At the end of this lesson, you will have: * Seen Docker in action. * Started your first containers. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Hello World In your Docker environment, just run the following command: ```bash $ docker run busybox echo hello world hello world ``` (If your Docker install is brand new, you will also see a few extra lines, corresponding to the download of the `busybox` image.) .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## That was our first container! * We used one of the smallest, simplest images available: `busybox`. * `busybox` is typically used in embedded systems (phones, routers...) * We ran a single process and echo'ed `hello world`. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## A more useful container Let's run a more exciting container: ```bash $ docker run -it ubuntu root@04c0bb0a6c07:/# ``` * This is a brand new container. * It runs a bare-bones, no-frills `ubuntu` system. * `-it` is shorthand for `-i -t`. * `-i` tells Docker to connect us to the container's stdin. * `-t` tells Docker that we want a pseudo-terminal. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Do something in our container Try to run `figlet` in our container. ```bash root@04c0bb0a6c07:/# figlet hello bash: figlet: command not found ``` Alright, we need to install it. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Install a package in our container We want `figlet`, so let's install it: ```bash root@04c0bb0a6c07:/# apt-get update ... Fetched 1514 kB in 14s (103 kB/s) Reading package lists... Done root@04c0bb0a6c07:/# apt-get install figlet Reading package lists... Done ... ``` One minute later, `figlet` is installed! .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Try to run our freshly installed program The `figlet` program takes a message as parameter. ```bash root@04c0bb0a6c07:/# figlet hello _ _ _ | |__ ___| | | ___ | '_ \ / _ \ | |/ _ \ | | | | __/ | | (_) | |_| |_|\___|_|_|\___/ ``` Beautiful! 😍 .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- class: in-person ## Counting packages in the container Let's check how many packages are installed there. ```bash root@04c0bb0a6c07:/# dpkg -l | wc -l 97 ``` * `dpkg -l` lists the packages installed in our container * `wc -l` counts them How many packages do we have on our host? .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- class: in-person ## Counting packages on the host Exit the container by logging out of the shell, like you would usually do. (E.g. with `^D` or `exit`) ```bash root@04c0bb0a6c07:/# exit ``` Now, try to: * run `dpkg -l | wc -l`. How many packages are installed? * run `figlet`. Does that work? .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- class: self-paced ## Comparing the container and the host Exit the container by logging out of the shell, with `^D` or `exit`. Now try to run `figlet`. Does that work? (It shouldn't; except if, by coincidence, you are running on a machine where figlet was installed before.) .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Host and containers are independent things * We ran an `ubuntu` container on an Linux/Windows/macOS host. * They have different, independent packages. * Installing something on the host doesn't expose it to the container. * And vice-versa. * Even if both the host and the container have the same Linux distro! * We can run *any container* on *any host*. (One exception: Windows containers can only run on Windows hosts; at least for now.) .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Where's our container? * Our container is now in a *stopped* state. * It still exists on disk, but all compute resources have been freed up. * We will see later how to get back to that container. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Starting another container What if we start a new container, and try to run `figlet` again? ```bash $ docker run -it ubuntu root@b13c164401fb:/# figlet bash: figlet: command not found ``` * We started a *brand new container*. * The basic Ubuntu image was used, and `figlet` is not here. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Where's my container? * Can we reuse that container that we took time to customize? *We can, but that's not the default workflow with Docker.* * What's the default workflow, then? *Always start with a fresh container.* <br/> *If we need something installed in our container, build a custom image.* * That seems complicated! *We'll see that it's actually pretty easy!* * And what's the point? *This puts a strong emphasis on automation and repeatability. Let's see why ...* .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Pets vs. Cattle * In the "pets vs. cattle" metaphor, there are two kinds of servers. * Pets: * have distinctive names and unique configurations * when they have an outage, we do everything we can to fix them * Cattle: * have generic names (e.g. with numbers) and generic configuration * configuration is enforced by configuration management, golden images ... * when they have an outage, we can replace them immediately with a new server * What's the connection with Docker and containers? .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Local development environments * When we use local VMs (with e.g. VirtualBox or VMware), our workflow looks like this: * create VM from base template (Ubuntu, CentOS...) * install packages, set up environment * work on project * when done, shut down VM * next time we need to work on project, restart VM as we left it * if we need to tweak the environment, we do it live * Over time, the VM configuration evolves, diverges. * We don't have a clean, reliable, deterministic way to provision that environment. .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- ## Local development with Docker * With Docker, the workflow looks like this: * create container image with our dev environment * run container with that image * work on project * when done, shut down container * next time we need to work on project, start a new container * if we need to tweak the environment, we create a new image * We have a clear definition of our environment, and can share it reliably with others. * Let's see in the next chapters how to bake a custom image with `figlet`! ??? :EN:- Running our first container :FR:- Lancer nos premiers conteneurs .debug[[containers/First_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/First_Containers.md)] --- class: pic .interstitial[] --- name: toc-background-containers class: title Background containers .nav[ [Previous part](#toc-our-first-containers) | [Back to table of contents](#toc-part-1) | [Next part](#toc-restarting-and-attaching-to-containers) ] .debug[(automatically generated title slide)] --- class: title # Background containers  .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Objectives Our first containers were *interactive*. We will now see how to: * Run a non-interactive container. * Run a container in the background. * List running containers. * Check the logs of a container. * Stop a container. * List stopped containers. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## A non-interactive container We will run a small custom container. This container just displays the time every second. ```bash $ docker run jpetazzo/clock Fri Feb 20 00:28:53 UTC 2015 Fri Feb 20 00:28:54 UTC 2015 Fri Feb 20 00:28:55 UTC 2015 ... ``` * This container will run forever. * To stop it, press `^C`. * Docker has automatically downloaded the image `jpetazzo/clock`. * This image is a user image, created by `jpetazzo`. * We will hear more about user images (and other types of images) later. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## When `^C` doesn't work... Sometimes, `^C` won't be enough. Why? And how can we stop the container in that case? .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## What happens when we hit `^C` `SIGINT` gets sent to the container, which means: - `SIGINT` gets sent to PID 1 (default case) - `SIGINT` gets sent to *foreground processes* when running with `-ti` But there is a special case for PID 1: it ignores all signals! - except `SIGKILL` and `SIGSTOP` - except signals handled explicitly TL,DR: there are many circumstances when `^C` won't stop the container. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- class: extra-details ## Why is PID 1 special? - PID 1 has some extra responsibilities: - it starts (directly or indirectly) every other process - when a process exits, its processes are "reparented" under PID 1 - When PID 1 exits, everything stops: - on a "regular" machine, it causes a kernel panic - in a container, it kills all the processes - We don't want PID 1 to stop accidentally - That's why it has these extra protections .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## How to stop these containers, then? - Start another terminal and forget about them (for now!) - We'll shortly learn about `docker kill` .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Run a container in the background Containers can be started in the background, with the `-d` flag (daemon mode): ```bash $ docker run -d jpetazzo/clock 47d677dcfba4277c6cc68fcaa51f932b544cab1a187c853b7d0caf4e8debe5ad ``` * We don't see the output of the container. * But don't worry: Docker collects that output and logs it! * Docker gives us the ID of the container. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## List running containers How can we check that our container is still running? With `docker ps`, just like the UNIX `ps` command, lists running processes. ```bash $ docker ps CONTAINER ID IMAGE ... CREATED STATUS ... 47d677dcfba4 jpetazzo/clock ... 2 minutes ago Up 2 minutes ... ``` Docker tells us: * The (truncated) ID of our container. * The image used to start the container. * That our container has been running (`Up`) for a couple of minutes. * Other information (COMMAND, PORTS, NAMES) that we will explain later. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Starting more containers Let's start two more containers. ```bash $ docker run -d jpetazzo/clock 57ad9bdfc06bb4407c47220cf59ce21585dce9a1298d7a67488359aeaea8ae2a ``` ```bash $ docker run -d jpetazzo/clock 068cc994ffd0190bbe025ba74e4c0771a5d8f14734af772ddee8dc1aaf20567d ``` Check that `docker ps` correctly reports all 3 containers. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Viewing only the last container started When many containers are already running, it can be useful to see only the last container that was started. This can be achieved with the `-l` ("Last") flag: ```bash $ docker ps -l CONTAINER ID IMAGE ... CREATED STATUS ... 068cc994ffd0 jpetazzo/clock ... 2 minutes ago Up 2 minutes ... ``` .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## View only the IDs of the containers Many Docker commands will work on container IDs: `docker stop`, `docker rm`... If we want to list only the IDs of our containers (without the other columns or the header line), we can use the `-q` ("Quiet", "Quick") flag: ```bash $ docker ps -q 068cc994ffd0 57ad9bdfc06b 47d677dcfba4 ``` .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Combining flags We can combine `-l` and `-q` to see only the ID of the last container started: ```bash $ docker ps -lq 068cc994ffd0 ``` At a first glance, it looks like this would be particularly useful in scripts. However, if we want to start a container and get its ID in a reliable way, it is better to use `docker run -d`, which we will cover in a bit. (Using `docker ps -lq` is prone to race conditions: what happens if someone else, or another program or script, starts another container just before we run `docker ps -lq`?) .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## View the logs of a container We told you that Docker was logging the container output. Let's see that now. ```bash $ docker logs 068 Fri Feb 20 00:39:52 UTC 2015 Fri Feb 20 00:39:53 UTC 2015 ... ``` * We specified a *prefix* of the full container ID. * You can, of course, specify the full ID. * The `logs` command will output the *entire* logs of the container. <br/>(Sometimes, that will be too much. Let's see how to address that.) .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## View only the tail of the logs To avoid being spammed with eleventy pages of output, we can use the `--tail` option: ```bash $ docker logs --tail 3 068 Fri Feb 20 00:55:35 UTC 2015 Fri Feb 20 00:55:36 UTC 2015 Fri Feb 20 00:55:37 UTC 2015 ``` * The parameter is the number of lines that we want to see. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Follow the logs in real time Just like with the standard UNIX command `tail -f`, we can follow the logs of our container: ```bash $ docker logs --tail 1 --follow 068 Fri Feb 20 00:57:12 UTC 2015 Fri Feb 20 00:57:13 UTC 2015 ^C ``` * This will display the last line in the log file. * Then, it will continue to display the logs in real time. * Use `^C` to exit. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Stop our container There are two ways we can terminate our detached container. * Killing it using the `docker kill` command. * Stopping it using the `docker stop` command. The first one stops the container immediately, by using the `KILL` signal. The second one is more graceful. It sends a `TERM` signal, and after 10 seconds, if the container has not stopped, it sends `KILL.` Reminder: the `KILL` signal cannot be intercepted, and will forcibly terminate the container. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Stopping our containers Let's stop one of those containers: ```bash $ docker stop 47d6 47d6 ``` This will take 10 seconds: * Docker sends the TERM signal; * the container doesn't react to this signal (it's a simple Shell script with no special signal handling); * 10 seconds later, since the container is still running, Docker sends the KILL signal; * this terminates the container. .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## Killing the remaining containers Let's be less patient with the two other containers: ```bash $ docker kill 068 57ad 068 57ad ``` The `stop` and `kill` commands can take multiple container IDs. Those containers will be terminated immediately (without the 10-second delay). Let's check that our containers don't show up anymore: ```bash $ docker ps ``` .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- ## List stopped containers We can also see stopped containers, with the `-a` (`--all`) option. ```bash $ docker ps -a CONTAINER ID IMAGE ... CREATED STATUS 068cc994ffd0 jpetazzo/clock ... 21 min. ago Exited (137) 3 min. ago 57ad9bdfc06b jpetazzo/clock ... 21 min. ago Exited (137) 3 min. ago 47d677dcfba4 jpetazzo/clock ... 23 min. ago Exited (137) 3 min. ago 5c1dfd4d81f1 jpetazzo/clock ... 40 min. ago Exited (0) 40 min. ago b13c164401fb ubuntu ... 55 min. ago Exited (130) 53 min. ago ``` ??? :EN:- Foreground and background containers :FR:- Exécution interactive ou en arrière-plan .debug[[containers/Background_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Background_Containers.md)] --- class: pic .interstitial[] --- name: toc-restarting-and-attaching-to-containers class: title Restarting and attaching to containers .nav[ [Previous part](#toc-background-containers) | [Back to table of contents](#toc-part-1) | [Next part](#toc-understanding-docker-images) ] .debug[(automatically generated title slide)] --- # Restarting and attaching to containers We have started containers in the foreground, and in the background. In this chapter, we will see how to: * Put a container in the background. * Attach to a background container to bring it to the foreground. * Restart a stopped container. .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Background and foreground The distinction between foreground and background containers is arbitrary. From Docker's point of view, all containers are the same. All containers run the same way, whether there is a client attached to them or not. It is always possible to detach from a container, and to reattach to a container. Analogy: attaching to a container is like plugging a keyboard and screen to a physical server. .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Detaching from a container (Linux/macOS) * If you have started an *interactive* container (with option `-it`), you can detach from it. * The "detach" sequence is `^P^Q`. * Otherwise you can detach by killing the Docker client. (But not by hitting `^C`, as this would deliver `SIGINT` to the container.) What does `-it` stand for? * `-t` means "allocate a terminal." * `-i` means "connect stdin to the terminal." .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Detaching cont. (Win PowerShell and cmd.exe) * Docker for Windows has a different detach experience due to shell features. * `^P^Q` does not work. * `^C` will detach, rather than stop the container. * Using Bash, Subsystem for Linux, etc. on Windows behaves like Linux/macOS shells. * Both PowerShell and Bash work well in Win 10; just be aware of differences. .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- class: extra-details ## Specifying a custom detach sequence * You don't like `^P^Q`? No problem! * You can change the sequence with `docker run --detach-keys`. * This can also be passed as a global option to the engine. Start a container with a custom detach command: ```bash $ docker run -ti --detach-keys ctrl-x,x jpetazzo/clock ``` Detach by hitting `^X x`. (This is ctrl-x then x, not ctrl-x twice!) Check that our container is still running: ```bash $ docker ps -l ``` .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- class: extra-details ## Attaching to a container You can attach to a container: ```bash $ docker attach <containerID> ``` * The container must be running. * There *can* be multiple clients attached to the same container. * If you don't specify `--detach-keys` when attaching, it defaults back to `^P^Q`. Try it on our previous container: ```bash $ docker attach $(docker ps -lq) ``` Check that `^X x` doesn't work, but `^P ^Q` does. .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Detaching from non-interactive containers * **Warning:** if the container was started without `-it`... * You won't be able to detach with `^P^Q`. * If you hit `^C`, the signal will be proxied to the container. * Remember: you can always detach by killing the Docker client. .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Checking container output * Use `docker attach` if you intend to send input to the container. * If you just want to see the output of a container, use `docker logs`. ```bash $ docker logs --tail 1 --follow <containerID> ``` .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Restarting a container When a container has exited, it is in stopped state. It can then be restarted with the `start` command. ```bash $ docker start <yourContainerID> ``` The container will be restarted using the same options you launched it with. You can re-attach to it if you want to interact with it: ```bash $ docker attach <yourContainerID> ``` Use `docker ps -a` to identify the container ID of a previous `jpetazzo/clock` container, and try those commands. .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- ## Attaching to a REPL * REPL = Read Eval Print Loop * Shells, interpreters, TUI ... * Symptom: you `docker attach`, and see nothing * The REPL doesn't know that you just attached, and doesn't print anything * Try hitting `^L` or `Enter` .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- class: extra-details ## SIGWINCH * When you `docker attach`, the Docker Engine sends SIGWINCH signals to the container. * SIGWINCH = WINdow CHange; indicates a change in window size. * This will cause some CLI and TUI programs to redraw the screen. * But not all of them. ??? :EN:- Restarting old containers :EN:- Detaching and reattaching to container :FR:- Redémarrer des anciens conteneurs :FR:- Se détacher et rattacher à des conteneurs .debug[[containers/Start_And_Attach.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Start_And_Attach.md)] --- class: pic .interstitial[] --- name: toc-understanding-docker-images class: title Understanding Docker images .nav[ [Previous part](#toc-restarting-and-attaching-to-containers) | [Back to table of contents](#toc-part-2) | [Next part](#toc-building-images-interactively) ] .debug[(automatically generated title slide)] --- class: title # Understanding Docker images  .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Objectives In this section, we will explain: * What is an image. * What is a layer. * The various image namespaces. * How to search and download images. * Image tags and when to use them. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## What is an image? * Image = files + metadata * These files form the root filesystem of our container. * The metadata can indicate a number of things, e.g.: * the author of the image * the command to execute in the container when starting it * environment variables to be set * etc. * Images are made of *layers*, conceptually stacked on top of each other. * Each layer can add, change, and remove files and/or metadata. * Images can share layers to optimize disk usage, transfer times, and memory use. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Example for a Java webapp Each of the following items will correspond to one layer: * CentOS base layer * Packages and configuration files added by our local IT * JRE * Tomcat * Our application's dependencies * Our application code and assets * Our application configuration (Note: app config is generally added by orchestration facilities.) .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- class: pic ## The read-write layer  .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Differences between containers and images * An image is a read-only filesystem. * A container is an encapsulated set of processes, running in a read-write copy of that filesystem. * To optimize container boot time, *copy-on-write* is used instead of regular copy. * `docker run` starts a container from a given image. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- class: pic ## Multiple containers sharing the same image 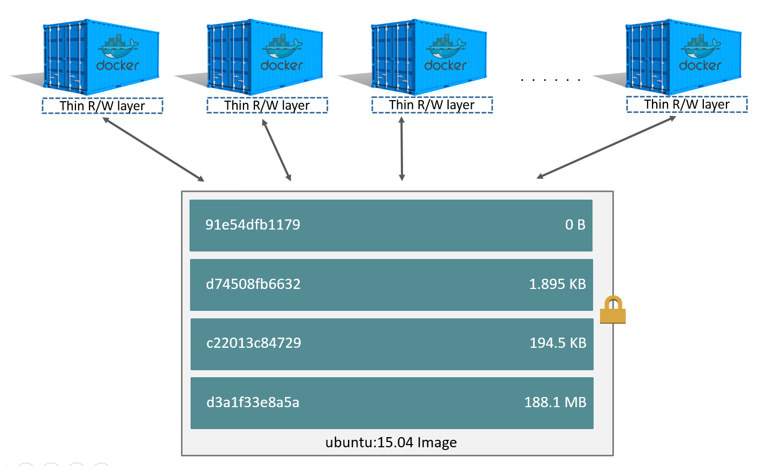 .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Comparison with object-oriented programming * Images are conceptually similar to *classes*. * Layers are conceptually similar to *inheritance*. * Containers are conceptually similar to *instances*. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Wait a minute... If an image is read-only, how do we change it? * We don't. * We create a new container from that image. * Then we make changes to that container. * When we are satisfied with those changes, we transform them into a new layer. * A new image is created by stacking the new layer on top of the old image. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## A chicken-and-egg problem * The only way to create an image is by "freezing" a container. * The only way to create a container is by instantiating an image. * Help! .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Creating the first images There is a special empty image called `scratch`. * It allows to *build from scratch*. The `docker import` command loads a tarball into Docker. * The imported tarball becomes a standalone image. * That new image has a single layer. Note: you will probably never have to do this yourself. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Creating other images `docker commit` * Saves all the changes made to a container into a new layer. * Creates a new image (effectively a copy of the container). `docker build` **(used 99% of the time)** * Performs a repeatable build sequence. * This is the preferred method! We will explain both methods in a moment. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Images namespaces There are three namespaces: * Official images e.g. `ubuntu`, `busybox` ... * User (and organizations) images e.g. `jpetazzo/clock` * Self-hosted images e.g. `registry.example.com:5000/my-private/image` Let's explain each of them. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Root namespace The root namespace is for official images. They are gated by Docker Inc. They are generally authored and maintained by third parties. Those images include: * Small, "swiss-army-knife" images like busybox. * Distro images to be used as bases for your builds, like ubuntu, fedora... * Ready-to-use components and services, like redis, postgresql... * Over 150 at this point! .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## User namespace The user namespace holds images for Docker Hub users and organizations. For example: ```bash jpetazzo/clock ``` The Docker Hub user is: ```bash jpetazzo ``` The image name is: ```bash clock ``` .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Self-hosted namespace This namespace holds images which are not hosted on Docker Hub, but on third party registries. They contain the hostname (or IP address), and optionally the port, of the registry server. For example: ```bash localhost:5000/wordpress ``` * `localhost:5000` is the host and port of the registry * `wordpress` is the name of the image Other examples: ```bash quay.io/coreos/etcd gcr.io/google-containers/hugo ``` .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## How do you store and manage images? Images can be stored: * On your Docker host. * In a Docker registry. You can use the Docker client to download (pull) or upload (push) images. To be more accurate: you can use the Docker client to tell a Docker Engine to push and pull images to and from a registry. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Showing current images Let's look at what images are on our host now. ```bash $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE fedora latest ddd5c9c1d0f2 3 days ago 204.7 MB centos latest d0e7f81ca65c 3 days ago 196.6 MB ubuntu latest 07c86167cdc4 4 days ago 188 MB redis latest 4f5f397d4b7c 5 days ago 177.6 MB postgres latest afe2b5e1859b 5 days ago 264.5 MB alpine latest 70c557e50ed6 5 days ago 4.798 MB debian latest f50f9524513f 6 days ago 125.1 MB busybox latest 3240943c9ea3 2 weeks ago 1.114 MB training/namer latest 902673acc741 9 months ago 289.3 MB jpetazzo/clock latest 12068b93616f 12 months ago 2.433 MB ``` .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Searching for images We cannot list *all* images on a remote registry, but we can search for a specific keyword: ```bash $ docker search marathon NAME DESCRIPTION STARS OFFICIAL AUTOMATED mesosphere/marathon A cluster-wide init and co... 105 [OK] mesoscloud/marathon Marathon 31 [OK] mesosphere/marathon-lb Script to update haproxy b... 22 [OK] tobilg/mongodb-marathon A Docker image to start a ... 4 [OK] ``` * "Stars" indicate the popularity of the image. * "Official" images are those in the root namespace. * "Automated" images are built automatically by the Docker Hub. <br/>(This means that their build recipe is always available.) .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Downloading images There are two ways to download images. * Explicitly, with `docker pull`. * Implicitly, when executing `docker run` and the image is not found locally. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Pulling an image ```bash $ docker pull debian:jessie Pulling repository debian b164861940b8: Download complete b164861940b8: Pulling image (jessie) from debian d1881793a057: Download complete ``` * As seen previously, images are made up of layers. * Docker has downloaded all the necessary layers. * In this example, `:jessie` indicates which exact version of Debian we would like. It is a *version tag*. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Image and tags * Images can have tags. * Tags define image versions or variants. * `docker pull ubuntu` will refer to `ubuntu:latest`. * The `:latest` tag is generally updated often. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## When to (not) use tags Don't specify tags: * When doing rapid testing and prototyping. * When experimenting. * When you want the latest version. Do specify tags: * When recording a procedure into a script. * When going to production. * To ensure that the same version will be used everywhere. * To ensure repeatability later. This is similar to what we would do with `pip install`, `npm install`, etc. .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- class: extra-details ## Multi-arch images - An image can support multiple architectures - More precisely, a specific *tag* in a given *repository* can have either: - a single *manifest* referencing an image for a single architecture - a *manifest list* (or *fat manifest*) referencing multiple images - In a *manifest list*, each image is identified by a combination of: - `os` (linux, windows) - `architecture` (amd64, arm, arm64...) - optional fields like `variant` (for arm and arm64), `os.version` (for windows) .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- class: extra-details ## Working with multi-arch images - The Docker Engine will pull "native" images when available (images matching its own os/architecture/variant) - We can ask for a specific image platform with `--platform` - The Docker Engine can run non-native images thanks to QEMU+binfmt (automatically on Docker Desktop; with a bit of setup on Linux) .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- ## Section summary We've learned how to: * Understand images and layers. * Understand Docker image namespacing. * Search and download images. ??? :EN:Building images :EN:- Containers, images, and layers :EN:- Image addresses and tags :EN:- Finding and transferring images :FR:Construire des images :FR:- La différence entre un conteneur et une image :FR:- La notion de *layer* partagé entre images .debug[[containers/Initial_Images.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Initial_Images.md)] --- class: pic .interstitial[] --- name: toc-building-images-interactively class: title Building images interactively .nav[ [Previous part](#toc-understanding-docker-images) | [Back to table of contents](#toc-part-2) | [Next part](#toc-building-docker-images-with-a-dockerfile) ] .debug[(automatically generated title slide)] --- # Building images interactively In this section, we will create our first container image. It will be a basic distribution image, but we will pre-install the package `figlet`. We will: * Create a container from a base image. * Install software manually in the container, and turn it into a new image. * Learn about new commands: `docker commit`, `docker tag`, and `docker diff`. .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## The plan 1. Create a container (with `docker run`) using our base distro of choice. 2. Run a bunch of commands to install and set up our software in the container. 3. (Optionally) review changes in the container with `docker diff`. 4. Turn the container into a new image with `docker commit`. 5. (Optionally) add tags to the image with `docker tag`. .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## Setting up our container Start an Ubuntu container: ```bash $ docker run -it ubuntu root@<yourContainerId>:#/ ``` Run the command `apt-get update` to refresh the list of packages available to install. Then run the command `apt-get install figlet` to install the program we are interested in. ```bash root@<yourContainerId>:#/ apt-get update && apt-get install figlet .... OUTPUT OF APT-GET COMMANDS .... ``` .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## Inspect the changes Type `exit` at the container prompt to leave the interactive session. Now let's run `docker diff` to see the difference between the base image and our container. ```bash $ docker diff <yourContainerId> C /root A /root/.bash_history C /tmp C /usr C /usr/bin A /usr/bin/figlet ... ``` .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- class: x-extra-details ## Docker tracks filesystem changes As explained before: * An image is read-only. * When we make changes, they happen in a copy of the image. * Docker can show the difference between the image, and its copy. * For performance, Docker uses copy-on-write systems. <br/>(i.e. starting a container based on a big image doesn't incur a huge copy.) .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## Copy-on-write security benefits * `docker diff` gives us an easy way to audit changes (à la Tripwire) * Containers can also be started in read-only mode (their root filesystem will be read-only, but they can still have read-write data volumes) .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## Commit our changes into a new image The `docker commit` command will create a new layer with those changes, and a new image using this new layer. ```bash $ docker commit <yourContainerId> <newImageId> ``` The output of the `docker commit` command will be the ID for your newly created image. We can use it as an argument to `docker run`. .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## Testing our new image Let's run this image: ```bash $ docker run -it <newImageId> root@fcfb62f0bfde:/# figlet hello _ _ _ | |__ ___| | | ___ | '_ \ / _ \ | |/ _ \ | | | | __/ | | (_) | |_| |_|\___|_|_|\___/ ``` It works! 🎉 .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## Tagging images Referring to an image by its ID is not convenient. Let's tag it instead. We can use the `tag` command: ```bash $ docker tag <newImageId> figlet ``` But we can also specify the tag as an extra argument to `commit`: ```bash $ docker commit <containerId> figlet ``` And then run it using its tag: ```bash $ docker run -it figlet ``` .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- ## What's next? Manual process = bad. Automated process = good. In the next chapter, we will learn how to automate the build process by writing a `Dockerfile`. ??? :EN:- Building our first images interactively :FR:- Fabriquer nos premières images à la main .debug[[containers/Building_Images_Interactively.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_Interactively.md)] --- class: pic .interstitial[] --- name: toc-building-docker-images-with-a-dockerfile class: title Building Docker images with a Dockerfile .nav[ [Previous part](#toc-building-images-interactively) | [Back to table of contents](#toc-part-2) | [Next part](#toc-cmd-and-entrypoint) ] .debug[(automatically generated title slide)] --- class: title # Building Docker images with a Dockerfile  .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Objectives We will build a container image automatically, with a `Dockerfile`. At the end of this lesson, you will be able to: * Write a `Dockerfile`. * Build an image from a `Dockerfile`. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## `Dockerfile` overview * A `Dockerfile` is a build recipe for a Docker image. * It contains a series of instructions telling Docker how an image is constructed. * The `docker build` command builds an image from a `Dockerfile`. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## `Dockerfile` example ``` FROM python:alpine WORKDIR /app RUN pip install Flask COPY rng.py . ENV FLASK_APP=rng FLASK_RUN_HOST=:: FLASK_RUN_PORT=80 CMD ["flask", "run"] EXPOSE 80 ``` .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Writing our first `Dockerfile` Our Dockerfile must be in a **new, empty directory**. 1. Create a directory to hold our `Dockerfile`. ```bash $ mkdir myimage ``` 2. Create a `Dockerfile` inside this directory. ```bash $ cd myimage $ vim Dockerfile ``` Of course, you can use any other editor of your choice. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Type this into our Dockerfile... ```dockerfile FROM ubuntu RUN apt-get update RUN apt-get install figlet ``` * `FROM` indicates the base image for our build. * Each `RUN` line will be executed by Docker during the build. * Our `RUN` commands **must be non-interactive.** <br/>(No input can be provided to Docker during the build.) * In many cases, we will add the `-y` flag to `apt-get`. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Build it! Save our file, then execute: ```bash $ docker build -t figlet . ``` * `-t` indicates the tag to apply to the image. * `.` indicates the location of the *build context*. We will talk more about the build context later. To keep things simple for now: this is the directory where our Dockerfile is located. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## What happens when we build the image? It depends if we're using BuildKit or not! If there are lots of blue lines and the first line looks like this: ``` [+] Building 1.8s (4/6) ``` ... then we're using BuildKit. If the output is mostly black-and-white and the first line looks like this: ``` Sending build context to Docker daemon 2.048kB ``` ... then we're using the "classic" or "old-style" builder. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## To BuildKit or Not To BuildKit Classic builder: - copies the whole "build context" to the Docker Engine - linear (processes lines one after the other) - requires a full Docker Engine BuildKit: - only transfers parts of the "build context" when needed - will parallelize operations (when possible) - can run in non-privileged containers (e.g. on Kubernetes) .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## With the classic builder The output of `docker build` looks like this: .small[ ```bash docker build -t figlet . Sending build context to Docker daemon 2.048kB Step 1/3 : FROM ubuntu ---> f975c5035748 Step 2/3 : RUN apt-get update ---> Running in e01b294dbffd (...output of the RUN command...) Removing intermediate container e01b294dbffd ---> eb8d9b561b37 Step 3/3 : RUN apt-get install figlet ---> Running in c29230d70f9b (...output of the RUN command...) Removing intermediate container c29230d70f9b ---> 0dfd7a253f21 Successfully built 0dfd7a253f21 Successfully tagged figlet:latest ``` ] * The output of the `RUN` commands has been omitted. * Let's explain what this output means. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Sending the build context to Docker ```bash Sending build context to Docker daemon 2.048 kB ``` * The build context is the `.` directory given to `docker build`. * It is sent (as an archive) by the Docker client to the Docker daemon. * This allows to use a remote machine to build using local files. * Be careful (or patient) if that directory is big and your link is slow. * You can speed up the process with a [`.dockerignore`](https://docs.docker.com/engine/reference/builder/#dockerignore-file) file * It tells docker to ignore specific files in the directory * Only ignore files that you won't need in the build context! .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Executing each step ```bash Step 2/3 : RUN apt-get update ---> Running in e01b294dbffd (...output of the RUN command...) Removing intermediate container e01b294dbffd ---> eb8d9b561b37 ``` * A container (`e01b294dbffd`) is created from the base image. * The `RUN` command is executed in this container. * The container is committed into an image (`eb8d9b561b37`). * The build container (`e01b294dbffd`) is removed. * The output of this step will be the base image for the next one. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## With BuildKit .small[ ```bash [+] Building 7.9s (7/7) FINISHED => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 98B 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load metadata for docker.io/library/ubuntu:latest 1.2s => [1/3] FROM docker.io/library/ubuntu@sha256:cf31af331f38d1d7158470e095b132acd126a7180a54f263d386 3.2s => => resolve docker.io/library/ubuntu@sha256:cf31af331f38d1d7158470e095b132acd126a7180a54f263d386 0.0s => => sha256:cf31af331f38d1d7158470e095b132acd126a7180a54f263d386da88eb681d93 1.20kB / 1.20kB 0.0s => => sha256:1de4c5e2d8954bf5fa9855f8b4c9d3c3b97d1d380efe19f60f3e4107a66f5cae 943B / 943B 0.0s => => sha256:6a98cbe39225dadebcaa04e21dbe5900ad604739b07a9fa351dd10a6ebad4c1b 3.31kB / 3.31kB 0.0s => => sha256:80bc30679ac1fd798f3241208c14accd6a364cb8a6224d1127dfb1577d10554f 27.14MB / 27.14MB 2.3s => => sha256:9bf18fab4cfbf479fa9f8409ad47e2702c63241304c2cdd4c33f2a1633c5f85e 850B / 850B 0.5s => => sha256:5979309c983a2adeff352538937475cf961d49c34194fa2aab142effe19ed9c1 189B / 189B 0.4s => => extracting sha256:80bc30679ac1fd798f3241208c14accd6a364cb8a6224d1127dfb1577d10554f 0.7s => => extracting sha256:9bf18fab4cfbf479fa9f8409ad47e2702c63241304c2cdd4c33f2a1633c5f85e 0.0s => => extracting sha256:5979309c983a2adeff352538937475cf961d49c34194fa2aab142effe19ed9c1 0.0s => [2/3] RUN apt-get update 2.5s => [3/3] RUN apt-get install figlet 0.9s => exporting to image 0.1s => => exporting layers 0.1s => => writing image sha256:3b8aee7b444ab775975dfba691a72d8ac24af2756e0a024e056e3858d5a23f7c 0.0s => => naming to docker.io/library/figlet 0.0s ``` ] .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Understanding BuildKit output - BuildKit transfers the Dockerfile and the *build context* (these are the first two `[internal]` stages) - Then it executes the steps defined in the Dockerfile (`[1/3]`, `[2/3]`, `[3/3]`) - Finally, it exports the result of the build (image definition + collection of layers) .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- class: extra-details ## BuildKit plain output - When running BuildKit in e.g. a CI pipeline, its output will be different - We can see the same output format by using `--progress=plain` .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## The caching system If you run the same build again, it will be instantaneous. Why? * After each build step, Docker takes a snapshot of the resulting image. * Before executing a step, Docker checks if it has already built the same sequence. * Docker uses the exact strings defined in your Dockerfile, so: * `RUN apt-get install figlet cowsay` <br/> is different from <br/> `RUN apt-get install cowsay figlet` * `RUN apt-get update` is not re-executed when the mirrors are updated You can force a rebuild with `docker build --no-cache ...`. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Running the image The resulting image is not different from the one produced manually. ```bash $ docker run -ti figlet root@91f3c974c9a1:/# figlet hello _ _ _ | |__ ___| | | ___ | '_ \ / _ \ | |/ _ \ | | | | __/ | | (_) | |_| |_|\___|_|_|\___/ ``` Yay! 🎉 .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Using image and viewing history The `history` command lists all the layers composing an image. For each layer, it shows its creation time, size, and creation command. When an image was built with a Dockerfile, each layer corresponds to a line of the Dockerfile. ```bash $ docker history figlet IMAGE CREATED CREATED BY SIZE f9e8f1642759 About an hour ago /bin/sh -c apt-get install fi 1.627 MB 7257c37726a1 About an hour ago /bin/sh -c apt-get update 21.58 MB 07c86167cdc4 4 days ago /bin/sh -c #(nop) CMD ["/bin 0 B <missing> 4 days ago /bin/sh -c sed -i 's/^#\s*\( 1.895 kB <missing> 4 days ago /bin/sh -c echo '#!/bin/sh' 194.5 kB <missing> 4 days ago /bin/sh -c #(nop) ADD file:b 187.8 MB ``` .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- class: extra-details ## Why `sh -c`? * On UNIX, to start a new program, we need two system calls: - `fork()`, to create a new child process; - `execve()`, to replace the new child process with the program to run. * Conceptually, `execve()` works like this: `execve(program, [list, of, arguments])` * When we run a command, e.g. `ls -l /tmp`, something needs to parse the command. (i.e. split the program and its arguments into a list.) * The shell is usually doing that. (It also takes care of expanding environment variables and special things like `~`.) .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- class: extra-details ## Why `sh -c`? * When we do `RUN ls -l /tmp`, the Docker builder needs to parse the command. * Instead of implementing its own parser, it outsources the job to the shell. * That's why we see `sh -c ls -l /tmp` in that case. * But we can also do the parsing jobs ourselves. * This means passing `RUN` a list of arguments. * This is called the *exec syntax*. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Shell syntax vs exec syntax Dockerfile commands that execute something can have two forms: * plain string, or *shell syntax*: <br/>`RUN apt-get install figlet` * JSON list, or *exec syntax*: <br/>`RUN ["apt-get", "install", "figlet"]` We are going to change our Dockerfile to see how it affects the resulting image. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Using exec syntax in our Dockerfile Let's change our Dockerfile as follows! ```dockerfile FROM ubuntu RUN apt-get update RUN ["apt-get", "install", "figlet"] ``` Then build the new Dockerfile. ```bash $ docker build -t figlet . ``` .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## History with exec syntax Compare the new history: ```bash $ docker history figlet IMAGE CREATED CREATED BY SIZE 27954bb5faaf 10 seconds ago apt-get install figlet 1.627 MB 7257c37726a1 About an hour ago /bin/sh -c apt-get update 21.58 MB 07c86167cdc4 4 days ago /bin/sh -c #(nop) CMD ["/bin 0 B <missing> 4 days ago /bin/sh -c sed -i 's/^#\s*\( 1.895 kB <missing> 4 days ago /bin/sh -c echo '#!/bin/sh' 194.5 kB <missing> 4 days ago /bin/sh -c #(nop) ADD file:b 187.8 MB ``` * Exec syntax specifies an *exact* command to execute. * Shell syntax specifies a command to be wrapped within `/bin/sh -c "..."`. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## When to use exec syntax and shell syntax * shell syntax: * is easier to write * interpolates environment variables and other shell expressions * creates an extra process (`/bin/sh -c ...`) to parse the string * requires `/bin/sh` to exist in the container * exec syntax: * is harder to write (and read!) * passes all arguments without extra processing * doesn't create an extra process * doesn't require `/bin/sh` to exist in the container .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Pro-tip: the `exec` shell built-in POSIX shells have a built-in command named `exec`. `exec` should be followed by a program and its arguments. From a user perspective: - it looks like the shell exits right away after the command execution, - in fact, the shell exits just *before* command execution; - or rather, the shell gets *replaced* by the command. .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- ## Example using `exec` ```dockerfile CMD exec figlet -f script hello ``` In this example, `sh -c` will still be used, but `figlet` will be PID 1 in the container. The shell gets replaced by `figlet` when `figlet` starts execution. This allows to run processes as PID 1 without using JSON. ??? :EN:- Towards automated, reproducible builds :EN:- Writing our first Dockerfile :FR:- Rendre le processus automatique et reproductible :FR:- Écrire son premier Dockerfile .debug[[containers/Building_Images_With_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Building_Images_With_Dockerfiles.md)] --- class: pic .interstitial[] --- name: toc-cmd-and-entrypoint class: title `CMD` and `ENTRYPOINT` .nav[ [Previous part](#toc-building-docker-images-with-a-dockerfile) | [Back to table of contents](#toc-part-2) | [Next part](#toc-copying-files-during-the-build) ] .debug[(automatically generated title slide)] --- class: title # `CMD` and `ENTRYPOINT`  .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Objectives In this lesson, we will learn about two important Dockerfile commands: `CMD` and `ENTRYPOINT`. These commands allow us to set the default command to run in a container. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Defining a default command When people run our container, we want to greet them with a nice hello message, and using a custom font. For that, we will execute: ```bash figlet -f script hello ``` * `-f script` tells figlet to use a fancy font. * `hello` is the message that we want it to display. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Adding `CMD` to our Dockerfile Our new Dockerfile will look like this: ```dockerfile FROM ubuntu RUN apt-get update RUN ["apt-get", "install", "figlet"] CMD figlet -f script hello ``` * `CMD` defines a default command to run when none is given. * It can appear at any point in the file. * Each `CMD` will replace and override the previous one. * As a result, while you can have multiple `CMD` lines, it is useless. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Build and test our image Let's build it: ```bash $ docker build -t figlet . ... Successfully built 042dff3b4a8d Successfully tagged figlet:latest ``` And run it: ```bash $ docker run figlet _ _ _ | | | | | | | | _ | | | | __ |/ \ |/ |/ |/ / \_ | |_/|__/|__/|__/\__/ ``` .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Overriding `CMD` If we want to get a shell into our container (instead of running `figlet`), we just have to specify a different program to run: ```bash $ docker run -it figlet bash root@7ac86a641116:/# ``` * We specified `bash`. * It replaced the value of `CMD`. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Using `ENTRYPOINT` We want to be able to specify a different message on the command line, while retaining `figlet` and some default parameters. In other words, we would like to be able to do this: ```bash $ docker run figlet salut _ | | , __, | | _|_ / \_/ | |/ | | | \/ \_/|_/|__/ \_/|_/|_/ ``` We will use the `ENTRYPOINT` verb in Dockerfile. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Adding `ENTRYPOINT` to our Dockerfile Our new Dockerfile will look like this: ```dockerfile FROM ubuntu RUN apt-get update RUN ["apt-get", "install", "figlet"] ENTRYPOINT ["figlet", "-f", "script"] ``` * `ENTRYPOINT` defines a base command (and its parameters) for the container. * The command line arguments are appended to those parameters. * Like `CMD`, `ENTRYPOINT` can appear anywhere, and replaces the previous value. Why did we use JSON syntax for our `ENTRYPOINT`? .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Implications of JSON vs string syntax * When CMD or ENTRYPOINT use string syntax, they get wrapped in `sh -c`. * To avoid this wrapping, we can use JSON syntax. What if we used `ENTRYPOINT` with string syntax? ```bash $ docker run figlet salut ``` This would run the following command in the `figlet` image: ```bash sh -c "figlet -f script" salut ``` .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Build and test our image Let's build it: ```bash $ docker build -t figlet . ... Successfully built 36f588918d73 Successfully tagged figlet:latest ``` And run it: ```bash $ docker run figlet salut _ | | , __, | | _|_ / \_/ | |/ | | | \/ \_/|_/|__/ \_/|_/|_/ ``` .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Using `CMD` and `ENTRYPOINT` together What if we want to define a default message for our container? Then we will use `ENTRYPOINT` and `CMD` together. * `ENTRYPOINT` will define the base command for our container. * `CMD` will define the default parameter(s) for this command. * They *both* have to use JSON syntax. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## `CMD` and `ENTRYPOINT` together Our new Dockerfile will look like this: ```dockerfile FROM ubuntu RUN apt-get update RUN ["apt-get", "install", "figlet"] ENTRYPOINT ["figlet", "-f", "script"] CMD ["hello world"] ``` * `ENTRYPOINT` defines a base command (and its parameters) for the container. * If we don't specify extra command-line arguments when starting the container, the value of `CMD` is appended. * Otherwise, our extra command-line arguments are used instead of `CMD`. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Build and test our image Let's build it: ```bash $ docker build -t myfiglet . ... Successfully built 6e0b6a048a07 Successfully tagged myfiglet:latest ``` Run it without parameters: ```bash $ docker run myfiglet _ _ _ _ | | | | | | | | | | | _ | | | | __ __ ,_ | | __| |/ \ |/ |/ |/ / \_ | | |_/ \_/ | |/ / | | |_/|__/|__/|__/\__/ \/ \/ \__/ |_/|__/\_/|_/ ``` .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Overriding the image default parameters Now let's pass extra arguments to the image. ```bash $ docker run myfiglet hola mundo _ _ | | | | | | | __ | | __, _ _ _ _ _ __| __ |/ \ / \_|/ / | / |/ |/ | | | / |/ | / | / \_ | |_/\__/ |__/\_/|_/ | | |_/ \_/|_/ | |_/\_/|_/\__/ ``` We overrode `CMD` but still used `ENTRYPOINT`. .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## Overriding `ENTRYPOINT` What if we want to run a shell in our container? We cannot just do `docker run myfiglet bash` because that would just tell figlet to display the word "bash." We use the `--entrypoint` parameter: ```bash $ docker run -it --entrypoint bash myfiglet root@6027e44e2955:/# ``` .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## `CMD` and `ENTRYPOINT` recap - `docker run myimage` executes `ENTRYPOINT` + `CMD` - `docker run myimage args` executes `ENTRYPOINT` + `args` (overriding `CMD`) - `docker run --entrypoint prog myimage` executes `prog` (overriding both) .small[ | Command | `ENTRYPOINT` | `CMD` | Result |---------------------------------|--------------------|---------|------- | `docker run figlet` | none | none | Use values from base image (`bash`) | `docker run figlet hola` | none | none | Error (executable `hola` not found) | `docker run figlet` | `figlet -f script` | none | `figlet -f script` | `docker run figlet hola` | `figlet -f script` | none | `figlet -f script hola` | `docker run figlet` | none | `figlet -f script` | `figlet -f script` | `docker run figlet hola` | none | `figlet -f script` | Error (executable `hola` not found) | `docker run figlet` | `figlet -f script` | `hello` | `figlet -f script hello` | `docker run figlet hola` | `figlet -f script` | `hello` | `figlet -f script hola` ] .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- ## When to use `ENTRYPOINT` vs `CMD` `ENTRYPOINT` is great for "containerized binaries". Example: `docker run consul --help` (Pretend that the `docker run` part isn't there!) `CMD` is great for images with multiple binaries. Example: `docker run busybox ifconfig` (It makes sense to indicate *which* program we want to run!) ??? :EN:- CMD and ENTRYPOINT :FR:- CMD et ENTRYPOINT .debug[[containers/Cmd_And_Entrypoint.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Cmd_And_Entrypoint.md)] --- class: pic .interstitial[] --- name: toc-copying-files-during-the-build class: title Copying files during the build .nav[ [Previous part](#toc-cmd-and-entrypoint) | [Back to table of contents](#toc-part-2) | [Next part](#toc-exercise--writing-dockerfiles) ] .debug[(automatically generated title slide)] --- class: title # Copying files during the build  .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- ## Objectives So far, we have installed things in our container images by downloading packages. We can also copy files from the *build context* to the container that we are building. Remember: the *build context* is the directory containing the Dockerfile. In this chapter, we will learn a new Dockerfile keyword: `COPY`. .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- ## Build some C code We want to build a container that compiles a basic "Hello world" program in C. Here is the program, `hello.c`: ```bash int main () { puts("Hello, world!"); return 0; } ``` Let's create a new directory, and put this file in there. Then we will write the Dockerfile. .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- ## The Dockerfile On Debian and Ubuntu, the package `build-essential` will get us a compiler. When installing it, don't forget to specify the `-y` flag, otherwise the build will fail (since the build cannot be interactive). Then we will use `COPY` to place the source file into the container. ```bash FROM ubuntu RUN apt-get update RUN apt-get install -y build-essential COPY hello.c / RUN make hello CMD /hello ``` Create this Dockerfile. .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- ## Testing our C program * Create `hello.c` and `Dockerfile` in the same directory. * Run `docker build -t hello .` in this directory. * Run `docker run hello`, you should see `Hello, world!`. Success! .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- ## `COPY` and the build cache * Run the build again. * Now, modify `hello.c` and run the build again. * Docker can cache steps involving `COPY`. * Those steps will not be executed again if the files haven't been changed. .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- ## Details * We can `COPY` whole directories recursively * It is possible to do e.g. `COPY . .` (but it might require some extra precautions to avoid copying too much) * In older Dockerfiles, you might see the `ADD` command; consider it deprecated (it is similar to `COPY` but can automatically extract archives) * If we really wanted to compile C code in a container, we would: * place it in a different directory, with the `WORKDIR` instruction * even better, use the `gcc` official image .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- class: extra-details ## `.dockerignore` - We can create a file named `.dockerignore` (at the top-level of the build context) - It can contain file names and globs to ignore - They won't be sent to the builder (and won't end up in the resulting image) - See the [documentation][dockerignore] for the little details (exceptions can be made with `!`, multiple directory levels with `**`...) [dockerignore]: https://docs.docker.com/engine/reference/builder/#dockerignore-file ??? :EN:- Leveraging the build cache for faster builds :FR:- Tirer parti du cache afin d'optimiser la vitesse de *build* .debug[[containers/Copying_Files_During_Build.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copying_Files_During_Build.md)] --- class: pic .interstitial[] --- name: toc-exercise--writing-dockerfiles class: title Exercise — writing Dockerfiles .nav[ [Previous part](#toc-copying-files-during-the-build) | [Back to table of contents](#toc-part-2) | [Next part](#toc-reducing-image-size) ] .debug[(automatically generated title slide)] --- # Exercise — writing Dockerfiles Let's write Dockerfiles for an existing application! 1. Check out the code repository 2. Read all the instructions 3. Write Dockerfiles 4. Build and test them individually <!-- 5. Test them together with the provided Compose file --> .debug[[containers/Exercise_Dockerfile_Basic.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Dockerfile_Basic.md)] --- ## Code repository Clone the repository available at: https://github.com/jpetazzo/wordsmith It should look like this: ``` ├── LICENSE ├── README ├── db/ │ └── words.sql ├── web/ │ ├── dispatcher.go │ └── static/ └── words/ ├── pom.xml └── src/ ``` .debug[[containers/Exercise_Dockerfile_Basic.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Dockerfile_Basic.md)] --- ## Instructions The repository contains instructions in English and French. <br/> For now, we only care about the first part (about writing Dockerfiles). <br/> Place each Dockerfile in its own directory, like this: ``` ├── LICENSE ├── README ├── db/ │ ├── `Dockerfile` │ └── words.sql ├── web/ │ ├── `Dockerfile` │ ├── dispatcher.go │ └── static/ └── words/ ├── `Dockerfile` ├── pom.xml └── src/ ``` .debug[[containers/Exercise_Dockerfile_Basic.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Dockerfile_Basic.md)] --- ## Build and test Build and run each Dockerfile individually. For `db`, we should be able to see some messages confirming that the data set was loaded successfully (some `INSERT` lines in the container output). For `web` and `words`, we should be able to see some message looking like "server started successfully". That's all we care about for now! Bonus question: make sure that each container stops correctly when hitting Ctrl-C. ??? ## Test with a Compose file Place the following Compose file at the root of the repository: ```yaml version: "3" services: db: build: db words: build: words web: build: web ports: - 8888:80 ``` Test the whole app by bringin up the stack and connecting to port 8888. .debug[[containers/Exercise_Dockerfile_Basic.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Dockerfile_Basic.md)] --- class: pic .interstitial[] --- name: toc-reducing-image-size class: title Reducing image size .nav[ [Previous part](#toc-exercise--writing-dockerfiles) | [Back to table of contents](#toc-part-3) | [Next part](#toc-multi-stage-builds) ] .debug[(automatically generated title slide)] --- # Reducing image size * In the previous example, our final image contained: * our `hello` program * its source code * the compiler * Only the first one is strictly necessary. * We are going to see how to obtain an image without the superfluous components. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Can't we remove superfluous files with `RUN`? What happens if we do one of the following commands? - `RUN rm -rf ...` - `RUN apt-get remove ...` - `RUN make clean ...` -- This adds a layer which removes a bunch of files. But the previous layers (which added the files) still exist. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Removing files with an extra layer When downloading an image, all the layers must be downloaded. | Dockerfile instruction | Layer size | Image size | | ---------------------- | ---------- | ---------- | | `FROM ubuntu` | Size of base image | Size of base image | | `...` | ... | Sum of this layer <br/>+ all previous ones | | `RUN apt-get install somepackage` | Size of files added <br/>(e.g. a few MB) | Sum of this layer <br/>+ all previous ones | | `...` | ... | Sum of this layer <br/>+ all previous ones | | `RUN apt-get remove somepackage` | Almost zero <br/>(just metadata) | Same as previous one | Therefore, `RUN rm` does not reduce the size of the image or free up disk space. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Removing unnecessary files Various techniques are available to obtain smaller images: - collapsing layers, - adding binaries that are built outside of the Dockerfile, - squashing the final image, - multi-stage builds. Let's review them quickly. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Collapsing layers You will frequently see Dockerfiles like this: ```dockerfile FROM ubuntu RUN apt-get update && apt-get install xxx && ... && apt-get remove xxx && ... ``` Or the (more readable) variant: ```dockerfile FROM ubuntu RUN apt-get update \ && apt-get install xxx \ && ... \ && apt-get remove xxx \ && ... ``` This `RUN` command gives us a single layer. The files that are added, then removed in the same layer, do not grow the layer size. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Collapsing layers: pros and cons Pros: - works on all versions of Docker - doesn't require extra tools Cons: - not very readable - some unnecessary files might still remain if the cleanup is not thorough - that layer is expensive (slow to build) .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Building binaries outside of the Dockerfile This results in a Dockerfile looking like this: ```dockerfile FROM ubuntu COPY xxx /usr/local/bin ``` Of course, this implies that the file `xxx` exists in the build context. That file has to exist before you can run `docker build`. For instance, it can: - exist in the code repository, - be created by another tool (script, Makefile...), - be created by another container image and extracted from the image. See for instance the [busybox official image](https://github.com/docker-library/busybox/blob/fe634680e32659aaf0ee0594805f74f332619a90/musl/Dockerfile) or this [older busybox image](https://github.com/jpetazzo/docker-busybox). .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Building binaries outside: pros and cons Pros: - final image can be very small Cons: - requires an extra build tool - we're back in dependency hell and "works on my machine" Cons, if binary is added to code repository: - breaks portability across different platforms - grows repository size a lot if the binary is updated frequently .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Squashing the final image The idea is to transform the final image into a single-layer image. This can be done in (at least) two ways. - Activate experimental features and squash the final image: ```bash docker image build --squash ... ``` - Export/import the final image. ```bash docker build -t temp-image . docker run --entrypoint true --name temp-container temp-image docker export temp-container | docker import - final-image docker rm temp-container docker rmi temp-image ``` .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Squashing the image: pros and cons Pros: - single-layer images are smaller and faster to download - removed files no longer take up storage and network resources Cons: - we still need to actively remove unnecessary files - squash operation can take a lot of time (on big images) - squash operation does not benefit from cache <br/> (even if we change just a tiny file, the whole image needs to be re-squashed) .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Multi-stage builds Multi-stage builds allow us to have multiple *stages*. Each stage is a separate image, and can copy files from previous stages. We're going to see how they work in more detail. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- class: pic .interstitial[] --- name: toc-multi-stage-builds class: title Multi-stage builds .nav[ [Previous part](#toc-reducing-image-size) | [Back to table of contents](#toc-part-3) | [Next part](#toc-publishing-images-to-the-docker-hub) ] .debug[(automatically generated title slide)] --- # Multi-stage builds * At any point in our `Dockerfile`, we can add a new `FROM` line. * This line starts a new stage of our build. * Each stage can access the files of the previous stages with `COPY --from=...`. * When a build is tagged (with `docker build -t ...`), the last stage is tagged. * Previous stages are not discarded: they will be used for caching, and can be referenced. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Multi-stage builds in practice * Each stage is numbered, starting at `0` * We can copy a file from a previous stage by indicating its number, e.g.: ```dockerfile COPY --from=0 /file/from/first/stage /location/in/current/stage ``` * We can also name stages, and reference these names: ```dockerfile FROM golang AS builder RUN ... FROM alpine COPY --from=builder /go/bin/mylittlebinary /usr/local/bin/ ``` .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Multi-stage builds for our C program We will change our Dockerfile to: * give a nickname to the first stage: `compiler` * add a second stage using the same `ubuntu` base image * add the `hello` binary to the second stage * make sure that `CMD` is in the second stage The resulting Dockerfile is on the next slide. .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Multi-stage build `Dockerfile` Here is the final Dockerfile: ```dockerfile FROM ubuntu AS compiler RUN apt-get update RUN apt-get install -y build-essential COPY hello.c / RUN make hello FROM ubuntu COPY --from=compiler /hello /hello CMD /hello ``` Let's build it, and check that it works correctly: ```bash docker build -t hellomultistage . docker run hellomultistage ``` .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- ## Comparing single/multi-stage build image sizes List our images with `docker images`, and check the size of: - the `ubuntu` base image, - the single-stage `hello` image, - the multi-stage `hellomultistage` image. We can achieve even smaller images if we use smaller base images. However, if we use common base images (e.g. if we standardize on `ubuntu`), these common images will be pulled only once per node, so they are virtually "free." .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- class: extra-details ## Build targets * We can also tag an intermediary stage with the following command: ```bash docker build --target STAGE --tag NAME ``` * This will create an image (named `NAME`) corresponding to stage `STAGE` * This can be used to easily access an intermediary stage for inspection (instead of parsing the output of `docker build` to find out the image ID) * This can also be used to describe multiple images from a single Dockerfile (instead of using multiple Dockerfiles, which could go out of sync) -- class: extra-details ## Dealing with download caches * In some cases, our images contain temporary downloaded files or caches (examples: packages downloaded by `pip`, Maven, etc.) * These can sometimes be disabled (e.g. `pip install --no-cache-dir ...`) * The cache can also be cleaned immediately after installing (e.g. `pip install ... && rm -rf ~/.cache/pip`) .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- class: extra-details ## Download caches and multi-stage builds * Download+install packages in a build stage * Copy the installed packages to a run stage * Example: in the specific case of Python, use a virtual env (install in the virtual env; then copy the virtual env directory) .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- class: extra-details ## Download caches and BuildKit * BuildKit has a caching feature for run stages * It can address download caches elegantly * Example: ```bash RUN --mount=type=cache,target=/pipcache pip install --cache-dir /pipcache ... ``` * The cache won't be in the final image, but it'll persist across builds ??? :EN:Optimizing our images and their build process :EN:- Leveraging multi-stage builds :FR:Optimiser les images et leur construction :FR:- Utilisation d'un *multi-stage build* .debug[[containers/Multi_Stage_Builds.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Multi_Stage_Builds.md)] --- class: pic .interstitial[] --- name: toc-publishing-images-to-the-docker-hub class: title Publishing images to the Docker Hub .nav[ [Previous part](#toc-multi-stage-builds) | [Back to table of contents](#toc-part-3) | [Next part](#toc-tips-for-efficient-dockerfiles) ] .debug[(automatically generated title slide)] --- # Publishing images to the Docker Hub We have built our first images. We can now publish it to the Docker Hub! *You don't have to do the exercises in this section, because they require an account on the Docker Hub, and we don't want to force anyone to create one.* *Note, however, that creating an account on the Docker Hub is free (and doesn't require a credit card), and hosting public images is free as well.* .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- ## Logging into our Docker Hub account * This can be done from the Docker CLI: ```bash docker login ``` .warning[When running Docker for Mac/Windows, or Docker on a Linux workstation, it can (and will when possible) integrate with your system's keyring to store your credentials securely. However, on most Linux servers, it will store your credentials in `~/.docker/config`.] .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- ## Image tags and registry addresses * Docker images tags are like Git tags and branches. * They are like *bookmarks* pointing at a specific image ID. * Tagging an image doesn't *rename* an image: it adds another tag. * When pushing an image to a registry, the registry address is in the tag. Example: `registry.example.net:5000/image` * What about Docker Hub images? -- * `jpetazzo/clock` is, in fact, `index.docker.io/jpetazzo/clock` * `ubuntu` is, in fact, `library/ubuntu`, i.e. `index.docker.io/library/ubuntu` .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- ## Tagging an image to push it on the Hub * Let's tag our `figlet` image (or any other to our liking): ```bash docker tag figlet jpetazzo/figlet ``` * And push it to the Hub: ```bash docker push jpetazzo/figlet ``` * That's it! -- * Anybody can now `docker run jpetazzo/figlet` anywhere. .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- ## The goodness of automated builds * You can link a Docker Hub repository with a GitHub or BitBucket repository * Each push to GitHub or BitBucket will trigger a build on Docker Hub * If the build succeeds, the new image is available on Docker Hub * You can map tags and branches between source and container images * If you work with public repositories, this is free .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- class: extra-details ## Setting up an automated build * We need a Dockerized repository! * Let's go to https://github.com/jpetazzo/trainingwheels and fork it. * Go to the Docker Hub (https://hub.docker.com/) and sign-in. Select "Repositories" in the blue navigation menu. * Select "Create" in the top-right bar, and select "Create Repository+". * Connect your Docker Hub account to your GitHub account. * Click "Create" button. * Then go to "Builds" folder. * Click on Github icon and select your user and the repository that we just forked. * In "Build rules" block near page bottom, put `/www` in "Build Context" column (or whichever directory the Dockerfile is in). * Click "Save and Build" to build the repository immediately (without waiting for a git push). * Subsequent builds will happen automatically, thanks to GitHub hooks. .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- ## Building on the fly - Some services can build images on the fly from a repository - Example: [ctr.run](https://ctr.run/) .lab[ - Use ctr.run to automatically build a container image and run it: ```bash docker run ctr.run/github.com/undefinedlabs/hello-world ``` ] There might be a long pause before the first layer is pulled, because the API behind `docker pull` doesn't allow to stream build logs, and there is no feedback during the build. It is possible to view the build logs by setting up an account on [ctr.run](https://ctr.run/). ??? :EN:- Publishing images to the Docker Hub :FR:- Publier des images sur le Docker Hub .debug[[containers/Publishing_To_Docker_Hub.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Publishing_To_Docker_Hub.md)] --- class: pic .interstitial[] --- name: toc-tips-for-efficient-dockerfiles class: title Tips for efficient Dockerfiles .nav[ [Previous part](#toc-publishing-images-to-the-docker-hub) | [Back to table of contents](#toc-part-3) | [Next part](#toc-dockerfile-examples) ] .debug[(automatically generated title slide)] --- # Tips for efficient Dockerfiles We will see how to: * Reduce the number of layers. * Leverage the build cache so that builds can be faster. * Embed unit testing in the build process. .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Reducing the number of layers * Each line in a `Dockerfile` creates a new layer. * Build your `Dockerfile` to take advantage of Docker's caching system. * Combine commands by using `&&` to continue commands and `\` to wrap lines. Note: it is frequent to build a Dockerfile line by line: ```dockerfile RUN apt-get install thisthing RUN apt-get install andthatthing andthatotherone RUN apt-get install somemorestuff ``` And then refactor it trivially before shipping: ```dockerfile RUN apt-get install thisthing andthatthing andthatotherone somemorestuff ``` .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Avoid re-installing dependencies at each build * Classic Dockerfile problem: "each time I change a line of code, all my dependencies are re-installed!" * Solution: `COPY` dependency lists (`package.json`, `requirements.txt`, etc.) by themselves to avoid reinstalling unchanged dependencies every time. .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Example "bad" `Dockerfile` The dependencies are reinstalled every time, because the build system does not know if `requirements.txt` has been updated. ```bash FROM python WORKDIR /src COPY . . RUN pip install -qr requirements.txt EXPOSE 5000 CMD ["python", "app.py"] ``` .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Fixed `Dockerfile` Adding the dependencies as a separate step means that Docker can cache more efficiently and only install them when `requirements.txt` changes. ```bash FROM python WORKDIR /src COPY requirements.txt . RUN pip install -qr requirements.txt COPY . . EXPOSE 5000 CMD ["python", "app.py"] ``` .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Be careful with `chown`, `chmod`, `mv` * Layers cannot store efficiently changes in permissions or ownership. * Layers cannot represent efficiently when a file is moved either. * As a result, operations like `chown`, `chmod`, `mv` can be expensive. * For instance, in the Dockerfile snippet below, each `RUN` line creates a layer with an entire copy of `some-file`. ```dockerfile COPY some-file . RUN chown www-data:www-data some-file RUN chmod 644 some-file RUN mv some-file /var/www ``` * How can we avoid that? .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Put files on the right place * Instead of using `mv`, directly put files at the right place. * When extracting archives (tar, zip...), merge operations in a single layer. Example: ```dockerfile ... RUN wget http://.../foo.tar.gz \ && tar -zxf foo.tar.gz \ && mv foo/fooctl /usr/local/bin \ && rm -rf foo foo.tar.gz ... ``` .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Use `COPY --chown` * The Dockerfile instruction `COPY` can take a `--chown` parameter. Examples: ```dockerfile ... COPY --chown=1000 some-file . COPY --chown=1000:1000 some-file . COPY --chown=www-data:www-data some-file . ``` * The `--chown` flag can specify a user, or a user:group pair. * The user and group can be specified as names or numbers. * When using names, the names must exist in `/etc/passwd` or `/etc/group`. *(In the container, not on the host!)* .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Set correct permissions locally * Instead of using `chmod`, set the right file permissions locally. * When files are copied with `COPY`, permissions are preserved. .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Embedding unit tests in the build process ```dockerfile FROM <baseimage> RUN <install dependencies> COPY <code> RUN <build code> RUN <install test dependencies> COPY <test data sets and fixtures> RUN <unit tests> FROM <baseimage> RUN <install dependencies> COPY <code> RUN <build code> CMD, EXPOSE ... ``` * The build fails as soon as an instruction fails * If `RUN <unit tests>` fails, the build doesn't produce an image * If it succeeds, it produces a clean image (without test libraries and data) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- class: pic .interstitial[] --- name: toc-dockerfile-examples class: title Dockerfile examples .nav[ [Previous part](#toc-tips-for-efficient-dockerfiles) | [Back to table of contents](#toc-part-3) | [Next part](#toc-exercise--multi-stage-builds) ] .debug[(automatically generated title slide)] --- # Dockerfile examples There are a number of tips, tricks, and techniques that we can use in Dockerfiles. But sometimes, we have to use different (and even opposed) practices depending on: - the complexity of our project, - the programming language or framework that we are using, - the stage of our project (early MVP vs. super-stable production), - whether we're building a final image or a base for further images, - etc. We are going to show a few examples using very different techniques. .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## When to optimize an image When authoring official images, it is a good idea to reduce as much as possible: - the number of layers, - the size of the final image. This is often done at the expense of build time and convenience for the image maintainer; but when an image is downloaded millions of time, saving even a few seconds of pull time can be worth it. .small[ ```dockerfile RUN apt-get update && apt-get install -y libpng12-dev libjpeg-dev && rm -rf /var/lib/apt/lists/* \ && docker-php-ext-configure gd --with-png-dir=/usr --with-jpeg-dir=/usr \ && docker-php-ext-install gd ... RUN curl -o wordpress.tar.gz -SL https://wordpress.org/wordpress-${WORDPRESS_UPSTREAM_VERSION}.tar.gz \ && echo "$WORDPRESS_SHA1 *wordpress.tar.gz" | sha1sum -c - \ && tar -xzf wordpress.tar.gz -C /usr/src/ \ && rm wordpress.tar.gz \ && chown -R www-data:www-data /usr/src/wordpress ``` ] (Source: [Wordpress official image](https://github.com/docker-library/wordpress/blob/618490d4bdff6c5774b84b717979bfe3d6ba8ad1/apache/Dockerfile)) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## When to *not* optimize an image Sometimes, it is better to prioritize *maintainer convenience*. In particular, if: - the image changes a lot, - the image has very few users (e.g. only 1, the maintainer!), - the image is built and run on the same machine, - the image is built and run on machines with a very fast link ... In these cases, just keep things simple! (Next slide: a Dockerfile that can be used to preview a Jekyll / github pages site.) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ```dockerfile FROM debian:sid RUN apt-get update -q RUN apt-get install -yq build-essential make RUN apt-get install -yq zlib1g-dev RUN apt-get install -yq ruby ruby-dev RUN apt-get install -yq python-pygments RUN apt-get install -yq nodejs RUN apt-get install -yq cmake RUN gem install --no-rdoc --no-ri github-pages COPY . /blog WORKDIR /blog VOLUME /blog/_site EXPOSE 4000 CMD ["jekyll", "serve", "--host", "0.0.0.0", "--incremental"] ``` .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Multi-dimensional versioning systems Images can have a tag, indicating the version of the image. But sometimes, there are multiple important components, and we need to indicate the versions for all of them. This can be done with environment variables: ```dockerfile ENV PIP=9.0.3 \ ZC_BUILDOUT=2.11.2 \ SETUPTOOLS=38.7.0 \ PLONE_MAJOR=5.1 \ PLONE_VERSION=5.1.0 \ PLONE_MD5=76dc6cfc1c749d763c32fff3a9870d8d ``` (Source: [Plone official image](https://github.com/plone/plone.docker/blob/master/5.1/5.1.0/alpine/Dockerfile)) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Entrypoints and wrappers It is very common to define a custom entrypoint. That entrypoint will generally be a script, performing any combination of: - pre-flights checks (if a required dependency is not available, display a nice error message early instead of an obscure one in a deep log file), - generation or validation of configuration files, - dropping privileges (with e.g. `su` or `gosu`, sometimes combined with `chown`), - and more. .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## A typical entrypoint script ```dockerfile #!/bin/sh set -e # first arg is '-f' or '--some-option' # or first arg is 'something.conf' if [ "${1#-}" != "$1" ] || [ "${1%.conf}" != "$1" ]; then set -- redis-server "$@" fi # allow the container to be started with '--user' if [ "$1" = 'redis-server' -a "$(id -u)" = '0' ]; then chown -R redis . exec su-exec redis "$0" "$@" fi exec "$@" ``` (Source: [Redis official image](https://github.com/docker-library/redis/blob/d24f2be82673ccef6957210cc985e392ebdc65e4/4.0/alpine/docker-entrypoint.sh)) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Factoring information To facilitate maintenance (and avoid human errors), avoid to repeat information like: - version numbers, - remote asset URLs (e.g. source tarballs) ... Instead, use environment variables. .small[ ```dockerfile ENV NODE_VERSION 10.2.1 ... RUN ... && curl -fsSLO --compressed "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION.tar.xz" \ && curl -fsSLO --compressed "https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc" \ && gpg --batch --decrypt --output SHASUMS256.txt SHASUMS256.txt.asc \ && grep " node-v$NODE_VERSION.tar.xz\$" SHASUMS256.txt | sha256sum -c - \ && tar -xf "node-v$NODE_VERSION.tar.xz" \ && cd "node-v$NODE_VERSION" \ ... ``` ] (Source: [Nodejs official image](https://github.com/nodejs/docker-node/blob/master/10/alpine/Dockerfile)) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Overrides In theory, development and production images should be the same. In practice, we often need to enable specific behaviors in development (e.g. debug statements). One way to reconcile both needs is to use Compose to enable these behaviors. Let's look at the [trainingwheels](https://github.com/jpetazzo/trainingwheels) demo app for an example. .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Production image This Dockerfile builds an image leveraging gunicorn: ```dockerfile FROM python RUN pip install flask RUN pip install gunicorn RUN pip install redis COPY . /src WORKDIR /src CMD gunicorn --bind 0.0.0.0:5000 --workers 10 counter:app EXPOSE 5000 ``` (Source: [trainingwheels Dockerfile](https://github.com/jpetazzo/trainingwheels/blob/master/www/Dockerfile)) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## Development Compose file This Compose file uses the same image, but with a few overrides for development: - the Flask development server is used (overriding `CMD`), - the `DEBUG` environment variable is set, - a volume is used to provide a faster local development workflow. .small[ ```yaml services: www: build: www ports: - 8000:5000 user: nobody environment: DEBUG: 1 command: python counter.py volumes: - ./www:/src ``` ] (Source: [trainingwheels Compose file](https://github.com/jpetazzo/trainingwheels/blob/master/docker-compose.yml)) .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- ## How to know which best practices are better? - The main goal of containers is to make our lives easier. - In this chapter, we showed many ways to write Dockerfiles. - These Dockerfiles use sometimes diametrically opposed techniques. - Yet, they were the "right" ones *for a specific situation.* - It's OK (and even encouraged) to start simple and evolve as needed. - Feel free to review this chapter later (after writing a few Dockerfiles) for inspiration! ??? :EN:Optimizing images :EN:- Dockerfile tips, tricks, and best practices :EN:- Reducing build time :EN:- Reducing image size :FR:Optimiser ses images :FR:- Bonnes pratiques, trucs et astuces :FR:- Réduire le temps de build :FR:- Réduire la taille des images .debug[[containers/Dockerfile_Tips.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Dockerfile_Tips.md)] --- class: pic .interstitial[] --- name: toc-exercise--multi-stage-builds class: title Exercise — multi-stage builds .nav[ [Previous part](#toc-dockerfile-examples) | [Back to table of contents](#toc-part-3) | [Next part](#toc-naming-and-inspecting-containers) ] .debug[(automatically generated title slide)] --- # Exercise — multi-stage builds Let's update our Dockerfiles to leverage multi-stage builds! The code is at: https://github.com/jpetazzo/wordsmith Use a different tag for these images, so that we can compare their sizes. What's the size difference between single-stage and multi-stage builds? .debug[[containers/Exercise_Dockerfile_Multistage.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Dockerfile_Multistage.md)] --- class: pic .interstitial[] --- name: toc-naming-and-inspecting-containers class: title Naming and inspecting containers .nav[ [Previous part](#toc-exercise--multi-stage-builds) | [Back to table of contents](#toc-part-4) | [Next part](#toc-labels) ] .debug[(automatically generated title slide)] --- class: title # Naming and inspecting containers  .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Objectives In this lesson, we will learn about an important Docker concept: container *naming*. Naming allows us to: * Reference easily a container. * Ensure unicity of a specific container. We will also see the `inspect` command, which gives a lot of details about a container. .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Naming our containers So far, we have referenced containers with their ID. We have copy-pasted the ID, or used a shortened prefix. But each container can also be referenced by its name. If a container is named `thumbnail-worker`, I can do: ```bash $ docker logs thumbnail-worker $ docker stop thumbnail-worker etc. ``` .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Default names When we create a container, if we don't give a specific name, Docker will pick one for us. It will be the concatenation of: * A mood (furious, goofy, suspicious, boring...) * The name of a famous inventor (tesla, darwin, wozniak...) Examples: `happy_curie`, `clever_hopper`, `jovial_lovelace` ... .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Specifying a name You can set the name of the container when you create it. ```bash $ docker run --name ticktock jpetazzo/clock ``` If you specify a name that already exists, Docker will refuse to create the container. This lets us enforce unicity of a given resource. .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Renaming containers * You can rename containers with `docker rename`. * This allows you to "free up" a name without destroying the associated container. .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Inspecting a container The `docker inspect` command will output a very detailed JSON map. ```bash $ docker inspect <containerID> [{ ... (many pages of JSON here) ... ``` There are multiple ways to consume that information. .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Parsing JSON with the Shell * You *could* grep and cut or awk the output of `docker inspect`. * Please, don't. * It's painful. * If you really must parse JSON from the Shell, use JQ! (It's great.) ```bash $ docker inspect <containerID> | jq . ``` * We will see a better solution which doesn't require extra tools. .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- ## Using `--format` You can specify a format string, which will be parsed by Go's text/template package. ```bash $ docker inspect --format '{{ json .Created }}' <containerID> "2015-02-24T07:21:11.712240394Z" ``` * The generic syntax is to wrap the expression with double curly braces. * The expression starts with a dot representing the JSON object. * Then each field or member can be accessed in dotted notation syntax. * The optional `json` keyword asks for valid JSON output. <br/>(e.g. here it adds the surrounding double-quotes.) ??? :EN:Managing container lifecycle :EN:- Naming and inspecting containers :FR:Suivre ses conteneurs à la loupe :FR:- Obtenir des informations détaillées sur un conteneur :FR:- Associer un identifiant unique à un conteneur .debug[[containers/Naming_And_Inspecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Naming_And_Inspecting.md)] --- class: pic .interstitial[] --- name: toc-labels class: title Labels .nav[ [Previous part](#toc-naming-and-inspecting-containers) | [Back to table of contents](#toc-part-4) | [Next part](#toc-getting-inside-a-container) ] .debug[(automatically generated title slide)] --- # Labels * Labels allow to attach arbitrary metadata to containers. * Labels are key/value pairs. * They are specified at container creation. * You can query them with `docker inspect`. * They can also be used as filters with some commands (e.g. `docker ps`). .debug[[containers/Labels.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Labels.md)] --- ## Using labels Let's create a few containers with a label `owner`. ```bash docker run -d -l owner=alice nginx docker run -d -l owner=bob nginx docker run -d -l owner nginx ``` We didn't specify a value for the `owner` label in the last example. This is equivalent to setting the value to be an empty string. .debug[[containers/Labels.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Labels.md)] --- ## Querying labels We can view the labels with `docker inspect`. ```bash $ docker inspect $(docker ps -lq) | grep -A3 Labels "Labels": { "maintainer": "NGINX Docker Maintainers <docker-maint@nginx.com>", "owner": "" }, ``` We can use the `--format` flag to list the value of a label. ```bash $ docker inspect $(docker ps -q) --format 'OWNER={{.Config.Labels.owner}}' ``` .debug[[containers/Labels.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Labels.md)] --- ## Using labels to select containers We can list containers having a specific label. ```bash $ docker ps --filter label=owner ``` Or we can list containers having a specific label with a specific value. ```bash $ docker ps --filter label=owner=alice ``` .debug[[containers/Labels.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Labels.md)] --- ## Use-cases for labels * HTTP vhost of a web app or web service. (The label is used to generate the configuration for NGINX, HAProxy, etc.) * Backup schedule for a stateful service. (The label is used by a cron job to determine if/when to backup container data.) * Service ownership. (To determine internal cross-billing, or who to page in case of outage.) * etc. ??? :EN:- Using labels to identify containers :FR:- Étiqueter ses conteneurs avec des méta-données .debug[[containers/Labels.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Labels.md)] --- class: pic .interstitial[] --- name: toc-getting-inside-a-container class: title Getting inside a container .nav[ [Previous part](#toc-labels) | [Back to table of contents](#toc-part-4) | [Next part](#toc-container-networking-basics) ] .debug[(automatically generated title slide)] --- class: title # Getting inside a container  .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Objectives On a traditional server or VM, we sometimes need to: * log into the machine (with SSH or on the console), * analyze the disks (by removing them or rebooting with a rescue system). In this chapter, we will see how to do that with containers. .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Getting a shell Every once in a while, we want to log into a machine. In an perfect world, this shouldn't be necessary. * You need to install or update packages (and their configuration)? Use configuration management. (e.g. Ansible, Chef, Puppet, Salt...) * You need to view logs and metrics? Collect and access them through a centralized platform. In the real world, though ... we often need shell access! .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Not getting a shell Even without a perfect deployment system, we can do many operations without getting a shell. * Installing packages can (and should) be done in the container image. * Configuration can be done at the image level, or when the container starts. * Dynamic configuration can be stored in a volume (shared with another container). * Logs written to stdout are automatically collected by the Docker Engine. * Other logs can be written to a shared volume. * Process information and metrics are visible from the host. _Let's save logging, volumes ... for later, but let's have a look at process information!_ .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Viewing container processes from the host If you run Docker on Linux, container processes are visible on the host. ```bash $ ps faux | less ``` * Scroll around the output of this command. * You should see the `jpetazzo/clock` container. * A containerized process is just like any other process on the host. * We can use tools like `lsof`, `strace`, `gdb` ... To analyze them. .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- class: extra-details ## What's the difference between a container process and a host process? * Each process (containerized or not) belongs to *namespaces* and *cgroups*. * The namespaces and cgroups determine what a process can "see" and "do". * Analogy: each process (containerized or not) runs with a specific UID (user ID). * UID=0 is root, and has elevated privileges. Other UIDs are normal users. _We will give more details about namespaces and cgroups later._ .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Getting a shell in a running container * Sometimes, we need to get a shell anyway. * We _could_ run some SSH server in the container ... * But it is easier to use `docker exec`. ```bash $ docker exec -ti ticktock sh ``` * This creates a new process (running `sh`) _inside_ the container. * This can also be done "manually" with the tool `nsenter`. .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Caveats * The tool that you want to run needs to exist in the container. * Some tools (like `ip netns exec`) let you attach to _one_ namespace at a time. (This lets you e.g. setup network interfaces, even if you don't have `ifconfig` or `ip` in the container.) * Most importantly: the container needs to be running. * What if the container is stopped or crashed? .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Getting a shell in a stopped container * A stopped container is only _storage_ (like a disk drive). * We cannot SSH into a disk drive or USB stick! * We need to connect the disk to a running machine. * How does that translate into the container world? .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Analyzing a stopped container As an exercise, we are going to try to find out what's wrong with `jpetazzo/crashtest`. ```bash docker run jpetazzo/crashtest ``` The container starts, but then stops immediately, without any output. What would MacGyver™ do? First, let's check the status of that container. ```bash docker ps -l ``` .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Viewing filesystem changes * We can use `docker diff` to see files that were added / changed / removed. ```bash docker diff <container_id> ``` * The container ID was shown by `docker ps -l`. * We can also see it with `docker ps -lq`. * The output of `docker diff` shows some interesting log files! .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Accessing files * We can extract files with `docker cp`. ```bash docker cp <container_id>:/var/log/nginx/error.log . ``` * Then we can look at that log file. ```bash cat error.log ``` (The directory `/run/nginx` doesn't exist.) .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- ## Exploring a crashed container * We can restart a container with `docker start` ... * ... But it will probably crash again immediately! * We cannot specify a different program to run with `docker start` * But we can create a new image from the crashed container ```bash docker commit <container_id> debugimage ``` * Then we can run a new container from that image, with a custom entrypoint ```bash docker run -ti --entrypoint sh debugimage ``` .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- class: extra-details ## Obtaining a complete dump * We can also dump the entire filesystem of a container. * This is done with `docker export`. * It generates a tar archive. ```bash docker export <container_id> | tar tv ``` This will give a detailed listing of the content of the container. ??? :EN:- Troubleshooting and getting inside a container :FR:- Inspecter un conteneur en détail, en *live* ou *post-mortem* .debug[[containers/Getting_Inside.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Getting_Inside.md)] --- class: pic .interstitial[] --- name: toc-container-networking-basics class: title Container networking basics .nav[ [Previous part](#toc-getting-inside-a-container) | [Back to table of contents](#toc-part-5) | [Next part](#toc-container-network-drivers) ] .debug[(automatically generated title slide)] --- class: title # Container networking basics  .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Objectives We will now run network services (accepting requests) in containers. At the end of this section, you will be able to: * Run a network service in a container. * Connect to that network service. * Find a container's IP address. .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Running a very simple service - We need something small, simple, easy to configure (or, even better, that doesn't require any configuration at all) - Let's use the official NGINX image (named `nginx`) - It runs a static web server listening on port 80 - It serves a default "Welcome to nginx!" page .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Running an NGINX server ```bash $ docker run -d -P nginx 66b1ce719198711292c8f34f84a7b68c3876cf9f67015e752b94e189d35a204e ``` - Docker will automatically pull the `nginx` image from the Docker Hub - `-d` / `--detach` tells Docker to run it in the background - `P` / `--publish-all` tells Docker to publish all ports (publish = make them reachable from other computers) - ...OK, how do we connect to our web server now? .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Finding our web server port - First, we need to find the *port number* used by Docker (the NGINX container listens on port 80, but this port will be *mapped*) - We can use `docker ps`: ```bash $ docker ps CONTAINER ID IMAGE ... PORTS ... e40ffb406c9e nginx ... 0.0.0.0:`12345`->80/tcp ... ``` - This means: *port 12345 on the Docker host is mapped to port 80 in the container* - Now we need to connect to the Docker host! .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Finding the address of the Docker host - When running Docker on your Linux workstation: *use `localhost`, or any IP address of your machine* - When running Docker on a remote Linux server: *use any IP address of the remote machine* - When running Docker Desktop on Mac or Windows: *use `localhost`* - In other scenarios (`docker-machine`, local VM...): *use the IP address of the Docker VM* .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Connecting to our web server (GUI) Point your browser to the IP address of your Docker host, on the port shown by `docker ps` for container port 80.  .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Connecting to our web server (CLI) You can also use `curl` directly from the Docker host. Make sure to use the right port number if it is different from the example below: ```bash $ curl localhost:12345 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ... ``` .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## How does Docker know which port to map? * There is metadata in the image telling "this image has something on port 80". * We can see that metadata with `docker inspect`: ```bash $ docker inspect --format '{{.Config.ExposedPorts}}' nginx map[80/tcp:{}] ``` * This metadata was set in the Dockerfile, with the `EXPOSE` keyword. * We can see that with `docker history`: ```bash $ docker history nginx IMAGE CREATED CREATED BY 7f70b30f2cc6 11 days ago /bin/sh -c #(nop) CMD ["nginx" "-g" "… <missing> 11 days ago /bin/sh -c #(nop) STOPSIGNAL [SIGTERM] <missing> 11 days ago /bin/sh -c #(nop) EXPOSE 80/tcp ``` .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Why can't we just connect to port 80? - Our Docker host has only one port 80 - Therefore, we can only have one container at a time on port 80 - Therefore, if multiple containers want port 80, only one can get it - By default, containers *do not* get "their" port number, but a random one (not "random" as "crypto random", but as "it depends on various factors") - We'll see later how to force a port number (including port 80!) .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- class: extra-details ## Using multiple IP addresses *Hey, my network-fu is strong, and I have questions...* - Can I publish one container on 127.0.0.2:80, and another on 127.0.0.3:80? - My machine has multiple (public) IP addresses, let's say A.A.A.A and B.B.B.B. <br/> Can I have one container on A.A.A.A:80 and another on B.B.B.B:80? - I have a whole IPV4 subnet, can I allocate it to my containers? - What about IPV6? You can do all these things when running Docker directly on Linux. (On other platforms, *generally not*, but there are some exceptions.) .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Finding the web server port in a script Parsing the output of `docker ps` would be painful. There is a command to help us: ```bash $ docker port <containerID> 80 0.0.0.0:12345 ``` .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Manual allocation of port numbers If you want to set port numbers yourself, no problem: ```bash $ docker run -d -p 80:80 nginx $ docker run -d -p 8000:80 nginx $ docker run -d -p 8080:80 -p 8888:80 nginx ``` * We are running three NGINX web servers. * The first one is exposed on port 80. * The second one is exposed on port 8000. * The third one is exposed on ports 8080 and 8888. Note: the convention is `port-on-host:port-on-container`. .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Plumbing containers into your infrastructure There are many ways to integrate containers in your network. * Start the container, letting Docker allocate a public port for it. <br/>Then retrieve that port number and feed it to your configuration. * Pick a fixed port number in advance, when you generate your configuration. <br/>Then start your container by setting the port numbers manually. * Use an orchestrator like Kubernetes or Swarm. <br/>The orchestrator will provide its own networking facilities. Orchestrators typically provide mechanisms to enable direct container-to-container communication across hosts, and publishing/load balancing for inbound traffic. .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Finding the container's IP address We can use the `docker inspect` command to find the IP address of the container. ```bash $ docker inspect --format '{{ .NetworkSettings.IPAddress }}' <yourContainerID> 172.17.0.3 ``` * `docker inspect` is an advanced command, that can retrieve a ton of information about our containers. * Here, we provide it with a format string to extract exactly the private IP address of the container. .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Pinging our container Let's try to ping our container *from another container.* ```bash docker run alpine ping `<ipaddress>` PING 172.17.0.X (172.17.0.X): 56 data bytes 64 bytes from 172.17.0.X: seq=0 ttl=64 time=0.106 ms 64 bytes from 172.17.0.X: seq=1 ttl=64 time=0.250 ms 64 bytes from 172.17.0.X: seq=2 ttl=64 time=0.188 ms ``` When running on Linux, we can even ping that IP address directly! (And connect to a container's ports even if they aren't published.) .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## How often do we use `-p` and `-P` ? - When running a stack of containers, we will often use Compose - Compose will take care of exposing containers (through a `ports:` section in the `docker-compose.yml` file) - It is, however, fairly common to use `docker run -P` for a quick test - Or `docker run -p ...` when an image doesn't `EXPOSE` a port correctly .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- ## Section summary We've learned how to: * Expose a network port. * Connect to an application running in a container. * Find a container's IP address. ??? :EN:- Exposing single containers :FR:- Exposer un conteneur isolé .debug[[containers/Container_Networking_Basics.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Networking_Basics.md)] --- class: pic .interstitial[] --- name: toc-container-network-drivers class: title Container network drivers .nav[ [Previous part](#toc-container-networking-basics) | [Back to table of contents](#toc-part-5) | [Next part](#toc-the-container-network-model) ] .debug[(automatically generated title slide)] --- # Container network drivers The Docker Engine supports different network drivers. The built-in drivers include: * `bridge` (default) * `null` (for the special network called `none`) * `host` (for the special network called `host`) * `container` (that one is a bit magic!) The network is selected with `docker run --net ...`. Each network is managed by a driver. The different drivers are explained with more details on the following slides. .debug[[containers/Network_Drivers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Network_Drivers.md)] --- ## The default bridge * By default, the container gets a virtual `eth0` interface. <br/>(In addition to its own private `lo` loopback interface.) * That interface is provided by a `veth` pair. * It is connected to the Docker bridge. <br/>(Named `docker0` by default; configurable with `--bridge`.) * Addresses are allocated on a private, internal subnet. <br/>(Docker uses 172.17.0.0/16 by default; configurable with `--bip`.) * Outbound traffic goes through an iptables MASQUERADE rule. * Inbound traffic goes through an iptables DNAT rule. * The container can have its own routes, iptables rules, etc. .debug[[containers/Network_Drivers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Network_Drivers.md)] --- ## The null driver * Container is started with `docker run --net none ...` * It only gets the `lo` loopback interface. No `eth0`. * It can't send or receive network traffic. * Useful for isolated/untrusted workloads. .debug[[containers/Network_Drivers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Network_Drivers.md)] --- ## The host driver * Container is started with `docker run --net host ...` * It sees (and can access) the network interfaces of the host. * It can bind any address, any port (for ill and for good). * Network traffic doesn't have to go through NAT, bridge, or veth. * Performance = native! Use cases: * Performance sensitive applications (VOIP, gaming, streaming...) * Peer discovery (e.g. Erlang port mapper, Raft, Serf...) .debug[[containers/Network_Drivers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Network_Drivers.md)] --- ## The container driver * Container is started with `docker run --net container:id ...` * It re-uses the network stack of another container. * It shares with this other container the same interfaces, IP address(es), routes, iptables rules, etc. * Those containers can communicate over their `lo` interface. <br/>(i.e. one can bind to 127.0.0.1 and the others can connect to it.) ??? :EN:Advanced container networking :EN:- Transparent network access with the "host" driver :EN:- Sharing is caring with the "container" driver :FR:Paramétrage réseau avancé :FR:- Accès transparent au réseau avec le mode "host" :FR:- Partage de la pile réseau avece le mode "container" .debug[[containers/Network_Drivers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Network_Drivers.md)] --- class: pic .interstitial[] --- name: toc-the-container-network-model class: title The Container Network Model .nav[ [Previous part](#toc-container-network-drivers) | [Back to table of contents](#toc-part-5) | [Next part](#toc-service-discovery-with-containers) ] .debug[(automatically generated title slide)] --- class: title # The Container Network Model  .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Objectives We will learn about the CNM (Container Network Model). At the end of this lesson, you will be able to: * Create a private network for a group of containers. * Use container naming to connect services together. * Dynamically connect and disconnect containers to networks. * Set the IP address of a container. We will also explain the principle of overlay networks and network plugins. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## The Container Network Model Docker has "networks". We can manage them with the `docker network` commands; for instance: ```bash $ docker network ls NETWORK ID NAME DRIVER 6bde79dfcf70 bridge bridge 8d9c78725538 none null eb0eeab782f4 host host 4c1ff84d6d3f blog-dev overlay 228a4355d548 blog-prod overlay ``` New networks can be created (with `docker network create`). (Note: networks `none` and `host` are special; let's set them aside for now.) .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## What's a network? - Conceptually, a Docker "network" is a virtual switch (we can also think about it like a VLAN, or a WiFi SSID, for instance) - By default, containers are connected to a single network (but they can be connected to zero, or many networks, even dynamically) - Each network has its own subnet (IP address range) - A network can be local (to a single Docker Engine) or global (span multiple hosts) - Containers can have *network aliases* providing DNS-based service discovery (and each network has its own "domain", "zone", or "scope") .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Service discovery - A container can be given a network alias (e.g. with `docker run --net some-network --net-alias db ...`) - The containers running in the same network can resolve that network alias (i.e. if they do a DNS lookup on `db`, it will give the container's address) - We can have a different `db` container in each network (this avoids naming conflicts between different stacks) - When we name a container, it automatically adds the name as a network alias (i.e. `docker run --name xyz ...` is like `docker run --net-alias xyz ...` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Network isolation - Networks are isolated - By default, containers in network A cannot reach those in network B - A container connected to both networks A and B can act as a router or proxy - Published ports are always reachable through the Docker host address (`docker run -P ...` makes a container port available to everyone) .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## How to use networks - We typically create one network per "stack" or app that we deploy - More complex apps or stacks might require multiple networks (e.g. `frontend`, `backend`, ...) - Networks allow us to deploy multiple copies of the same stack (e.g. `prod`, `dev`, `pr-442`, ....) - If we use Docker Compose, this is managed automatically for us .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: pic 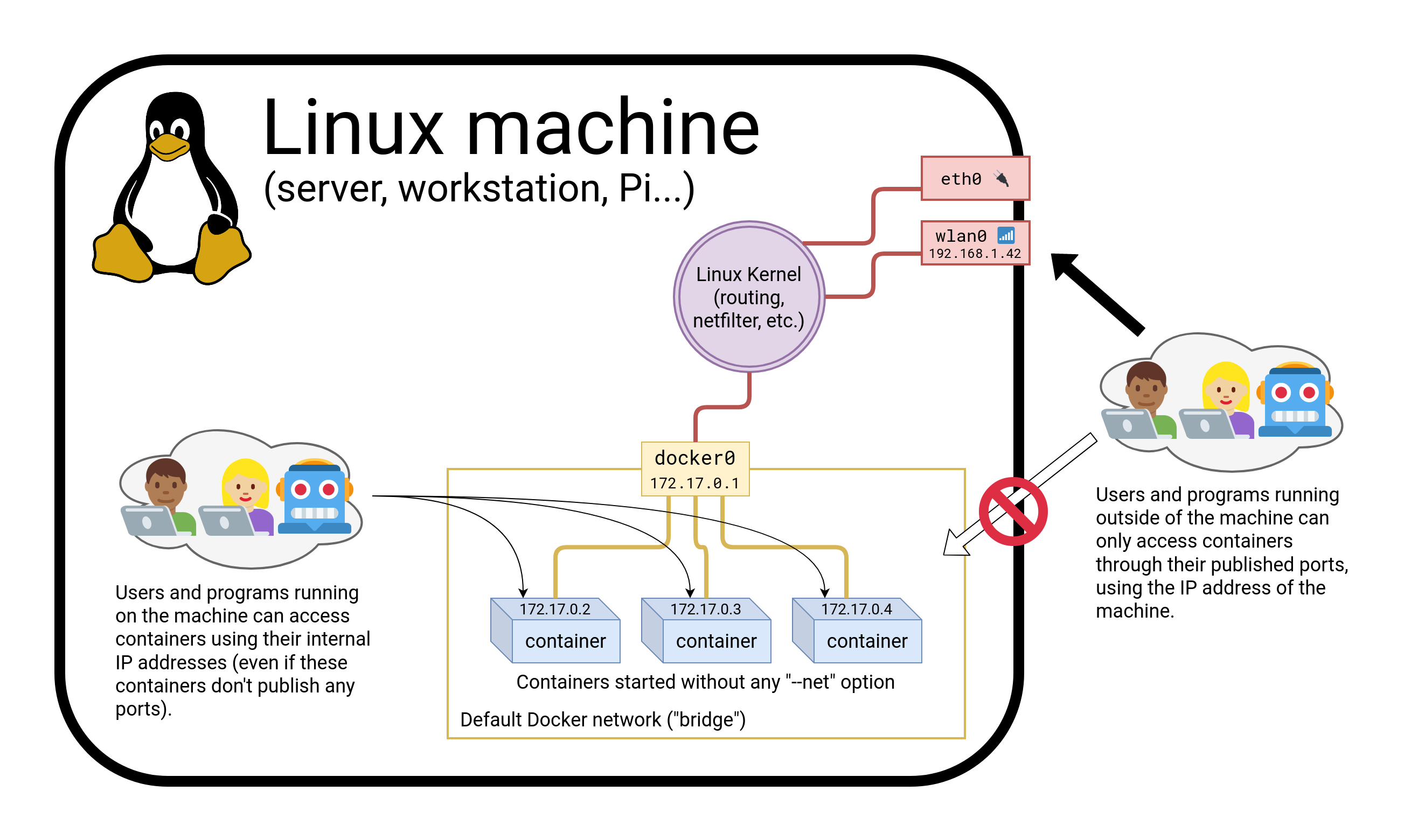 .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: pic 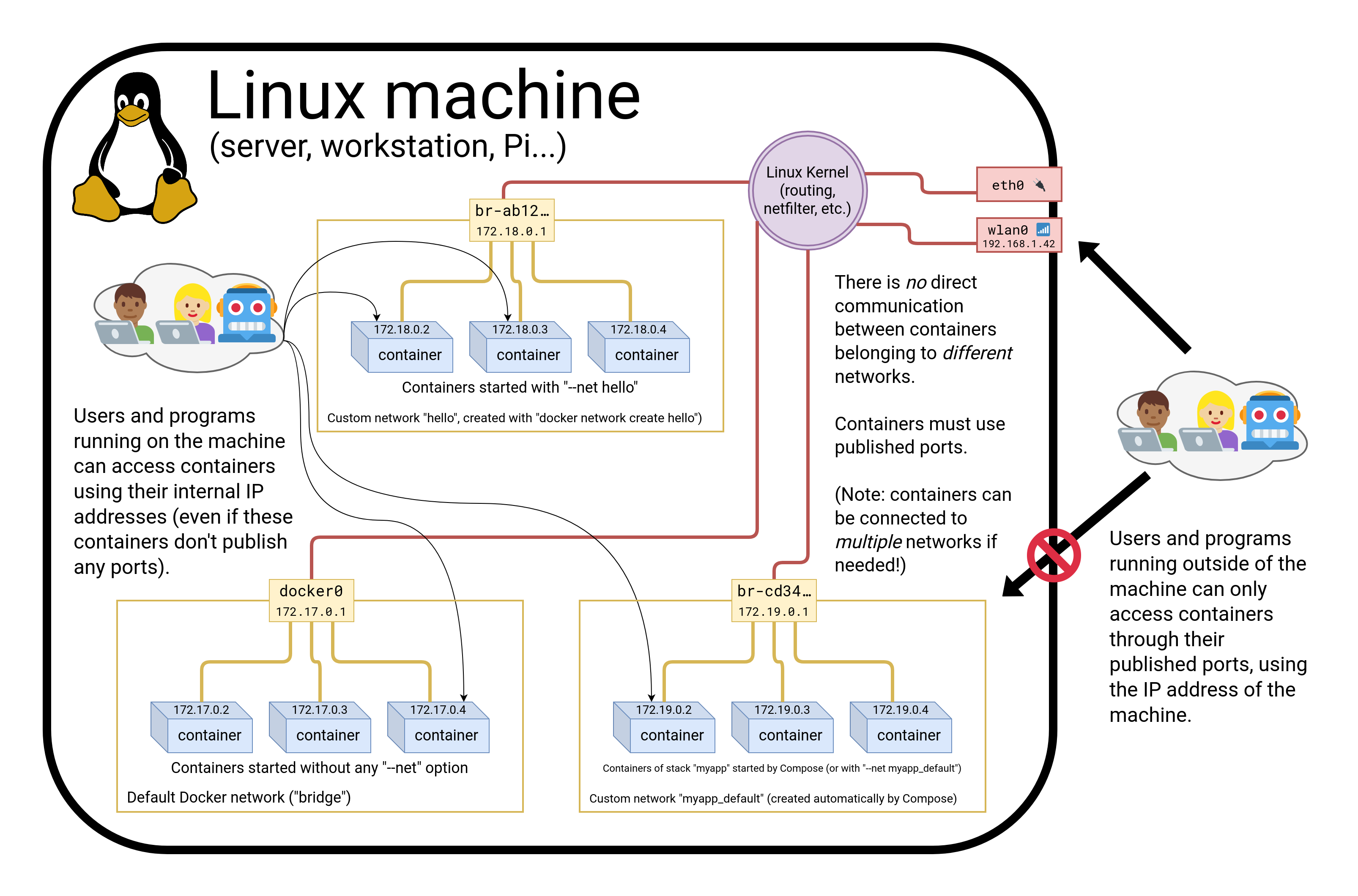 .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: pic 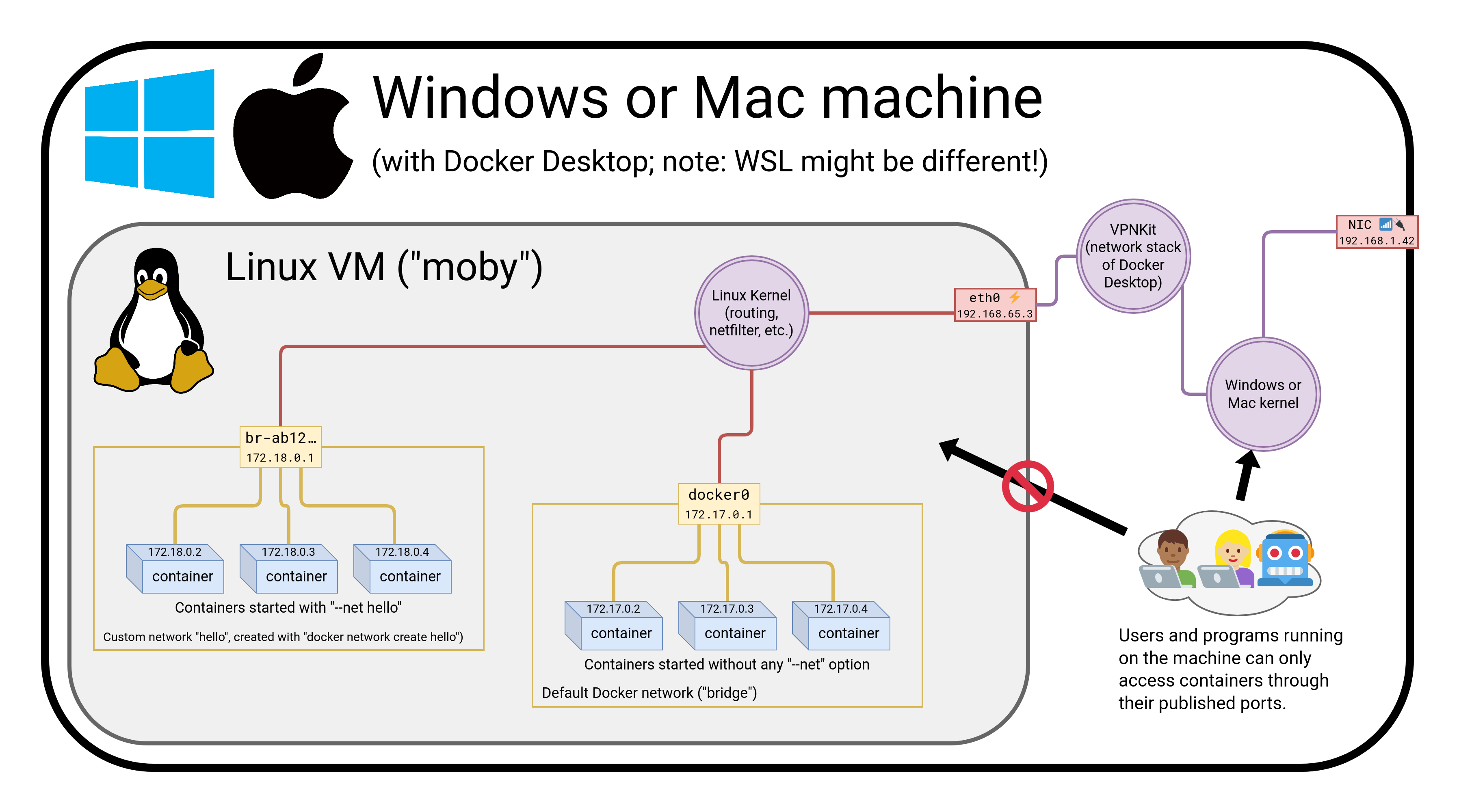 .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## CNM vs CNI - CNM is the model used by Docker - Kubernetes uses a different model, architectured around CNI (CNI is a kind of API between a container engine and *CNI plugins*) - Docker model: - multiple isolated networks - per-network service discovery - network interconnection requires extra steps - Kubernetes model: - single flat network - per-namespace service discovery - network isolation requires extra steps (Network Policies) .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Creating a network Let's create a network called `dev`. ```bash $ docker network create dev 4c1ff84d6d3f1733d3e233ee039cac276f425a9d5228a4355d54878293a889ba ``` The network is now visible with the `network ls` command: ```bash $ docker network ls NETWORK ID NAME DRIVER 6bde79dfcf70 bridge bridge 8d9c78725538 none null eb0eeab782f4 host host 4c1ff84d6d3f dev bridge ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Placing containers on a network We will create a *named* container on this network. It will be reachable with its name, `es`. ```bash $ docker run -d --name es --net dev elasticsearch:2 8abb80e229ce8926c7223beb69699f5f34d6f1d438bfc5682db893e798046863 ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Communication between containers Now, create another container on this network. .small[ ```bash $ docker run -ti --net dev alpine sh root@0ecccdfa45ef:/# ``` ] From this new container, we can resolve and ping the other one, using its assigned name: .small[ ```bash / # ping es PING es (172.18.0.2) 56(84) bytes of data. 64 bytes from es.dev (172.18.0.2): icmp_seq=1 ttl=64 time=0.221 ms 64 bytes from es.dev (172.18.0.2): icmp_seq=2 ttl=64 time=0.114 ms 64 bytes from es.dev (172.18.0.2): icmp_seq=3 ttl=64 time=0.114 ms ^C --- es ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.114/0.149/0.221/0.052 ms root@0ecccdfa45ef:/# ``` ] .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Resolving container addresses Since Docker Engine 1.10, name resolution is implemented by a dynamic resolver. Archeological note: when CNM was intoduced (in Docker Engine 1.9, November 2015) name resolution was implemented with `/etc/hosts`, and it was updated each time CONTAINERs were added/removed. This could cause interesting race conditions since `/etc/hosts` was a bind-mount (and couldn't be updated atomically). .small[ ```bash [root@0ecccdfa45ef /]# cat /etc/hosts 172.18.0.3 0ecccdfa45ef 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.18.0.2 es 172.18.0.2 es.dev ``` ] .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: pic .interstitial[] --- name: toc-service-discovery-with-containers class: title Service discovery with containers .nav[ [Previous part](#toc-the-container-network-model) | [Back to table of contents](#toc-part-5) | [Next part](#toc-ambassadors) ] .debug[(automatically generated title slide)] --- # Service discovery with containers * Let's try to run an application that requires two containers. * The first container is a web server. * The other one is a redis data store. * We will place them both on the `dev` network created before. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Running the web server * The application is provided by the container image `jpetazzo/trainingwheels`. * We don't know much about it so we will try to run it and see what happens! Start the container, exposing all its ports: ```bash $ docker run --net dev -d -P jpetazzo/trainingwheels ``` Check the port that has been allocated to it: ```bash $ docker ps -l ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Test the web server * If we connect to the application now, we will see an error page: 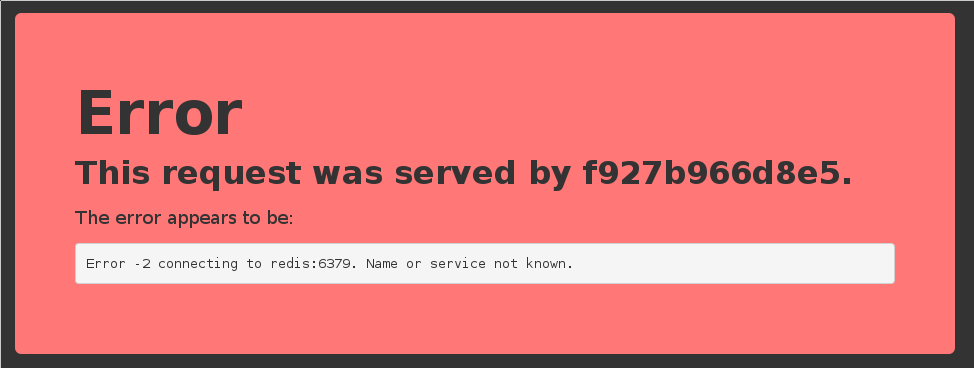 * This is because the Redis service is not running. * This container tries to resolve the name `redis`. Note: we're not using a FQDN or an IP address here; just `redis`. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Start the data store * We need to start a Redis container. * That container must be on the same network as the web server. * It must have the right network alias (`redis`) so the application can find it. Start the container: ```bash $ docker run --net dev --net-alias redis -d redis ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Test the web server again * If we connect to the application now, we should see that the app is working correctly: 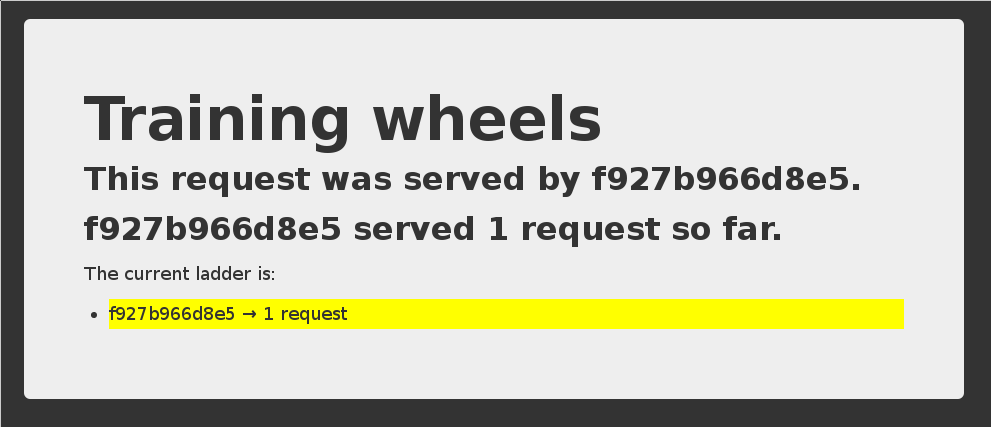 * When the app tries to resolve `redis`, instead of getting a DNS error, it gets the IP address of our Redis container. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## A few words on *scope* - Container names are unique (there can be only one `--name redis`) - Network aliases are not unique - We can have the same network alias in different networks: ```bash docker run --net dev --net-alias redis ... docker run --net prod --net-alias redis ... ``` - We can even have multiple containers with the same alias in the same network (in that case, we get multiple DNS entries, aka "DNS round robin") .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Names are *local* to each network Let's try to ping our `es` container from another container, when that other container is *not* on the `dev` network. ```bash $ docker run --rm alpine ping es ping: bad address 'es' ``` Names can be resolved only when containers are on the same network. Containers can contact each other only when they are on the same network (you can try to ping using the IP address to verify). .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Network aliases We would like to have another network, `prod`, with its own `es` container. But there can be only one container named `es`! We will use *network aliases*. A container can have multiple network aliases. Network aliases are *local* to a given network (only exist in this network). Multiple containers can have the same network alias (even on the same network). Since Docker Engine 1.11, resolving a network alias yields the IP addresses of all containers holding this alias. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Creating containers on another network Create the `prod` network. ```bash $ docker network create prod 5a41562fecf2d8f115bedc16865f7336232a04268bdf2bd816aecca01b68d50c ``` We can now create multiple containers with the `es` alias on the new `prod` network. ```bash $ docker run -d --name prod-es-1 --net-alias es --net prod elasticsearch:2 38079d21caf0c5533a391700d9e9e920724e89200083df73211081c8a356d771 $ docker run -d --name prod-es-2 --net-alias es --net prod elasticsearch:2 1820087a9c600f43159688050dcc164c298183e1d2e62d5694fd46b10ac3bc3d ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Resolving network aliases Let's try DNS resolution first, using the `nslookup` tool that ships with the `alpine` image. ```bash $ docker run --net prod --rm alpine nslookup es Name: es Address 1: 172.23.0.3 prod-es-2.prod Address 2: 172.23.0.2 prod-es-1.prod ``` (You can ignore the `can't resolve '(null)'` errors.) .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Connecting to aliased containers Each ElasticSearch instance has a name (generated when it is started). This name can be seen when we issue a simple HTTP request on the ElasticSearch API endpoint. Try the following command a few times: .small[ ```bash $ docker run --rm --net dev centos curl -s es:9200 { "name" : "Tarot", ... } ``` ] Then try it a few times by replacing `--net dev` with `--net prod`: .small[ ```bash $ docker run --rm --net prod centos curl -s es:9200 { "name" : "The Symbiote", ... } ``` ] .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Good to know ... * Docker will not create network names and aliases on the default `bridge` network. * Therefore, if you want to use those features, you have to create a custom network first. * Network aliases are *not* unique on a given network. * i.e., multiple containers can have the same alias on the same network. * In that scenario, the Docker DNS server will return multiple records. <br/> (i.e. you will get DNS round robin out of the box.) * Enabling *Swarm Mode* gives access to clustering and load balancing with IPVS. * Creation of networks and network aliases is generally automated with tools like Compose. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## A few words about round robin DNS Don't rely exclusively on round robin DNS to achieve load balancing. Many factors can affect DNS resolution, and you might see: - all traffic going to a single instance; - traffic being split (unevenly) between some instances; - different behavior depending on your application language; - different behavior depending on your base distro; - different behavior depending on other factors (sic). It's OK to use DNS to discover available endpoints, but remember that you have to re-resolve every now and then to discover new endpoints. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Custom networks When creating a network, extra options can be provided. * `--internal` disables outbound traffic (the network won't have a default gateway). * `--gateway` indicates which address to use for the gateway (when outbound traffic is allowed). * `--subnet` (in CIDR notation) indicates the subnet to use. * `--ip-range` (in CIDR notation) indicates the subnet to allocate from. * `--aux-address` allows specifying a list of reserved addresses (which won't be allocated to containers). .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Setting containers' IP address * It is possible to set a container's address with `--ip`. * The IP address has to be within the subnet used for the container. A full example would look like this. ```bash $ docker network create --subnet 10.66.0.0/16 pubnet 42fb16ec412383db6289a3e39c3c0224f395d7f85bcb1859b279e7a564d4e135 $ docker run --net pubnet --ip 10.66.66.66 -d nginx b2887adeb5578a01fd9c55c435cad56bbbe802350711d2743691f95743680b09 ``` *Note: don't hard code container IP addresses in your code!* *I repeat: don't hard code container IP addresses in your code!* .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Network drivers * A network is managed by a *driver*. * The built-in drivers include: * `bridge` (default) * `none` * `host` * `macvlan` * `overlay` (for Swarm clusters) * More drivers can be provided by plugins (OVS, VLAN...) * A network can have a custom IPAM (IP allocator). .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Overlay networks * The features we've seen so far only work when all containers are on a single host. * If containers span multiple hosts, we need an *overlay* network to connect them together. * Docker ships with a default network plugin, `overlay`, implementing an overlay network leveraging VXLAN, *enabled with Swarm Mode*. * Other plugins (Weave, Calico...) can provide overlay networks as well. * Once you have an overlay network, *all the features that we've used in this chapter work identically across multiple hosts.* .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Multi-host networking (overlay) Out of the scope for this intro-level workshop! Very short instructions: - enable Swarm Mode (`docker swarm init` then `docker swarm join` on other nodes) - `docker network create mynet --driver overlay` - `docker service create --network mynet myimage` If you want to learn more about Swarm mode, you can check [this video](https://www.youtube.com/watch?v=EuzoEaE6Cqs) or [these slides](https://container.training/swarm-selfpaced.yml.html). .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Multi-host networking (plugins) Out of the scope for this intro-level workshop! General idea: - install the plugin (they often ship within containers) - run the plugin (if it's in a container, it will often require extra parameters; don't just `docker run` it blindly!) - some plugins require configuration or activation (creating a special file that tells Docker "use the plugin whose control socket is at the following location") - you can then `docker network create --driver pluginname` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Connecting and disconnecting dynamically * So far, we have specified which network to use when starting the container. * The Docker Engine also allows connecting and disconnecting while the container is running. * This feature is exposed through the Docker API, and through two Docker CLI commands: * `docker network connect <network> <container>` * `docker network disconnect <network> <container>` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Dynamically connecting to a network * We have a container named `es` connected to a network named `dev`. * Let's start a simple alpine container on the default network: ```bash $ docker run -ti alpine sh / # ``` * In this container, try to ping the `es` container: ```bash / # ping es ping: bad address 'es' ``` This doesn't work, but we will change that by connecting the container. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Finding the container ID and connecting it * Figure out the ID of our alpine container; here are two methods: * looking at `/etc/hostname` in the container, * running `docker ps -lq` on the host. * Run the following command on the host: ```bash $ docker network connect dev `<container_id>` ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Checking what we did * Try again to `ping es` from the container. * It should now work correctly: ```bash / # ping es PING es (172.20.0.3): 56 data bytes 64 bytes from 172.20.0.3: seq=0 ttl=64 time=0.376 ms 64 bytes from 172.20.0.3: seq=1 ttl=64 time=0.130 ms ^C ``` * Interrupt it with Ctrl-C. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Looking at the network setup in the container We can look at the list of network interfaces with `ifconfig`, `ip a`, or `ip l`: .small[ ```bash / # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 18: eth0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever 20: eth1@if21: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:14:00:04 brd ff:ff:ff:ff:ff:ff inet 172.20.0.4/16 brd 172.20.255.255 scope global eth1 valid_lft forever preferred_lft forever / # ``` ] Each network connection is materialized with a virtual network interface. As we can see, we can be connected to multiple networks at the same time. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- ## Disconnecting from a network * Let's try the symmetrical command to disconnect the container: ```bash $ docker network disconnect dev <container_id> ``` * From now on, if we try to ping `es`, it will not resolve: ```bash / # ping es ping: bad address 'es' ``` * Trying to ping the IP address directly won't work either: ```bash / # ping 172.20.0.3 ... (nothing happens until we interrupt it with Ctrl-C) ``` .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Network aliases are scoped per network * Each network has its own set of network aliases. * We saw this earlier: `es` resolves to different addresses in `dev` and `prod`. * If we are connected to multiple networks, the resolver looks up names in each of them (as of Docker Engine 18.03, it is the connection order) and stops as soon as the name is found. * Therefore, if we are connected to both `dev` and `prod`, resolving `es` will **not** give us the addresses of all the `es` services; but only the ones in `dev` or `prod`. * However, we can lookup `es.dev` or `es.prod` if we need to. .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Finding out about our networks and names * We can do reverse DNS lookups on containers' IP addresses. * If the IP address belongs to a network (other than the default bridge), the result will be: ``` name-or-first-alias-or-container-id.network-name ``` * Example: .small[ ```bash $ docker run -ti --net prod --net-alias hello alpine / # apk add --no-cache drill ... OK: 5 MiB in 13 packages / # ifconfig eth0 Link encap:Ethernet HWaddr 02:42:AC:15:00:03 inet addr:`172.21.0.3` Bcast:172.21.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 ... / # drill -t ptr `3.0.21.172`.in-addr.arpa ... ;; ANSWER SECTION: 3.0.21.172.in-addr.arpa. 600 IN PTR `hello.prod`. ... ``` ] .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: extra-details ## Building with a custom network * We can build a Dockerfile with a custom network with `docker build --network NAME`. * This can be used to check that a build doesn't access the network. (But keep in mind that most Dockerfiles will fail, <br/>because they need to install remote packages and dependencies!) * This may be used to access an internal package repository. (But try to use a multi-stage build instead, if possible!) ??? :EN:Container networking essentials :EN:- The Container Network Model :EN:- Container isolation :EN:- Service discovery :FR:Mettre ses conteneurs en réseau :FR:- Le "Container Network Model" :FR:- Isolation des conteneurs :FR:- *Service discovery* .debug[[containers/Container_Network_Model.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Network_Model.md)] --- class: pic .interstitial[] --- name: toc-ambassadors class: title Ambassadors .nav[ [Previous part](#toc-service-discovery-with-containers) | [Back to table of contents](#toc-part-5) | [Next part](#toc-local-development-workflow-with-docker) ] .debug[(automatically generated title slide)] --- class: title # Ambassadors  .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## The ambassador pattern Ambassadors are containers that "masquerade" or "proxy" for another service. They abstract the connection details for this services, and can help with: * discovery (where is my service actually running?) * migration (what if my service has to be moved while I use it?) * fail over (how do I know to which instance of a replicated service I should connect?) * load balancing (how do I spread my requests across multiple instances of a service?) * authentication (what if my service requires credentials, certificates, or otherwise?) .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Introduction to Ambassadors The ambassador pattern: * Takes advantage of Docker's per-container naming system and abstracts connections between services. * Allows you to manage services without hard-coding connection information inside applications. To do this, instead of directly connecting containers you insert ambassador containers. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- class: pic 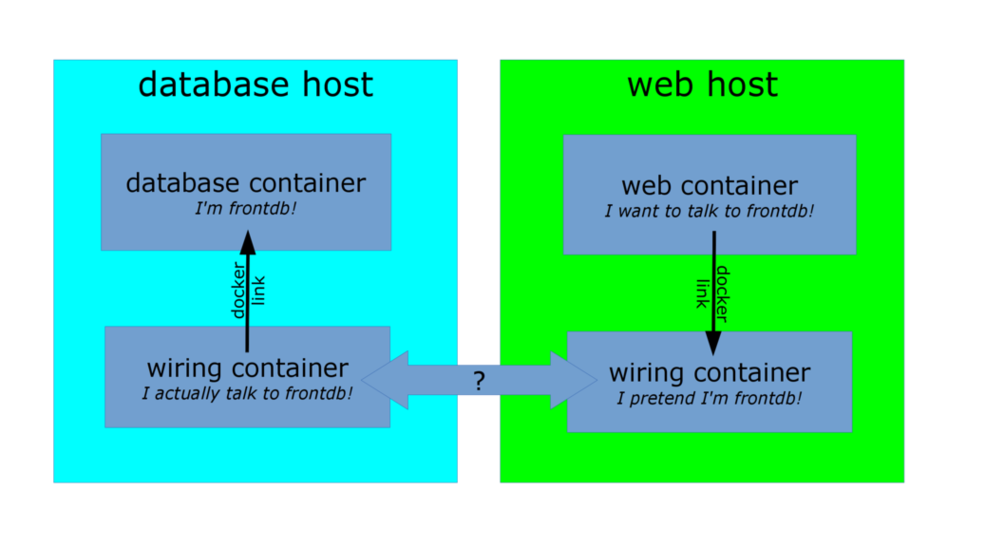 .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Interacting with ambassadors * The web container uses normal Docker networking to connect to the ambassador. * The database container also talks with an ambassador. * For both containers, the ambassador is totally transparent. <br/> (There is no difference between normal operation and operation with an ambassador.) * If the database container is moved (or a failover happens), its new location will be tracked by the ambassador containers, and the web application container will still be able to connect, without reconfiguration. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Ambassadors for simple service discovery Use case: * my application code connects to `redis` on the default port (6379), * my Redis service runs on another machine, on a non-default port (e.g. 12345), * I want to use an ambassador to let my application connect without modification. The ambassador will be: * a container running right next to my application, * using the name `redis` (or linked as `redis`), * listening on port 6379, * forwarding connections to the actual Redis service. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Ambassadors for service migration Use case: * my application code still connects to `redis`, * my Redis service runs somewhere else, * my Redis service is moved to a different host+port, * the location of the Redis service is given to me via e.g. DNS SRV records, * I want to use an ambassador to automatically connect to the new location, with as little disruption as possible. The ambassador will be: * the same kind of container as before, * running an additional routine to monitor DNS SRV records, * updating the forwarding destination when the DNS SRV records are updated. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Ambassadors for credentials injection Use case: * my application code still connects to `redis`, * my application code doesn't provide Redis credentials, * my production Redis service requires credentials, * my staging Redis service requires different credentials, * I want to use an ambassador to abstract those credentials. The ambassador will be: * a container using the name `redis` (or a link), * passed the credentials to use, * running a custom proxy that accepts connections on Redis default port, * performing authentication with the target Redis service before forwarding traffic. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Ambassadors for load balancing Use case: * my application code connects to a web service called `api`, * I want to run multiple instances of the `api` backend, * those instances will be on different machines and ports, * I want to use an ambassador to abstract those details. The ambassador will be: * a container using the name `api` (or a link), * passed the list of backends to use (statically or dynamically), * running a load balancer (e.g. HAProxy or NGINX), * dispatching requests across all backends transparently. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## "Ambassador" is a *pattern* There are many ways to implement the pattern. Different deployments will use different underlying technologies. * On-premise deployments with a trusted network can track container locations in e.g. Zookeeper, and generate HAproxy configurations each time a location key changes. * Public cloud deployments or deployments across unsafe networks can add TLS encryption. * Ad-hoc deployments can use a master-less discovery protocol like avahi to register and discover services. * It is also possible to do one-shot reconfiguration of the ambassadors. It is slightly less dynamic but has far fewer requirements. * Ambassadors can be used in addition to, or instead of, overlay networks. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Service meshes * A service mesh is a configurable network layer. * It can provide service discovery, high availability, load balancing, observability... * Service meshes are particularly useful for microservices applications. * Service meshes are often implemented as proxies. * Applications connect to the service mesh, which relays the connection where needed. *Does that sound familiar?* .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Ambassadors and service meshes * When using a service mesh, a "sidecar container" is often used as a proxy * Our services connect (transparently) to that sidecar container * That sidecar container figures out where to forward the traffic ... Does that sound familiar? (It should, because service meshes are essentially app-wide or cluster-wide ambassadors!) .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Some popular service meshes ... And related projects: * [Consul Connect](https://www.consul.io/docs/connect/index.html) <br/> Transparently secures service-to-service connections with mTLS. * [Gloo](https://gloo.solo.io/) <br/> API gateway that can interconnect applications on VMs, containers, and serverless. * [Istio](https://istio.io/) <br/> A popular service mesh. * [Linkerd](https://linkerd.io/) <br/> Another popular service mesh. .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- ## Learning more about service meshes A few blog posts about service meshes: * [Containers, microservices, and service meshes](http://jpetazzo.github.io/2019/05/17/containers-microservices-service-meshes/) <br/> Provides historical context: how did we do before service meshes were invented? * [Do I Need a Service Mesh?](https://www.nginx.com/blog/do-i-need-a-service-mesh/) <br/> Explains the purpose of service meshes. Illustrates some NGINX features. * [Do you need a service mesh?](https://www.oreilly.com/ideas/do-you-need-a-service-mesh) <br/> Includes high-level overview and definitions. * [What is Service Mesh and Why Do We Need It?](https://containerjournal.com/2018/12/12/what-is-service-mesh-and-why-do-we-need-it/) <br/> Includes a step-by-step demo of Linkerd. And a video: * [What is a Service Mesh, and Do I Need One When Developing Microservices?](https://www.datawire.io/envoyproxy/service-mesh/) .debug[[containers/Ambassadors.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ambassadors.md)] --- class: pic .interstitial[] --- name: toc-local-development-workflow-with-docker class: title Local development workflow with Docker .nav[ [Previous part](#toc-ambassadors) | [Back to table of contents](#toc-part-6) | [Next part](#toc-windows-containers) ] .debug[(automatically generated title slide)] --- class: title # Local development workflow with Docker  .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Objectives At the end of this section, you will be able to: * Share code between container and host. * Use a simple local development workflow. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Local development in a container We want to solve the following issues: - "Works on my machine" - "Not the same version" - "Missing dependency" By using Docker containers, we will get a consistent development environment. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Working on the "namer" application * We have to work on some application whose code is at: https://github.com/jpetazzo/namer. * What is it? We don't know yet! * Let's download the code. ```bash $ git clone https://github.com/jpetazzo/namer ``` .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Looking at the code ```bash $ cd namer $ ls -1 company_name_generator.rb config.ru docker-compose.yml Dockerfile Gemfile ``` -- Aha, a `Gemfile`! This is Ruby. Probably. We know this. Maybe? .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Looking at the `Dockerfile` ```dockerfile FROM ruby COPY . /src WORKDIR /src RUN bundler install CMD ["rackup", "--host", "0.0.0.0"] EXPOSE 9292 ``` * This application is using a base `ruby` image. * The code is copied in `/src`. * Dependencies are installed with `bundler`. * The application is started with `rackup`. * It is listening on port 9292. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Building and running the "namer" application * Let's build the application with the `Dockerfile`! -- ```bash $ docker build -t namer . ``` -- * Then run it. *We need to expose its ports.* -- ```bash $ docker run -dP namer ``` -- * Check on which port the container is listening. -- ```bash $ docker ps -l ``` .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Connecting to our application * Point our browser to our Docker node, on the port allocated to the container. -- * Hit "reload" a few times. -- * This is an enterprise-class, carrier-grade, ISO-compliant company name generator! (With 50% more bullshit than the average competition!) (Wait, was that 50% more, or 50% less? *Anyway!*)  .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Making changes to the code Option 1: * Edit the code locally * Rebuild the image * Re-run the container Option 2: * Enter the container (with `docker exec`) * Install an editor * Make changes from within the container Option 3: * Use a *bind mount* to share local files with the container * Make changes locally * Changes are reflected in the container .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Our first volume We will tell Docker to map the current directory to `/src` in the container. ```bash $ docker run -d -v $(pwd):/src -P namer ``` * `-d`: the container should run in detached mode (in the background). * `-v`: the following host directory should be mounted inside the container. * `-P`: publish all the ports exposed by this image. * `namer` is the name of the image we will run. * We don't specify a command to run because it is already set in the Dockerfile via `CMD`. Note: on Windows, replace `$(pwd)` with `%cd%` (or `${pwd}` if you use PowerShell). .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Mounting volumes inside containers The `-v` flag mounts a directory from your host into your Docker container. The flag structure is: ```bash [host-path]:[container-path]:[rw|ro] ``` * `[host-path]` and `[container-path]` are created if they don't exist. * You can control the write status of the volume with the `ro` and `rw` options. * If you don't specify `rw` or `ro`, it will be `rw` by default. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- class: extra-details ## Hold your horses... and your mounts - The `-v /path/on/host:/path/in/container` syntax is the "old" syntax - The modern syntax looks like this: `--mount type=bind,source=/path/on/host,target=/path/in/container` - `--mount` is more explicit, but `-v` is quicker to type - `--mount` supports all mount types; `-v` doesn't support `tmpfs` mounts - `--mount` fails if the path on the host doesn't exist; `-v` creates it With the new syntax, our command becomes: ```bash docker run --mount=type=bind,source=$(pwd),target=/src -dP namer ``` .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Testing the development container * Check the port used by our new container. ```bash $ docker ps -l CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 045885b68bc5 namer rackup 3 seconds ago Up ... 0.0.0.0:32770->9292/tcp ... ``` * Open the application in your web browser. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Making a change to our application Our customer really doesn't like the color of our text. Let's change it. ```bash $ vi company_name_generator.rb ``` And change ```css color: royalblue; ``` To: ```css color: red; ``` .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Viewing our changes * Reload the application in our browser. -- * The color should have changed.  .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Understanding volumes - Volumes are *not* copying or synchronizing files between the host and the container - Changes made in the host are immediately visible in the container (and vice versa) - When running on Linux: - volumes and bind mounts correspond to directories on the host - if Docker runs in a Linux VM, these directories are in the Linux VM - When running on Docker Desktop: - volumes correspond to directories in a small Linux VM running Docker - access to bind mounts is translated to host filesystem access <br/> (a bit like a network filesystem) .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- class: extra-details ## Docker Desktop caveats - When running Docker natively on Linux, accessing a mount = native I/O - When running Docker Desktop, accessing a bind mount = file access translation - That file access translation has relatively good performance *in general* (watch out, however, for that big `npm install` working on a bind mount!) - There are some corner cases when watching files (with mechanisms like inotify) - Features like "live reload" or programs like `entr` don't always behave properly (due to e.g. file attribute caching, and other interesting details!) .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Trash your servers and burn your code *(This is the title of a [2013 blog post][immutable-deployments] by Chad Fowler, where he explains the concept of immutable infrastructure.)* [immutable-deployments]: https://web.archive.org/web/20160305073617/http://chadfowler.com/blog/2013/06/23/immutable-deployments/ -- * Let's majorly mess up our container. (Remove files or whatever.) * Now, how can we fix this? -- * Our old container (with the blue version of the code) is still running. * See on which port it is exposed: ```bash docker ps ``` * Point our browser to it to confirm that it still works fine. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Immutable infrastructure in a nutshell * Instead of *updating* a server, we deploy a new one. * This might be challenging with classical servers, but it's trivial with containers. * In fact, with Docker, the most logical workflow is to build a new image and run it. * If something goes wrong with the new image, we can always restart the old one. * We can even keep both versions running side by side. If this pattern sounds interesting, you might want to read about *blue/green deployment* and *canary deployments*. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Recap of the development workflow 1. Write a Dockerfile to build an image containing our development environment. <br/> (Rails, Django, ... and all the dependencies for our app) 2. Start a container from that image. <br/> Use the `-v` flag to mount our source code inside the container. 3. Edit the source code outside the container, using familiar tools. <br/> (vim, emacs, textmate...) 4. Test the application. <br/> (Some frameworks pick up changes automatically. <br/>Others require you to Ctrl-C + restart after each modification.) 5. Iterate and repeat steps 3 and 4 until satisfied. 6. When done, commit+push source code changes. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- class: extra-details ## Debugging inside the container Docker has a command called `docker exec`. It allows users to run a new process in a container which is already running. If sometimes you find yourself wishing you could SSH into a container: you can use `docker exec` instead. You can get a shell prompt inside an existing container this way, or run an arbitrary process for automation. .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- class: extra-details ## `docker exec` example ```bash $ # You can run ruby commands in the area the app is running and more! $ docker exec -it <yourContainerId> bash root@5ca27cf74c2e:/opt/namer# irb irb(main):001:0> [0, 1, 2, 3, 4].map {|x| x ** 2}.compact => [0, 1, 4, 9, 16] irb(main):002:0> exit ``` .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- class: extra-details ## Stopping the container Now that we're done let's stop our container. ```bash $ docker stop <yourContainerID> ``` And remove it. ```bash $ docker rm <yourContainerID> ``` .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- ## Section summary We've learned how to: * Share code between container and host. * Set our working directory. * Use a simple local development workflow. ??? :EN:Developing with containers :EN:- “Containerize” a development environment :FR:Développer au jour le jour :FR:- « Containeriser » son environnement de développement .debug[[containers/Local_Development_Workflow.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Local_Development_Workflow.md)] --- class: pic .interstitial[] --- name: toc-windows-containers class: title Windows Containers .nav[ [Previous part](#toc-local-development-workflow-with-docker) | [Back to table of contents](#toc-part-6) | [Next part](#toc-working-with-volumes) ] .debug[(automatically generated title slide)] --- class: title # Windows Containers  .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## Objectives At the end of this section, you will be able to: * Understand Windows Container vs. Linux Container. * Know about the features of Docker for Windows for choosing architecture. * Run other container architectures via QEMU emulation. .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## Are containers *just* for Linux? Remember that a container must run on the kernel of the OS it's on. - This is both a benefit and a limitation. (It makes containers lightweight, but limits them to a specific kernel.) - At its launch in 2013, Docker did only support Linux, and only on amd64 CPUs. - Since then, many platforms and OS have been added. (Windows, ARM, i386, IBM mainframes ... But no macOS or iOS yet!) -- - Docker Desktop (macOS and Windows) can run containers for other architectures (Check the docs to see how to [run a Raspberry Pi (ARM) or PPC container](https://docs.docker.com/docker-for-mac/multi-arch/)!) .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## History of Windows containers - Early 2016, Windows 10 gained support for running Windows binaries in containers. - These are known as "Windows Containers" - Win 10 expects Docker for Windows to be installed for full features - These must run in Hyper-V mini-VM's with a Windows Server x64 kernel - No "scratch" containers, so use "Core" and "Nano" Server OS base layers - Since Hyper-V is required, Windows 10 Home won't work (yet...) -- - Late 2016, Windows Server 2016 ships with native Docker support - Installed via PowerShell, doesn't need Docker for Windows - Can run native (without VM), or with [Hyper-V Isolation](https://docs.microsoft.com/en-us/virtualization/windowscontainers/manage-containers/hyperv-container) .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## LCOW (Linux Containers On Windows) While Docker on Windows is largely playing catch up with Docker on Linux, it's moving fast; and this is one thing that you *cannot* do on Linux! - LCOW came with the [2017 Fall Creators Update](https://blog.docker.com/2018/02/docker-for-windows-18-02-with-windows-10-fall-creators-update/). - It can run Linux and Windows containers side-by-side on Win 10. - It is no longer necessary to switch the Engine to "Linux Containers". (In fact, if you want to run both Linux and Windows containers at the same time, make sure that your Engine is set to "Windows Containers" mode!) -- If you are a Docker for Windows user, start your engine and try this: ```bash docker pull microsoft/nanoserver:1803 ``` (Make sure to switch to "Windows Containers mode" if necessary.) .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## Run Both Windows and Linux containers - Run a Windows Nano Server (minimal CLI-only server) ```bash docker run --rm -it microsoft/nanoserver:1803 powershell Get-Process exit ``` - Run busybox on Linux in LCOW ```bash docker run --rm --platform linux busybox echo hello ``` (Although you will not be able to see them, this will create hidden Nano and LinuxKit VMs in Hyper-V!) .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## Did We Say Things Move Fast - Things keep improving. - Now `--platform` defaults to `windows`, some images support both: - golang, mongo, python, redis, hello-world ... and more being added - you should still use `--platform` with multi-os images to be certain - Windows Containers now support `localhost` accessible containers (July 2018) - Microsoft (April 2018) added Hyper-V support to Windows 10 Home ... ... so stay tuned for Docker support, maybe?!? .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## Other Windows container options Most "official" Docker images don't run on Windows yet. Places to Look: - Hub Official: https://hub.docker.com/u/winamd64/ - Microsoft: https://hub.docker.com/r/microsoft/ .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## SQL Server? Choice of Linux or Windows - Microsoft [SQL Server for Linux 2017](https://hub.docker.com/r/microsoft/mssql-server-linux/) (amd64/linux) - Microsoft [SQL Server Express 2017](https://hub.docker.com/r/microsoft/mssql-server-windows-express/) (amd64/windows) .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- ## Windows Tools and Tips - PowerShell [Tab Completion: DockerCompletion](https://github.com/matt9ucci/DockerCompletion) - Best Shell GUI: [Cmder.net](https://cmder.net/) - Good Windows Container Blogs and How-To's - Docker DevRel [Elton Stoneman, Microsoft MVP](https://blog.sixeyed.com/) - Docker Captain [Nicholas Dille](https://dille.name/blog/) - Docker Captain [Stefan Scherer](https://stefanscherer.github.io/) .debug[[containers/Windows_Containers.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Windows_Containers.md)] --- class: pic .interstitial[] --- name: toc-working-with-volumes class: title Working with volumes .nav[ [Previous part](#toc-windows-containers) | [Back to table of contents](#toc-part-6) | [Next part](#toc-gentle-introduction-to-yaml) ] .debug[(automatically generated title slide)] --- class: title # Working with volumes  .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Objectives At the end of this section, you will be able to: * Create containers holding volumes. * Share volumes across containers. * Share a host directory with one or many containers. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Working with volumes Docker volumes can be used to achieve many things, including: * Bypassing the copy-on-write system to obtain native disk I/O performance. * Bypassing copy-on-write to leave some files out of `docker commit`. * Sharing a directory between multiple containers. * Sharing a directory between the host and a container. * Sharing a *single file* between the host and a container. * Using remote storage and custom storage with *volume drivers*. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Volumes are special directories in a container Volumes can be declared in two different ways: * Within a `Dockerfile`, with a `VOLUME` instruction. ```dockerfile VOLUME /uploads ``` * On the command-line, with the `-v` flag for `docker run`. ```bash $ docker run -d -v /uploads myapp ``` In both cases, `/uploads` (inside the container) will be a volume. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Volumes bypass the copy-on-write system Volumes act as passthroughs to the host filesystem. * The I/O performance on a volume is exactly the same as I/O performance on the Docker host. * When you `docker commit`, the content of volumes is not brought into the resulting image. * If a `RUN` instruction in a `Dockerfile` changes the content of a volume, those changes are not recorded neither. * If a container is started with the `--read-only` flag, the volume will still be writable (unless the volume is a read-only volume). .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Volumes can be shared across containers You can start a container with *exactly the same volumes* as another one. The new container will have the same volumes, in the same directories. They will contain exactly the same thing, and remain in sync. Under the hood, they are actually the same directories on the host anyway. This is done using the `--volumes-from` flag for `docker run`. We will see an example in the following slides. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Sharing app server logs with another container Let's start a Tomcat container: ```bash $ docker run --name webapp -d -p 8080:8080 -v /usr/local/tomcat/logs tomcat ``` Now, start an `alpine` container accessing the same volume: ```bash $ docker run --volumes-from webapp alpine sh -c "tail -f /usr/local/tomcat/logs/*" ``` Then, from another window, send requests to our Tomcat container: ```bash $ curl localhost:8080 ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Volumes exist independently of containers If a container is stopped or removed, its volumes still exist and are available. Volumes can be listed and manipulated with `docker volume` subcommands: ```bash $ docker volume ls DRIVER VOLUME NAME local 5b0b65e4316da67c2d471086640e6005ca2264f3... local pgdata-prod local pgdata-dev local 13b59c9936d78d109d094693446e174e5480d973... ``` Some of those volume names were explicit (pgdata-prod, pgdata-dev). The others (the hex IDs) were generated automatically by Docker. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Naming volumes * Volumes can be created without a container, then used in multiple containers. Let's create a couple of volumes directly. ```bash $ docker volume create webapps webapps ``` ```bash $ docker volume create logs logs ``` Volumes are not anchored to a specific path. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Populating volumes * When an empty volume is mounted on a non-empty directory, the directory is copied to the volume. * This makes it easy to "promote" a normal directory to a volume. * Non-empty volumes are always mounted as-is. Let's populate the webapps volume with the webapps.dist directory from the Tomcat image. ````bash $ docker run -v webapps:/usr/local/tomcat/webapps.dist tomcat true ``` Note: running `true` will cause the container to exit successfully once the `webapps.dist` directory has been copied to the `webapps` volume, instead of starting tomcat. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Using our named volumes * Volumes are used with the `-v` option. * When a host path does not contain a `/`, it is considered a volume name. Let's start a web server using the two previous volumes. ```bash $ docker run -d -p 1234:8080 \ -v logs:/usr/local/tomcat/logs \ -v webapps:/usr/local/tomcat/webapps \ tomcat ``` Check that it's running correctly: ```bash $ curl localhost:1234 ... (Tomcat tells us how happy it is to be up and running) ... ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Using a volume in another container * We will make changes to the volume from another container. * In this example, we will run a text editor in the other container. (But this could be an FTP server, a WebDAV server, a Git receiver...) Let's start another container using the `webapps` volume. ```bash $ docker run -v webapps:/webapps -w /webapps -ti alpine vi ROOT/index.jsp ``` Vandalize the page, save, exit. Then run `curl localhost:1234` again to see your changes. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Using custom "bind-mounts" In some cases, you want a specific directory on the host to be mapped inside the container: * You want to manage storage and snapshots yourself. (With LVM, or a SAN, or ZFS, or anything else!) * You have a separate disk with better performance (SSD) or resiliency (EBS) than the system disk, and you want to put important data on that disk. * You want to share your source directory between your host (where the source gets edited) and the container (where it is compiled or executed). Wait, we already met the last use-case in our example development workflow! Nice. ```bash $ docker run -d -v /path/on/the/host:/path/in/container image ... ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Migrating data with `--volumes-from` The `--volumes-from` option tells Docker to re-use all the volumes of an existing container. * Scenario: migrating from Redis 2.8 to Redis 3.0. * We have a container (`myredis`) running Redis 2.8. * Stop the `myredis` container. * Start a new container, using the Redis 3.0 image, and the `--volumes-from` option. * The new container will inherit the data of the old one. * Newer containers can use `--volumes-from` too. * Doesn't work across servers, so not usable in clusters (Swarm, Kubernetes). .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Data migration in practice Let's create a Redis container. ```bash $ docker run -d --name redis28 redis:2.8 ``` Connect to the Redis container and set some data. ```bash $ docker run -ti --link redis28:redis busybox telnet redis 6379 ``` Issue the following commands: ```bash SET counter 42 INFO server SAVE QUIT ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Upgrading Redis Stop the Redis container. ```bash $ docker stop redis28 ``` Start the new Redis container. ```bash $ docker run -d --name redis30 --volumes-from redis28 redis:3.0 ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Testing the new Redis Connect to the Redis container and see our data. ```bash docker run -ti --link redis30:redis busybox telnet redis 6379 ``` Issue a few commands. ```bash GET counter INFO server QUIT ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Volumes lifecycle * When you remove a container, its volumes are kept around. * You can list them with `docker volume ls`. * You can access them by creating a container with `docker run -v`. * You can remove them with `docker volume rm` or `docker system prune`. Ultimately, _you_ are the one responsible for logging, monitoring, and backup of your volumes. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Checking volumes defined by an image Wondering if an image has volumes? Just use `docker inspect`: ```bash $ # docker inspect training/datavol [{ "config": { . . . "Volumes": { "/var/webapp": {} }, . . . }] ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: extra-details ## Checking volumes used by a container To look which paths are actually volumes, and to what they are bound, use `docker inspect` (again): ```bash $ docker inspect <yourContainerID> [{ "ID": "<yourContainerID>", . . . "Volumes": { "/var/webapp": "/var/lib/docker/vfs/dir/f4280c5b6207ed531efd4cc673ff620cef2a7980f747dbbcca001db61de04468" }, "VolumesRW": { "/var/webapp": true }, }] ``` * We can see that our volume is present on the file system of the Docker host. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Sharing a single file The same `-v` flag can be used to share a single file (instead of a directory). One of the most interesting examples is to share the Docker control socket. ```bash $ docker run -it -v /var/run/docker.sock:/var/run/docker.sock docker sh ``` From that container, you can now run `docker` commands communicating with the Docker Engine running on the host. Try `docker ps`! .warning[Since that container has access to the Docker socket, it has root-like access to the host.] .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Volume plugins You can install plugins to manage volumes backed by particular storage systems, or providing extra features. For instance: * [REX-Ray](https://rexray.io/) - create and manage volumes backed by an enterprise storage system (e.g. SAN or NAS), or by cloud block stores (e.g. EBS, EFS). * [Portworx](https://portworx.com/) - provides distributed block store for containers. * [Gluster](https://www.gluster.org/) - open source software-defined distributed storage that can scale to several petabytes. It provides interfaces for object, block and file storage. * and much more at the [Docker Store](https://store.docker.com/search?category=volume&q=&type=plugin)! .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Volumes vs. Mounts * Since Docker 17.06, a new options is available: `--mount`. * It offers a new, richer syntax to manipulate data in containers. * It makes an explicit difference between: - volumes (identified with a unique name, managed by a storage plugin), - bind mounts (identified with a host path, not managed). * The former `-v` / `--volume` option is still usable. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## `--mount` syntax Binding a host path to a container path: ```bash $ docker run \ --mount type=bind,source=/path/on/host,target=/path/in/container alpine ``` Mounting a volume to a container path: ```bash $ docker run \ --mount source=myvolume,target=/path/in/container alpine ``` Mounting a tmpfs (in-memory, for temporary files): ```bash $ docker run \ --mount type=tmpfs,destination=/path/in/container,tmpfs-size=1000000 alpine ``` .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- ## Section summary We've learned how to: * Create and manage volumes. * Share volumes across containers. * Share a host directory with one or many containers. .debug[[containers/Working_With_Volumes.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Working_With_Volumes.md)] --- class: pic .interstitial[] --- name: toc-gentle-introduction-to-yaml class: title Gentle introduction to YAML .nav[ [Previous part](#toc-working-with-volumes) | [Back to table of contents](#toc-part-6) | [Next part](#toc-compose-for-development-stacks) ] .debug[(automatically generated title slide)] --- # Gentle introduction to YAML - YAML Ain't Markup Language (according to [yaml.org][yaml]) - *Almost* required when working with containers: - Docker Compose files - Kubernetes manifests - Many CI pipelines (GitHub, GitLab...) - If you don't know much about YAML, this is for you! [yaml]: https://yaml.org/ .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## What is it? - Data representation language ```yaml - country: France capital: Paris code: fr population: 68042591 - country: Germany capital: Berlin code: de population: 84270625 - country: Norway capital: Oslo code: no # It's a trap! population: 5425270 ``` - Even without knowing YAML, we probably can add a country to that file :) .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Trying YAML - Method 1: in the browser https://onlineyamltools.com/convert-yaml-to-json https://onlineyamltools.com/highlight-yaml - Method 2: in a shell ```bash yq . foo.yaml ``` - Method 3: in Python ```python import yaml; yaml.safe_load(""" - country: France capital: Paris """) ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Basic stuff - Strings, numbers, boolean values, `null` - Sequences (=arrays, lists) - Mappings (=objects) - Superset of JSON (if you know JSON, you can just write JSON) - Comments start with `#` - A single *file* can have multiple *documents* (separated by `---` on a single line) .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Sequences - Example: sequence of strings ```yaml [ "france", "germany", "norway" ] ``` - Example: the same sequence, without the double-quotes ```yaml [ france, germany, norway ] ``` - Example: the same sequence, in "block collection style" (=multi-line) ```yaml - france - germany - norway ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Mappings - Example: mapping strings to numbers ```yaml { "france": 68042591, "germany": 84270625, "norway": 5425270 } ``` - Example: the same mapping, without the double-quotes ```yaml { france: 68042591, germany: 84270625, norway: 5425270 } ``` - Example: the same mapping, in "block collection style" ```yaml france: 68042591 germany: 84270625 norway: 5425270 ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Combining types - In a sequence (or mapping) we can have different types (including other sequences or mappings) - Example: ```yaml questions: [ name, quest, favorite color ] answers: [ "Arthur, King of the Britons", Holy Grail, purple, 42 ] ``` - Note that we need to quote "Arthur" because of the comma - Note that we don't have the same number of elements in questions and answers .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## More combinations - Example: ```yaml - service: nginx ports: [ 80, 443 ] - service: bind ports: [ 53/tcp, 53/udp ] - service: ssh ports: 22 ``` - Note that `ports` doesn't always have the same type (the code handling that data will probably have to be smart!) .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## ⚠️ Automatic booleans ```yaml codes: france: fr germany: de norway: no ``` -- ```json { "codes": { "france": "fr", "germany": "de", "norway": false } } ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## ⚠️ Automatic booleans - `no` can become `false` (it depends on the YAML parser used) - It should be quoted instead: ```yaml codes: france: fr germany: de norway: "no" ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## ⚠️ Automatic floats ```yaml version: libfoo: 1.10 fooctl: 1.0 ``` -- ```json { "version": { "libfoo": 1.1, "fooctl": 1 } } ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## ⚠️ Automatic floats - Trailing zeros disappear - These should also be quoted: ```yaml version: libfoo: "1.10" fooctl: "1.0" ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## ⚠️ Automatic times ```yaml portmap: - 80:80 - 22:22 ``` -- ```json { "portmap": [ "80:80", 1342 ] } ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## ⚠️ Automatic times - `22:22` becomes `1342` - Thats 22 minutes and 22 seconds = 1342 seconds - Again, it should be quoted .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Document separator - A single YAML *file* can have multiple *documents* separated by `---`: ```yaml This is a document consisting of a single string. --- 💡 name: The second document type: This one is a mapping (key→value) --- 💡 - Third document - This one is a sequence ``` - Some folks like to add an extra `---` at the beginning and/or at the end (it's not mandatory but can help e.g. to `cat` multiple files together) .footnote[💡 Ignore this; it's here to work around [this issue][remarkyaml].] [remarkyaml]: https://github.com/gnab/remark/issues/679 .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- ## Multi-line strings Try the following block in a YAML parser: ```yaml add line breaks: "in double quoted strings\n(like this)" preserve line break: | by using a pipe (|) (this is great for embedding shell scripts, configuration files...) do not preserve line breaks: > by using a greater-than (>) (this is great for embedding very long lines) ``` See https://yaml-multiline.info/ for advanced multi-line tips! (E.g. to strip or keep extra `\n` characters at the end of the block.) .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- class: extra-details ## Advanced features Anchors let you "memorize" and re-use content: ```yaml debian: &debian packages: deb latest-stable: bullseye also-debian: *debian ubuntu: <<: *debian latest-stable: jammy ``` .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- class: extra-details ## YAML, good or evil? - Natural progression from XML to JSON to YAML - There are other data languages out there (e.g. HCL, domain-specific things crafted with Ruby, CUE...) - Compromises are made, for instance: - more user-friendly → more "magic" with side effects - more powerful → steeper learning curve - Love it or loathe it but it's a good idea to understand it! - Interesting tool if you appreciate YAML: https://carvel.dev/ytt/ ??? :EN:- Understanding YAML and its gotchas :FR:- Comprendre le YAML et ses subtilités .debug[[shared/yaml.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/yaml.md)] --- class: pic .interstitial[] --- name: toc-compose-for-development-stacks class: title Compose for development stacks .nav[ [Previous part](#toc-gentle-introduction-to-yaml) | [Back to table of contents](#toc-part-6) | [Next part](#toc-exercise--writing-a-compose-file) ] .debug[(automatically generated title slide)] --- # Compose for development stacks Dockerfile = great to build *one* container image. What if we have multiple containers? What if some of them require particular `docker run` parameters? How do we connect them all together? ... Compose solves these use-cases (and a few more). .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Life before Compose Before we had Compose, we would typically write custom scripts to: - build container images, - run containers using these images, - connect the containers together, - rebuild, restart, update these images and containers. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Life with Compose Compose enables a simple, powerful onboarding workflow: 1. Checkout our code. 2. Run `docker compose up`. 3. Our app is up and running! .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- class: pic  .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Life after Compose (Or: when do we need something else?) - Compose is *not* an orchestrator - It isn't designed to need to run containers on multiple nodes (it can, however, work with Docker Swarm Mode) - Compose isn't ideal if we want to run containers on Kubernetes - it uses different concepts (Compose services ≠ Kubernetes services) - it needs a Docker Engine (although containerd support might be coming) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## First rodeo with Compose 1. Write Dockerfiles 2. Describe our stack of containers in a YAML file (the "Compose file") 3. `docker compose up` (or `docker compose up -d` to run in the background) 4. Compose pulls and builds the required images, and starts the containers 5. Compose shows the combined logs of all the containers (if running in the background, use `docker compose logs`) 6. Hit Ctrl-C to stop the whole stack (if running in the background, use `docker compose stop`) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Iterating After making changes to our source code, we can: 1. `docker compose build` to rebuild container images 2. `docker compose up` to restart the stack with the new images We can also combine both with `docker compose up --build` Compose will be smart, and only recreate the containers that have changed. When working with interpreted languages: - don't rebuild each time - leverage a `volumes` section instead .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Launching Our First Stack with Compose First step: clone the source code for the app we will be working on. ```bash git clone https://github.com/jpetazzo/trainingwheels cd trainingwheels ``` Second step: start the app. ```bash docker compose up ``` Watch Compose build and run the app. That Compose stack exposes a web server on port 8000; try connecting to it. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Launching Our First Stack with Compose We should see a web page like this:  Each time we reload, the counter should increase. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Stopping the app When we hit Ctrl-C, Compose tries to gracefully terminate all of the containers. After ten seconds (or if we press `^C` again) it will forcibly kill them. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## The Compose file * Historically: docker-compose.yml or .yaml * Recently (kind of): can also be named compose.yml or .yaml (Since [version 1.28.6, March 2021](https://docs.docker.com/compose/releases/release-notes/#1286)) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Example Here is the file used in the demo: .small[ ```yaml version: "3" services: www: build: www ports: - ${PORT-8000}:5000 user: nobody environment: DEBUG: 1 command: python counter.py volumes: - ./www:/src redis: image: redis ``` ] .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Compose file structure A Compose file has multiple sections: * `services` is mandatory. Each service corresponds to a container. * `version` is optional (it used to be mandatory). It can be ignored. * `networks` is optional and indicates to which networks containers should be connected. <br/>(By default, containers will be connected on a private, per-compose-file network.) * `volumes` is optional and can define volumes to be used and/or shared by the containers. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- class: extra-details ## Compose file versions * Version 1 is legacy and shouldn't be used. (If you see a Compose file without a `services` block, it's a legacy v1 file.) * Version 2 added support for networks and volumes. * Version 3 added support for deployment options (scaling, rolling updates, etc). The [Docker documentation](https://docs.docker.com/compose/compose-file/) has excellent information about the Compose file format if you need to know more about versions. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Containers in Compose file Each service in the YAML file must contain either `build`, or `image`. * `build` indicates a path containing a Dockerfile. * `image` indicates an image name (local, or on a registry). * If both are specified, an image will be built from the `build` directory and named `image`. The other parameters are optional. They encode the parameters that you would typically add to `docker run`. Sometimes they have several minor improvements. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Container parameters * `command` indicates what to run (like `CMD` in a Dockerfile). * `ports` translates to one (or multiple) `-p` options to map ports. <br/>You can specify local ports (i.e. `x:y` to expose public port `x`). * `volumes` translates to one (or multiple) `-v` options. <br/>You can use relative paths here. For the full list, check: https://docs.docker.com/compose/compose-file/ .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Environment variables - We can use environment variables in Compose files (like `$THIS` or `${THAT}`) - We can provide default values, e.g. `${PORT-8000}` - Compose will also automatically load the environment file `.env` (it should contain `VAR=value`, one per line) - This is a great way to customize build and run parameters (base image versions to use, build and run secrets, port numbers...) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Configuring a Compose stack - Follow [12-factor app configuration principles][12factorconfig] (configure the app through environment variables) - Provide (in the repo) a default environment file suitable for development (no secret or sensitive value) - Copy the default environment file to `.env` and tweak it (or: provide a script to generate `.env` from a template) [12factorconfig]: https://12factor.net/config .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Running multiple copies of a stack - Copy the stack in two different directories, e.g. `front` and `frontcopy` - Compose prefixes images and containers with the directory name: `front_www`, `front_www_1`, `front_db_1` `frontcopy_www`, `frontcopy_www_1`, `frontcopy_db_1` - Alternatively, use `docker compose -p frontcopy` (to set the `--project-name` of a stack, which default to the dir name) - Each copy is isolated from the others (runs on a different network) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Checking stack status We have `ps`, `docker ps`, and similarly, `docker compose ps`: ```bash $ docker compose ps Name Command State Ports ---------------------------------------------------------------------------- trainingwheels_redis_1 /entrypoint.sh red Up 6379/tcp trainingwheels_www_1 python counter.py Up 0.0.0.0:8000->5000/tcp ``` Shows the status of all the containers of our stack. Doesn't show the other containers. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Cleaning up (1) If you have started your application in the background with Compose and want to stop it easily, you can use the `kill` command: ```bash $ docker compose kill ``` Likewise, `docker compose rm` will let you remove containers (after confirmation): ```bash $ docker compose rm Going to remove trainingwheels_redis_1, trainingwheels_www_1 Are you sure? [yN] y Removing trainingwheels_redis_1... Removing trainingwheels_www_1... ``` .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Cleaning up (2) Alternatively, `docker compose down` will stop and remove containers. It will also remove other resources, like networks that were created for the application. ```bash $ docker compose down Stopping trainingwheels_www_1 ... done Stopping trainingwheels_redis_1 ... done Removing trainingwheels_www_1 ... done Removing trainingwheels_redis_1 ... done ``` Use `docker compose down -v` to remove everything including volumes. .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Special handling of volumes - When an image gets updated, Compose automatically creates a new container - The data in the old container is lost... - ...Except if the container is using a *volume* - Compose will then re-attach that volume to the new container (and data is then retained across database upgrades) - All good database images use volumes (e.g. all official images) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Gotchas with volumes - Unfortunately, Docker volumes don't have labels or metadata - Compose tracks volumes thanks to their associated container - If the container is deleted, the volume gets orphaned - Example: `docker compose down && docker compose up` - the old volume still exists, detached from its container - a new volume gets created - `docker compose down -v`/`--volumes` deletes volumes (but **not** `docker compose down && docker compose down -v`!) .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Managing volumes explicitly Option 1: *named volumes* ```yaml services: app: volumes: - data:/some/path volumes: data: ``` - Volume will be named `<project>_data` - It won't be orphaned with `docker compose down` - It will correctly be removed with `docker compose down -v` .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Managing volumes explicitly Option 2: *relative paths* ```yaml services: app: volumes: - ./data:/some/path ``` - Makes it easy to colocate the app and its data (for migration, backups, disk usage accounting...) - Won't be removed by `docker compose down -v` .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Managing complex stacks - Compose provides multiple features to manage complex stacks (with many containers) - `-f`/`--file`/`$COMPOSE_FILE` can be a list of Compose files (separated by `:` and merged together) - Services can be assigned to one or more *profiles* - `--profile`/`$COMPOSE_PROFILE` can be a list of comma-separated profiles (see [Using service profiles][profiles] in the Compose documentation) - These variables can be set in `.env` [profiles]: https://docs.docker.com/compose/profiles/ .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- ## Dependencies - A service can have a `depends_on` section (listing one or more other services) - This is used when bringing up individual services (e.g. `docker compose up blah` or `docker compose run foo`) ⚠️ It doesn't make a service "wait" for another one to be up! .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- class: extra-details ## A bit of history and trivia - Compose was initially named "Fig" - Compose is one of the only components of Docker written in Python (almost everything else is in Go) - In 2020, Docker introduced "Compose CLI": - `docker compose` command to deploy Compose stacks to some clouds - in Go instead of Python - progressively getting feature parity with `docker compose` - also provides numerous improvements (e.g. leverages BuildKit by default) ??? :EN:- Using compose to describe an environment :EN:- Connecting services together with a *Compose file* :FR:- Utiliser Compose pour décrire son environnement :FR:- Écrire un *Compose file* pour connecter les services entre eux .debug[[containers/Compose_For_Dev_Stacks.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Compose_For_Dev_Stacks.md)] --- class: pic .interstitial[] --- name: toc-exercise--writing-a-compose-file class: title Exercise — writing a Compose file .nav[ [Previous part](#toc-compose-for-development-stacks) | [Back to table of contents](#toc-part-6) | [Next part](#toc-managing-hosts-with-docker-machine) ] .debug[(automatically generated title slide)] --- # Exercise — writing a Compose file Let's write a Compose file for the wordsmith app! The code is at: https://github.com/jpetazzo/wordsmith .debug[[containers/Exercise_Composefile.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Composefile.md)] --- class: pic .interstitial[] --- name: toc-managing-hosts-with-docker-machine class: title Managing hosts with Docker Machine .nav[ [Previous part](#toc-exercise--writing-a-compose-file) | [Back to table of contents](#toc-part-6) | [Next part](#toc-advanced-dockerfile-syntax) ] .debug[(automatically generated title slide)] --- # Managing hosts with Docker Machine - Docker Machine is a tool to provision and manage Docker hosts. - It automates the creation of a virtual machine: - locally, with a tool like VirtualBox or VMware; - on a public cloud like AWS EC2, Azure, Digital Ocean, GCP, etc.; - on a private cloud like OpenStack. - It can also configure existing machines through an SSH connection. - It can manage as many hosts as you want, with as many "drivers" as you want. .debug[[containers/Docker_Machine.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Machine.md)] --- ## Docker Machine workflow 1) Prepare the environment: setup VirtualBox, obtain cloud credentials ... 2) Create hosts with `docker-machine create -d drivername machinename`. 3) Use a specific machine with `eval $(docker-machine env machinename)`. 4) Profit! .debug[[containers/Docker_Machine.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Machine.md)] --- ## Environment variables - Most of the tools (CLI, libraries...) connecting to the Docker API can use environment variables. - These variables are: - `DOCKER_HOST` (indicates address+port to connect to, or path of UNIX socket) - `DOCKER_TLS_VERIFY` (indicates that TLS mutual auth should be used) - `DOCKER_CERT_PATH` (path to the keypair and certificate to use for auth) - `docker-machine env ...` will generate the variables needed to connect to a host. - `$(eval docker-machine env ...)` sets these variables in the current shell. .debug[[containers/Docker_Machine.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Machine.md)] --- ## Host management features With `docker-machine`, we can: - upgrade a host to the latest version of the Docker Engine, - start/stop/restart hosts, - get a shell on a remote machine (with SSH), - copy files to/from remotes machines (with SCP), - mount a remote host's directory on the local machine (with SSHFS), - ... .debug[[containers/Docker_Machine.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Machine.md)] --- ## The `generic` driver When provisioning a new host, `docker-machine` executes these steps: 1) Create the host using a cloud or hypervisor API. 2) Connect to the host over SSH. 3) Install and configure Docker on the host. With the `generic` driver, we provide the IP address of an existing host (instead of e.g. cloud credentials) and we omit the first step. This allows to provision physical machines, or VMs provided by a 3rd party, or use a cloud for which we don't have a provisioning API. .debug[[containers/Docker_Machine.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Docker_Machine.md)] --- class: pic .interstitial[] --- name: toc-advanced-dockerfile-syntax class: title Advanced Dockerfile Syntax .nav[ [Previous part](#toc-managing-hosts-with-docker-machine) | [Back to table of contents](#toc-part-7) | [Next part](#toc-buildkit) ] .debug[(automatically generated title slide)] --- class: title # Advanced Dockerfile Syntax  .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## Objectives We have seen simple Dockerfiles to illustrate how Docker build container images. In this section, we will give a recap of the Dockerfile syntax, and introduce advanced Dockerfile commands that we might come across sometimes; or that we might want to use in some specific scenarios. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## `Dockerfile` usage summary * `Dockerfile` instructions are executed in order. * Each instruction creates a new layer in the image. * Docker maintains a cache with the layers of previous builds. * When there are no changes in the instructions and files making a layer, the builder re-uses the cached layer, without executing the instruction for that layer. * The `FROM` instruction MUST be the first non-comment instruction. * Lines starting with `#` are treated as comments. * Some instructions (like `CMD` or `ENTRYPOINT`) update a piece of metadata. (As a result, each call to these instructions makes the previous one useless.) .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `RUN` instruction The `RUN` instruction can be specified in two ways. With shell wrapping, which runs the specified command inside a shell, with `/bin/sh -c`: ```dockerfile RUN apt-get update ``` Or using the `exec` method, which avoids shell string expansion, and allows execution in images that don't have `/bin/sh`: ```dockerfile RUN [ "apt-get", "update" ] ``` .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## More about the `RUN` instruction `RUN` will do the following: * Execute a command. * Record changes made to the filesystem. * Work great to install libraries, packages, and various files. `RUN` will NOT do the following: * Record state of *processes*. * Automatically start daemons. If you want to start something automatically when the container runs, you should use `CMD` and/or `ENTRYPOINT`. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## Collapsing layers It is possible to execute multiple commands in a single step: ```dockerfile RUN apt-get update && apt-get install -y wget && apt-get clean ``` It is also possible to break a command onto multiple lines: ```dockerfile RUN apt-get update \ && apt-get install -y wget \ && apt-get clean ``` .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `EXPOSE` instruction The `EXPOSE` instruction tells Docker what ports are to be published in this image. ```dockerfile EXPOSE 8080 EXPOSE 80 443 EXPOSE 53/tcp 53/udp ``` * All ports are private by default. * Declaring a port with `EXPOSE` is not enough to make it public. * The `Dockerfile` doesn't control on which port a service gets exposed. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## Exposing ports * When you `docker run -p <port> ...`, that port becomes public. (Even if it was not declared with `EXPOSE`.) * When you `docker run -P ...` (without port number), all ports declared with `EXPOSE` become public. A *public port* is reachable from other containers and from outside the host. A *private port* is not reachable from outside. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `COPY` instruction The `COPY` instruction adds files and content from your host into the image. ```dockerfile COPY . /src ``` This will add the contents of the *build context* (the directory passed as an argument to `docker build`) to the directory `/src` in the container. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## Build context isolation Note: you can only reference files and directories *inside* the build context. Absolute paths are taken as being anchored to the build context, so the two following lines are equivalent: ```dockerfile COPY . /src COPY / /src ``` Attempts to use `..` to get out of the build context will be detected and blocked with Docker, and the build will fail. Otherwise, a `Dockerfile` could succeed on host A, but fail on host B. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## `ADD` `ADD` works almost like `COPY`, but has a few extra features. `ADD` can get remote files: ```dockerfile ADD http://www.example.com/webapp.jar /opt/ ``` This would download the `webapp.jar` file and place it in the `/opt` directory. `ADD` will automatically unpack zip files and tar archives: ```dockerfile ADD ./assets.zip /var/www/htdocs/assets/ ``` This would unpack `assets.zip` into `/var/www/htdocs/assets`. *However,* `ADD` will not automatically unpack remote archives. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## `ADD`, `COPY`, and the build cache * Before creating a new layer, Docker checks its build cache. * For most Dockerfile instructions, Docker only looks at the `Dockerfile` content to do the cache lookup. * For `ADD` and `COPY` instructions, Docker also checks if the files to be added to the container have been changed. * `ADD` always needs to download the remote file before it can check if it has been changed. (It cannot use, e.g., ETags or If-Modified-Since headers.) .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## `VOLUME` The `VOLUME` instruction tells Docker that a specific directory should be a *volume*. ```dockerfile VOLUME /var/lib/mysql ``` Filesystem access in volumes bypasses the copy-on-write layer, offering native performance to I/O done in those directories. Volumes can be attached to multiple containers, allowing to "port" data over from a container to another, e.g. to upgrade a database to a newer version. It is possible to start a container in "read-only" mode. The container filesystem will be made read-only, but volumes can still have read/write access if necessary. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `WORKDIR` instruction The `WORKDIR` instruction sets the working directory for subsequent instructions. It also affects `CMD` and `ENTRYPOINT`, since it sets the working directory used when starting the container. ```dockerfile WORKDIR /src ``` You can specify `WORKDIR` again to change the working directory for further operations. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `ENV` instruction The `ENV` instruction specifies environment variables that should be set in any container launched from the image. ```dockerfile ENV WEBAPP_PORT 8080 ``` This will result in an environment variable being created in any containers created from this image of ```bash WEBAPP_PORT=8080 ``` You can also specify environment variables when you use `docker run`. ```bash $ docker run -e WEBAPP_PORT=8000 -e WEBAPP_HOST=www.example.com ... ``` .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `USER` instruction The `USER` instruction sets the user name or UID to use when running the image. It can be used multiple times to change back to root or to another user. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `CMD` instruction The `CMD` instruction is a default command run when a container is launched from the image. ```dockerfile CMD [ "nginx", "-g", "daemon off;" ] ``` Means we don't need to specify `nginx -g "daemon off;"` when running the container. Instead of: ```bash $ docker run <dockerhubUsername>/web_image nginx -g "daemon off;" ``` We can just do: ```bash $ docker run <dockerhubUsername>/web_image ``` .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## More about the `CMD` instruction Just like `RUN`, the `CMD` instruction comes in two forms. The first executes in a shell: ```dockerfile CMD nginx -g "daemon off;" ``` The second executes directly, without shell processing: ```dockerfile CMD [ "nginx", "-g", "daemon off;" ] ``` .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- class: extra-details ## Overriding the `CMD` instruction The `CMD` can be overridden when you run a container. ```bash $ docker run -it <dockerhubUsername>/web_image bash ``` Will run `bash` instead of `nginx -g "daemon off;"`. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## The `ENTRYPOINT` instruction The `ENTRYPOINT` instruction is like the `CMD` instruction, but arguments given on the command line are *appended* to the entry point. Note: you have to use the "exec" syntax (`[ "..." ]`). ```dockerfile ENTRYPOINT [ "/bin/ls" ] ``` If we were to run: ```bash $ docker run training/ls -l ``` Instead of trying to run `-l`, the container will run `/bin/ls -l`. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- class: extra-details ## Overriding the `ENTRYPOINT` instruction The entry point can be overridden as well. ```bash $ docker run -it training/ls bin dev home lib64 mnt proc run srv tmp var boot etc lib media opt root sbin sys usr $ docker run -it --entrypoint bash training/ls root@d902fb7b1fc7:/# ``` .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## How `CMD` and `ENTRYPOINT` interact The `CMD` and `ENTRYPOINT` instructions work best when used together. ```dockerfile ENTRYPOINT [ "nginx" ] CMD [ "-g", "daemon off;" ] ``` The `ENTRYPOINT` specifies the command to be run and the `CMD` specifies its options. On the command line we can then potentially override the options when needed. ```bash $ docker run -d <dockerhubUsername>/web_image -t ``` This will override the options `CMD` provided with new flags. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- ## Advanced Dockerfile instructions * `ONBUILD` lets you stash instructions that will be executed when this image is used as a base for another one. * `LABEL` adds arbitrary metadata to the image. * `ARG` defines build-time variables (optional or mandatory). * `STOPSIGNAL` sets the signal for `docker stop` (`TERM` by default). * `HEALTHCHECK` defines a command assessing the status of the container. * `SHELL` sets the default program to use for string-syntax RUN, CMD, etc. .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- class: extra-details ## The `ONBUILD` instruction The `ONBUILD` instruction is a trigger. It sets instructions that will be executed when another image is built from the image being build. This is useful for building images which will be used as a base to build other images. ```dockerfile ONBUILD COPY . /src ``` * You can't chain `ONBUILD` instructions with `ONBUILD`. * `ONBUILD` can't be used to trigger `FROM` instructions. ??? :EN:- Advanced Dockerfile syntax :FR:- Dockerfile niveau expert .debug[[containers/Advanced_Dockerfiles.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Advanced_Dockerfiles.md)] --- class: pic .interstitial[] --- name: toc-buildkit class: title Buildkit .nav[ [Previous part](#toc-advanced-dockerfile-syntax) | [Back to table of contents](#toc-part-7) | [Next part](#toc-exercise--buildkit-cache-mounts) ] .debug[(automatically generated title slide)] --- # Buildkit - "New" backend for Docker builds - announced in 2017 - ships with Docker Engine 18.09 - enabled by default on Docker Desktop in 2021 - Huge improvements in build efficiency - 100% compatible with existing Dockerfiles - New features for multi-arch - Not just for building container images .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Old vs New - Classic `docker build`: - copy whole build context - linear execution - `docker run` + `docker commit` + `docker run` + `docker commit`... - Buildkit: - copy files only when they are needed; cache them - compute dependency graph (dependencies are expressed by `COPY`) - parallel execution - doesn't rely on Docker, but on internal runner/snapshotter - can run in "normal" containers (including in Kubernetes pods) .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Parallel execution - In multi-stage builds, all stages can be built in parallel (example: https://github.com/jpetazzo/shpod; [before][shpod-before-parallel] and [after][shpod-after-parallel]) - Stages are built only when they are necessary (i.e. if their output is tagged or used in another necessary stage) - Files are copied from context only when needed - Files are cached in the builder [shpod-before-parallel]: https://github.com/jpetazzo/shpod/blob/c6efedad6d6c3dc3120dbc0ae0a6915f85862474/Dockerfile [shpod-after-parallel]: https://github.com/jpetazzo/shpod/blob/d20887bbd56b5fcae2d5d9b0ce06cae8887caabf/Dockerfile .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Turning it on and off - On recent version of Docker Desktop (since 2021): *enabled by default* - On older versions, or on Docker CE (Linux): `export DOCKER_BUILDKIT=1` - Turning it off: `export DOCKER_BUILDKIT=0` .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Multi-arch support - Historically, Docker only ran on x86_64 / amd64 (Intel/AMD 64 bits architecture) - Folks have been running it on 32-bit ARM for ages (e.g. Raspberry Pi) - This required a Go compiler and appropriate base images (which means changing/adapting Dockerfiles to use these base images) - Docker [image manifest v2 schema 2][manifest] introduces multi-arch images (`FROM alpine` automatically gets the right image for your architecture) [manifest]: https://docs.docker.com/registry/spec/manifest-v2-2/ .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Why? - Raspberry Pi (32-bit and 64-bit ARM) - Other ARM-based embedded systems (ODROID, NVIDIA Jetson...) - Apple M1, M2... - AWS Graviton - Ampere Altra (e.g. on Hetzner, Oracle Cloud, Scaleway...) .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Multi-arch builds in a nutshell Use the `docker buildx build` command: ```bash docker buildx build … \ --platform linux/amd64,linux/arm64,linux/arm/v7,linux/386 \ [--tag jpetazzo/hello --push] ``` - Requires all base images to be available for these platforms - Must not use binary downloads with hard-coded architectures! (streamlining a Dockerfile for multi-arch: [before][shpod-before-multiarch], [after][shpod-after-multiarch]) [shpod-before-multiarch]: https://github.com/jpetazzo/shpod/blob/d20887bbd56b5fcae2d5d9b0ce06cae8887caabf/Dockerfile [shpod-after-multiarch]: https://github.com/jpetazzo/shpod/blob/c50789e662417b34fea6f5e1d893721d66d265b7/Dockerfile .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Native vs emulated vs cross - Native builds: *aarch64 machine running aarch64 programs building aarch64 images/binaries* - Emulated builds: *x86_64 machine running aarch64 programs building aarch64 images/binaries* - Cross builds: *x86_64 machine running x86_64 programs building aarch64 images/binaries* .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Native - Dockerfiles are (relatively) simple to write (nothing special to do to handle multi-arch; just avoid hard-coded archs) - Best performance - Requires "exotic" machines - Requires setting up a build farm .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Emulated - Dockerfiles are (relatively) simple to write - Emulation performance can vary (from "OK" to "ouch this is slow") - Emulation isn't always perfect (weird bugs/crashes are rare but can happen) - Doesn't require special machines - Supports arbitrary architectures thanks to QEMU .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Cross - Dockerfiles are more complicated to write - Requires cross-compilation toolchains - Performance is good - Doesn't require special machines .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Native builds - Requires base images to be available - To view available architectures for an image: ```bash regctl manifest get --list <imagename> docker manifest inspect <imagename> ``` - Nothing special to do, *except* when downloading binaries! ``` https://releases.hashicorp.com/terraform/1.1.5/terraform_1.1.5_linux_`amd64`.zip ``` .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Finding the right architecture `uname -m` → armv7l, aarch64, i686, x86_64 `GOARCH` (from `go env`) → arm, arm64, 386, amd64 In Dockerfile, add `ARG TARGETARCH` (or `ARG TARGETPLATFORM`) - `TARGETARCH` matches `GOARCH` - `TARGETPLAFORM` → linux/arm/v7, linux/arm64, linux/386, linux/amd64 .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- class: extra-details ## Welp Sometimes, binary releases be like: ``` Linux_arm64.tar.gz Linux_ppc64le.tar.gz Linux_s390x.tar.gz Linux_x86_64.tar.gz ``` This needs a bit of custom mapping. .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Emulation - Leverages `binfmt_misc` and QEMU on Linux - Enabling: ```bash docker run --rm --privileged aptman/qus -s -- -p ``` - Disabling: ```bash docker run --rm --privileged aptman/qus -- -r ``` - Checking status: ```bash ls -l /proc/sys/fs/binfmt_misc ``` .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- class: extra-details ## How it works - `binfmt_misc` lets us register _interpreters_ for binaries, e.g.: - [DOSBox][dosbox] for DOS programs - [Wine][wine] for Windows programs - [QEMU][qemu] for Linux programs for other architectures - When we try to execute e.g. a SPARC binary on our x86_64 machine: - `binfmt_misc` detects the binary format and invokes `qemu-<arch> the-binary ...` - QEMU translates SPARC instructions to x86_64 instructions - system calls go straight to the kernel [dosbox]: https://www.dosbox.com/ [QEMU]: https://www.qemu.org/ [wine]: https://www.winehq.org/ .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- class: extra-details ## QEMU registration - The `aptman/qus` image mentioned earlier contains static QEMU builds - It registers all these interpreters with the kernel - For more details, check: - https://github.com/dbhi/qus - https://dbhi.github.io/qus/ .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Cross-compilation - Cross-compilation is about 10x faster than emulation (non-scientific benchmarks!) - In Dockerfile, add: `ARG BUILDARCH BUILDPLATFORM TARGETARCH TARGETPLATFORM` - Can use `FROM --platform=$BUILDPLATFORM <image>` - Then use `$TARGETARCH` or `$TARGETPLATFORM` (e.g. for Go, `export GOARCH=$TARGETARCH`) - Check [tonistiigi/xx][xx] and [Toni's blog][toni] for some amazing cross tools! [xx]: https://github.com/tonistiigi/xx [toni]: https://medium.com/@tonistiigi/faster-multi-platform-builds-dockerfile-cross-compilation-guide-part-1-ec087c719eaf .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Checking runtime capabilities Build and run the following Dockerfile: ```dockerfile FROM --platform=linux/amd64 busybox AS amd64 FROM --platform=linux/arm64 busybox AS arm64 FROM --platform=linux/arm/v7 busybox AS arm32 FROM --platform=linux/386 busybox AS ia32 FROM alpine RUN apk add file WORKDIR /root COPY --from=amd64 /bin/busybox /root/amd64/busybox COPY --from=arm64 /bin/busybox /root/arm64/busybox COPY --from=arm32 /bin/busybox /root/arm32/busybox COPY --from=ia32 /bin/busybox /root/ia32/busybox CMD for A in *; do echo "$A => $($A/busybox uname -a)"; done ``` It will indicate which executables can be run on your engine. .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## Cache directories ```bash RUN --mount=type=cache,target=/pipcache pip install --cache-dir /pipcache ... ``` - The `/pipcache` directory won't be in the final image - But it will persist across builds - This can simplify Dockerfiles a lot - we no longer need to `download package && install package && rm package` - download to a cache directory, and skip `rm` phase - Subsequent builds will also be faster, thanks to caching .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- ## More than builds - Buildkit is also used in other systems: - [Earthly] - generic repeatable build pipelines - [Dagger] - CICD pipelines that run anywhere - and more! [Earthly]: https://earthly.dev/ [Dagger]: https://dagger.io/ .debug[[containers/Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Buildkit.md)] --- class: pic .interstitial[] --- name: toc-exercise--buildkit-cache-mounts class: title Exercise — BuildKit cache mounts .nav[ [Previous part](#toc-buildkit) | [Back to table of contents](#toc-part-7) | [Next part](#toc-init-systems-and-pid-) ] .debug[(automatically generated title slide)] --- # Exercise — BuildKit cache mounts We want to make our builds faster by leveraging BuildKit cache mounts. Of course, if we don't make any changes to the code, the build should be instantaneous. Therefore, to benchmark our changes, we will make trivial changes to the code (e.g. change the message in a "print" statement) and measure (e.g. with `time`) how long it takes to rebuild the image. .debug[[containers/Exercise_Dockerfile_Buildkit.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Exercise_Dockerfile_Buildkit.md)] --- class: pic .interstitial[] --- name: toc-init-systems-and-pid- class: title Init systems and PID 1 .nav[ [Previous part](#toc-exercise--buildkit-cache-mounts) | [Back to table of contents](#toc-part-7) | [Next part](#toc-application-configuration) ] .debug[(automatically generated title slide)] --- # Init systems and PID 1 In this chapter, we will consider: - the role of PID 1 in the world of Docker, - how to avoid some common pitfalls due to the misuse of init systems. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- ## What's an init system? - On UNIX, the "init system" (or "init" in short) is PID 1. - It is the first process started by the kernel when the system starts. - It has multiple responsibilities: - start every other process on the machine, - reap orphaned zombie processes. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- class: extra-details ## Orphaned zombie processes ?!? - When a process exits (or "dies"), it becomes a "zombie". (Zombie processes show up in `ps` or `top` with the status code `Z`.) - Its parent process must *reap* the zombie process. (This is done by calling `waitpid()` to retrieve the process' exit status.) - When a process exits, if it has child processes, these processes are "orphaned." - They are then re-parented to PID 1, init. - Init therefore needs to take care of these orphaned processes when they exit. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- ## Don't use init systems in containers - It's often tempting to use an init system or a process manager. (Examples: *systemd*, *supervisord*...) - Our containers are then called "system containers". (By contrast with "application containers".) - "System containers" are similar to lightweight virtual machines. - They have multiple downsides: - when starting multiple processes, their logs get mixed on stdout, - if the application process dies, the container engine doesn't see it. - Overall, they make it harder to operate troubleshoot containerized apps. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- ## Exceptions and workarounds - Sometimes, it's convenient to run a real init system like *systemd*. (Example: a CI system whose goal is precisely to test an init script or unit file.) - If we need to run multiple processes: can we use multiple containers? (Example: [this Compose file](https://github.com/jpetazzo/container.training/blob/master/compose/simple-k8s-control-plane/docker-compose.yaml) runs multiple processes together.) - When deploying with Kubernetes: - a container belong to a pod, - a pod can have multiple containers. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- ## What about these zombie processes? - Our application runs as PID 1 in the container. - Our application may or may not be designed to reap zombie processes. - If our application uses subprocesses and doesn't reap them ... ... this can lead to PID exhaustion! (Or, more realistically, to a confusing herd of zombie processes.) - How can we solve this? .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- ## Tini to the rescue - Docker can automatically provide a minimal `init` process. - This is enabled with `docker run --init ...` - It uses a small init system ([tini](https://github.com/krallin/tini)) as PID 1: - it reaps zombies, - it forwards signals, - it exits when the child exits. - It is totally transparent to our application. - We should use it if our application creates subprocess but doesn't reap them. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- class: extra-details ## What about Kubernetes? - Kubernetes does not expose that `--init` option. - However, we can achieve the same result with [Process Namespace Sharing](https://kubernetes.io/docs/tasks/configure-pod-container/share-process-namespace/). - When Process Namespace Sharing is enabled, PID 1 will be `pause`. - That `pause` process takes care of reaping zombies. - Process Namespace Sharing is available since Kubernetes 1.16. - If you're using an older version of Kubernetes ... ... you might have to add `tini` explicitly to your Docker image. .debug[[containers/Init_Systems.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Init_Systems.md)] --- class: pic .interstitial[] --- name: toc-application-configuration class: title Application Configuration .nav[ [Previous part](#toc-init-systems-and-pid-) | [Back to table of contents](#toc-part-7) | [Next part](#toc-logging) ] .debug[(automatically generated title slide)] --- # Application Configuration There are many ways to provide configuration to containerized applications. There is no "best way" — it depends on factors like: * configuration size, * mandatory and optional parameters, * scope of configuration (per container, per app, per customer, per site, etc), * frequency of changes in the configuration. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Command-line parameters ```bash docker run jpetazzo/hamba 80 www1:80 www2:80 ``` * Configuration is provided through command-line parameters. * In the above example, the `ENTRYPOINT` is a script that will: - parse the parameters, - generate a configuration file, - start the actual service. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Command-line parameters pros and cons * Appropriate for mandatory parameters (without which the service cannot start). * Convenient for "toolbelt" services instantiated many times. (Because there is no extra step: just run it!) * Not great for dynamic configurations or bigger configurations. (These things are still possible, but more cumbersome.) .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Environment variables ```bash docker run -e ELASTICSEARCH_URL=http://es42:9201/ kibana ``` * Configuration is provided through environment variables. * The environment variable can be used straight by the program, <br/>or by a script generating a configuration file. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Environment variables pros and cons * Appropriate for optional parameters (since the image can provide default values). * Also convenient for services instantiated many times. (It's as easy as command-line parameters.) * Great for services with lots of parameters, but you only want to specify a few. (And use default values for everything else.) * Ability to introspect possible parameters and their default values. * Not great for dynamic configurations. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Baked-in configuration ``` FROM prometheus COPY prometheus.conf /etc ``` * The configuration is added to the image. * The image may have a default configuration; the new configuration can: - replace the default configuration, - extend it (if the code can read multiple configuration files). .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Baked-in configuration pros and cons * Allows arbitrary customization and complex configuration files. * Requires writing a configuration file. (Obviously!) * Requires building an image to start the service. * Requires rebuilding the image to reconfigure the service. * Requires rebuilding the image to upgrade the service. * Configured images can be stored in registries. (Which is great, but requires a registry.) .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Configuration volume ```bash docker run -v appconfig:/etc/appconfig myapp ``` * The configuration is stored in a volume. * The volume is attached to the container. * The image may have a default configuration. (But this results in a less "obvious" setup, that needs more documentation.) .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Configuration volume pros and cons * Allows arbitrary customization and complex configuration files. * Requires creating a volume for each different configuration. * Services with identical configurations can use the same volume. * Doesn't require building / rebuilding an image when upgrading / reconfiguring. * Configuration can be generated or edited through another container. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Dynamic configuration volume * This is a powerful pattern for dynamic, complex configurations. * The configuration is stored in a volume. * The configuration is generated / updated by a special container. * The application container detects when the configuration is changed. (And automatically reloads the configuration when necessary.) * The configuration can be shared between multiple services if needed. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Dynamic configuration volume example In a first terminal, start a load balancer with an initial configuration: ```bash $ docker run --name loadbalancer jpetazzo/hamba \ 80 goo.gl:80 ``` In another terminal, reconfigure that load balancer: ```bash $ docker run --rm --volumes-from loadbalancer jpetazzo/hamba reconfigure \ 80 google.com:80 ``` The configuration could also be updated through e.g. a REST API. (The REST API being itself served from another container.) .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- ## Keeping secrets .warning[Ideally, you should not put secrets (passwords, tokens...) in:] * command-line or environment variables (anyone with Docker API access can get them), * images, especially stored in a registry. Secrets management is better handled with an orchestrator (like Swarm or Kubernetes). Orchestrators will allow to pass secrets in a "one-way" manner. Managing secrets securely without an orchestrator can be contrived. E.g.: - read the secret on stdin when the service starts, - pass the secret using an API endpoint. .debug[[containers/Application_Configuration.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Application_Configuration.md)] --- class: pic .interstitial[] --- name: toc-logging class: title Logging .nav[ [Previous part](#toc-application-configuration) | [Back to table of contents](#toc-part-7) | [Next part](#toc-limiting-resources) ] .debug[(automatically generated title slide)] --- # Logging In this chapter, we will explain the different ways to send logs from containers. We will then show one particular method in action, using ELK and Docker's logging drivers. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## There are many ways to send logs - The simplest method is to write on the standard output and error. - Applications can write their logs to local files. (The files are usually periodically rotated and compressed.) - It is also very common (on UNIX systems) to use syslog. (The logs are collected by syslogd or an equivalent like journald.) - In large applications with many components, it is common to use a logging service. (The code uses a library to send messages to the logging service.) *All these methods are available with containers.* .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Writing on stdout/stderr - The standard output and error of containers is managed by the container engine. - This means that each line written by the container is received by the engine. - The engine can then do "whatever" with these log lines. - With Docker, the default configuration is to write the logs to local files. - The files can then be queried with e.g. `docker logs` (and the equivalent API request). - This can be customized, as we will see later. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Writing to local files - If we write to files, it is possible to access them but cumbersome. (We have to use `docker exec` or `docker cp`.) - Furthermore, if the container is stopped, we cannot use `docker exec`. - If the container is deleted, the logs disappear. - What should we do for programs who can only log to local files? -- - There are multiple solutions. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Using a volume or bind mount - Instead of writing logs to a normal directory, we can place them on a volume. - The volume can be accessed by other containers. - We can run a program like `filebeat` in another container accessing the same volume. (`filebeat` reads local log files continuously, like `tail -f`, and sends them to a centralized system like ElasticSearch.) - We can also use a bind mount, e.g. `-v /var/log/containers/www:/var/log/tomcat`. - The container will write log files to a directory mapped to a host directory. - The log files will appear on the host and be consumable directly from the host. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Using logging services - We can use logging frameworks (like log4j or the Python `logging` package). - These frameworks require some code and/or configuration in our application code. - These mechanisms can be used identically inside or outside of containers. - Sometimes, we can leverage containerized networking to simplify their setup. - For instance, our code can send log messages to a server named `log`. - The name `log` will resolve to different addresses in development, production, etc. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Using syslog - What if our code (or the program we are running in containers) uses syslog? - One possibility is to run a syslog daemon in the container. - Then that daemon can be setup to write to local files or forward to the network. - Under the hood, syslog clients connect to a local UNIX socket, `/dev/log`. - We can expose a syslog socket to the container (by using a volume or bind-mount). - Then just create a symlink from `/dev/log` to the syslog socket. - Voilà! .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Using logging drivers - If we log to stdout and stderr, the container engine receives the log messages. - The Docker Engine has a modular logging system with many plugins, including: - json-file (the default one) - syslog - journald - gelf - fluentd - splunk - etc. - Each plugin can process and forward the logs to another process or system. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## A word of warning about `json-file` - By default, log file size is unlimited. - This means that a very verbose container *will* use up all your disk space. (Or a less verbose container, but running for a very long time.) - Log rotation can be enabled by setting a `max-size` option. - Older log files can be removed by setting a `max-file` option. - Just like other logging options, these can be set per container, or globally. Example: ```bash $ docker run --log-opt max-size=10m --log-opt max-file=3 elasticsearch ``` .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Demo: sending logs to ELK - We are going to deploy an ELK stack. - It will accept logs over a GELF socket. - We will run a few containers with the `gelf` logging driver. - We will then see our logs in Kibana, the web interface provided by ELK. *Important foreword: this is not an "official" or "recommended" setup; it is just an example. We used ELK in this demo because it's a popular setup and we keep being asked about it; but you will have equal success with Fluent or other logging stacks!* .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## What's in an ELK stack? - ELK is three components: - ElasticSearch (to store and index log entries) - Logstash (to receive log entries from various sources, process them, and forward them to various destinations) - Kibana (to view/search log entries with a nice UI) - The only component that we will configure is Logstash - We will accept log entries using the GELF protocol - Log entries will be stored in ElasticSearch, <br/>and displayed on Logstash's stdout for debugging .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Running ELK - We are going to use a Compose file describing the ELK stack. - The Compose file is in the container.training repository on GitHub. ```bash $ git clone https://github.com/jpetazzo/container.training $ cd container.training $ cd elk $ docker-compose up ``` - Let's have a look at the Compose file while it's deploying. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Our basic ELK deployment - We are using images from the Docker Hub: `elasticsearch`, `logstash`, `kibana`. - We don't need to change the configuration of ElasticSearch. - We need to tell Kibana the address of ElasticSearch: - it is set with the `ELASTICSEARCH_URL` environment variable, - by default it is `localhost:9200`, we change it to `elasticsearch:9200`. - We need to configure Logstash: - we pass the entire configuration file through command-line arguments, - this is a hack so that we don't have to create an image just for the config. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Sending logs to ELK - The ELK stack accepts log messages through a GELF socket. - The GELF socket listens on UDP port 12201. - To send a message, we need to change the logging driver used by Docker. - This can be done globally (by reconfiguring the Engine) or on a per-container basis. - Let's override the logging driver for a single container: ```bash $ docker run --log-driver=gelf --log-opt=gelf-address=udp://localhost:12201 \ alpine echo hello world ``` .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Viewing the logs in ELK - Connect to the Kibana interface. - It is exposed on port 5601. - Browse http://X.X.X.X:5601. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## "Configuring" Kibana - Kibana should offer you to "Configure an index pattern": <br/>in the "Time-field name" drop down, select "@timestamp", and hit the "Create" button. - Then: - click "Discover" (in the top-left corner), - click "Last 15 minutes" (in the top-right corner), - click "Last 1 hour" (in the list in the middle), - click "Auto-refresh" (top-right corner), - click "5 seconds" (top-left of the list). - You should see a series of green bars (with one new green bar every minute). - Our 'hello world' message should be visible there. .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- ## Important afterword **This is not a "production-grade" setup.** It is just an educational example. Since we have only one node , we did set up a single ElasticSearch instance and a single Logstash instance. In a production setup, you need an ElasticSearch cluster (both for capacity and availability reasons). You also need multiple Logstash instances. And if you want to withstand bursts of logs, you need some kind of message queue: Redis if you're cheap, Kafka if you want to make sure that you don't drop messages on the floor. Good luck. If you want to learn more about the GELF driver, have a look at [this blog post]( https://jpetazzo.github.io/2017/01/20/docker-logging-gelf/). .debug[[containers/Logging.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Logging.md)] --- class: pic .interstitial[] --- name: toc-limiting-resources class: title Limiting resources .nav[ [Previous part](#toc-logging) | [Back to table of contents](#toc-part-7) | [Next part](#toc-deep-dive-into-container-internals) ] .debug[(automatically generated title slide)] --- # Limiting resources - So far, we have used containers as convenient units of deployment. - What happens when a container tries to use more resources than available? (RAM, CPU, disk usage, disk and network I/O...) - What happens when multiple containers compete for the same resource? - Can we limit resources available to a container? (Spoiler alert: yes!) .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Container processes are normal processes - Containers are closer to "fancy processes" than to "lightweight VMs". - A process running in a container is, in fact, a process running on the host. - Let's look at the output of `ps` on a container host running 3 containers : ``` 0 2662 0.2 0.3 /usr/bin/dockerd -H fd:// 0 2766 0.1 0.1 \_ docker-containerd --config /var/run/docker/containe 0 23479 0.0 0.0 \_ docker-containerd-shim -namespace moby -workdir 0 23497 0.0 0.0 | \_ `nginx`: master process nginx -g daemon off; 101 23543 0.0 0.0 | \_ `nginx`: worker process 0 23565 0.0 0.0 \_ docker-containerd-shim -namespace moby -workdir 102 23584 9.4 11.3 | \_ `/docker-java-home/jre/bin/java` -Xms2g -Xmx2 0 23707 0.0 0.0 \_ docker-containerd-shim -namespace moby -workdir 0 23725 0.0 0.0 \_ `/bin/sh` ``` - The highlighted processes are containerized processes. <br/> (That host is running nginx, elasticsearch, and alpine.) .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## By default: nothing changes - What happens when a process uses too much memory on a Linux system? -- - Simplified answer: - swap is used (if available); - if there is not enough swap space, eventually, the out-of-memory killer is invoked; - the OOM killer uses heuristics to kill processes; - sometimes, it kills an unrelated process. -- - What happens when a container uses too much memory? - The same thing! (i.e., a process eventually gets killed, possibly in another container.) .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Limiting container resources - The Linux kernel offers rich mechanisms to limit container resources. - For memory usage, the mechanism is part of the *cgroup* subsystem. - This subsystem allows limiting the memory for a process or a group of processes. - A container engine leverages these mechanisms to limit memory for a container. - The out-of-memory killer has a new behavior: - it runs when a container exceeds its allowed memory usage, - in that case, it only kills processes in that container. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Limiting memory in practice - The Docker Engine offers multiple flags to limit memory usage. - The two most useful ones are `--memory` and `--memory-swap`. - `--memory` limits the amount of physical RAM used by a container. - `--memory-swap` limits the total amount (RAM+swap) used by a container. - The memory limit can be expressed in bytes, or with a unit suffix. (e.g.: `--memory 100m` = 100 megabytes.) - We will see two strategies: limiting RAM usage, or limiting both .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Limiting RAM usage Example: ```bash docker run -ti --memory 100m python ``` If the container tries to use more than 100 MB of RAM, *and* swap is available: - the container will not be killed, - memory above 100 MB will be swapped out, - in most cases, the app in the container will be slowed down (a lot). If we run out of swap, the global OOM killer still intervenes. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Limiting both RAM and swap usage Example: ```bash docker run -ti --memory 100m --memory-swap 100m python ``` If the container tries to use more than 100 MB of memory, it is killed. On the other hand, the application will never be slowed down because of swap. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## When to pick which strategy? - Stateful services (like databases) will lose or corrupt data when killed - Allow them to use swap space, but monitor swap usage - Stateless services can usually be killed with little impact - Limit their mem+swap usage, but monitor if they get killed - Ultimately, this is no different from "do I want swap, and how much?" .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Limiting CPU usage - There are no less than 3 ways to limit CPU usage: - setting a relative priority with `--cpu-shares`, - setting a CPU% limit with `--cpus`, - pinning a container to specific CPUs with `--cpuset-cpus`. - They can be used separately or together. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Setting relative priority - Each container has a relative priority used by the Linux scheduler. - By default, this priority is 1024. - As long as CPU usage is not maxed out, this has no effect. - When CPU usage is maxed out, each container receives CPU cycles in proportion of its relative priority. - In other words: a container with `--cpu-shares 2048` will receive twice as much than the default. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Setting a CPU% limit - This setting will make sure that a container doesn't use more than a given % of CPU. - The value is expressed in CPUs; therefore: `--cpus 0.1` means 10% of one CPU, `--cpus 1.0` means 100% of one whole CPU, `--cpus 10.0` means 10 entire CPUs. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Pinning containers to CPUs - On multi-core machines, it is possible to restrict the execution on a set of CPUs. - Examples: `--cpuset-cpus 0` forces the container to run on CPU 0; `--cpuset-cpus 3,5,7` restricts the container to CPUs 3, 5, 7; `--cpuset-cpus 0-3,8-11` restricts the container to CPUs 0, 1, 2, 3, 8, 9, 10, 11. - This will not reserve the corresponding CPUs! (They might still be used by other containers, or uncontainerized processes.) .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- ## Limiting disk usage - Most storage drivers do not support limiting the disk usage of containers. (With the exception of devicemapper, but the limit cannot be set easily.) - This means that a single container could exhaust disk space for everyone. - In practice, however, this is not a concern, because: - data files (for stateful services) should reside on volumes, - assets (e.g. images, user-generated content...) should reside on object stores or on volume, - logs are written on standard output and gathered by the container engine. - Container disk usage can be audited with `docker ps -s` and `docker diff`. .debug[[containers/Resource_Limits.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Resource_Limits.md)] --- class: pic .interstitial[] --- name: toc-deep-dive-into-container-internals class: title Deep dive into container internals .nav[ [Previous part](#toc-limiting-resources) | [Back to table of contents](#toc-part-8) | [Next part](#toc-control-groups) ] .debug[(automatically generated title slide)] --- # Deep dive into container internals In this chapter, we will explain some of the fundamental building blocks of containers. This will give you a solid foundation so you can: - understand "what's going on" in complex situations, - anticipate the behavior of containers (performance, security...) in new scenarios, - implement your own container engine. The last item should be done for educational purposes only! .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## There is no container code in the Linux kernel - If we search "container" in the Linux kernel code, we find: - generic code to manipulate data structures (like linked lists, etc.), - unrelated concepts like "ACPI containers", - *nothing* relevant to "our" containers! - Containers are composed using multiple independent features. - On Linux, containers rely on "namespaces, cgroups, and some filesystem magic." - Security also requires features like capabilities, seccomp, LSMs... .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: pic .interstitial[] --- name: toc-control-groups class: title Control groups .nav[ [Previous part](#toc-deep-dive-into-container-internals) | [Back to table of contents](#toc-part-8) | [Next part](#toc-namespaces) ] .debug[(automatically generated title slide)] --- # Control groups - Control groups provide resource *metering* and *limiting*. - This covers: - "classic" compute resources like memory, CPU, I/O - system resources like number of processes (PID) - "exotic" resources like GPU VRAM, huge pages, RDMA - other things like device node access (`/dev`) and perf events .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Crowd control - Control groups also allow to group processes for special operations: - freeze (conceptually similar to a "mass-SIGSTOP/SIGCONT") - kill (safe mass-SIGKILL) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Generalities - Cgroups form a hierarchy (a tree) - We can create nodes in that hierarchy - We can associate limits to a node - We can move a process (or multiple processes) to a leaf - The process (or processes) will then respect these limits - We can check the current usage of each node - In other words: limits are optional (if we only want accounting) - When a process is created, it is placed in its parent's groups - The main interface is a pseudo-filesystem (typically mounted on `/sys/fs/cgroup`) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Example .small[ ```bash $ tree /sys/fs/cgroup/ -d /sys/fs/cgroup/ ├── init.scope ├── machine.slice ├── system.slice │ ├── avahi-daemon.service │ ├── ... │ ├── docker-de3ee38bc8d90b7da218523004cae504a2fa821224fd49f53521d862db583fef.scope │ ├── docker-e9e55ba69f0a4639793464972a8645cdb23ae9f60567384479a175e3226776b4.scope │ ├── docker.service │ ├── docker.socket │ ├── ... │ └── wpa_supplicant.service └── user.slice └── user-1000.slice ├── session-1.scope └── user@1000.service ├── app.slice │ └── ... ├── init.scope └── session.slice └── ... ``` ] .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Cgroups v1 vs v2 - Cgroups v1 were the original implementation (back when Docker was created) - Cgroups v2 are a huge refactor (development started in Linux 3.10, released in 4.5.) - Cgroups v2 have a number of differences: - single hierarchy (instead of one tree per controller) - processes can only be on leaf nodes (not inner nodes) - and of course many improvements / refactorings - Cgroups v2 should be the default on all modern distros! .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Example of cgroup v1 hierarchy The numbers are PIDs. The names are the names of our nodes (arbitrarily chosen). .small[ ```bash cpu memory ├── batch ├── stateless │ ├── cryptoscam │ ├── 25 │ │ └── 52 │ ├── 26 │ └── ffmpeg │ ├── 27 │ ├── 109 │ ├── 52 │ └── 88 │ ├── 109 └── realtime │ └── 88 ├── nginx └── databases │ ├── 25 ├── 1008 │ ├── 26 └── 524 │ └── 27 ├── postgres │ └── 524 └── redis └── 1008 ``` ] .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## CPU cgroup - Keeps track of CPU time used by a group of processes (this is easier and more accurate than `getrusage` and `/proc`) - Allows setting relative weights used by the scheduler - Allows setting maximum time usage per time period (e.g. "50ms every 100ms", which would cap the group to 50% of one CPU core) - Allows setting reservations and caps ("utilization clamping") (particularly relevant for realtime processes) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Checking current CPU limits - Getting the cgroup for the current user session: ```bash cat /proc/$$/cgroup ``` (it should start with `/user.slice/...`) - Checking the current CPU limit: ```bash cat /sys/fs/cgroup/user.slice/.../cpu.max ``` (it should look like `max 100000`) - `max` means unlimited; `100000` means "over a period of 100000 microseconds" (unless specified, all cgroup time durations are in microseconds) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Setting a CPU limit - Run `top` in a terminal to view CPU usage - In a separate terminal, burn CPU cycles with e.g.: ```bash while : ; do : ; done ``` - Set a 50% CPU limit for that user or session: ```bash echo 50000 > /sys/fs/cgroup/user.slice/.../cpu.max ``` - Notice that CPU usage goes down (probably to *less* than 50% since this is a limit for the whole user/session!) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Removing the CPU limit - Remember to remove the limit when you're done: ```bash echo max > /sys/fs/cgroup/user.slice/.../cpu.max ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Cpuset cgroup - Pin groups to specific CPU(s) - Features: - limit apps to specific CPUs (`cpuset.cpus`) - reserve CPUs for exclusive use (`cpuset.cpus.exclusive`) - assign apps to specific NUMA memory nodes (`cpuset.mems`) - Use-cases: - dedicate CPUs to avoid performance loss due to cache flushes - improve memory performance in NUMA systems .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Cpuset concepts - `cpuset.cpus` / `cpuset.mems` *express what we allow the cgroup to use (can be empty to allow everything)* - `cpuset.cpus.effective` / `cpusets.mems.effective` *express what the cgroup can actually use after accounting for other restrictions* - `cpuset.cpus.exclusive` / `cpuset.cpus.partition` *used to create "partitions" = sets of CPU(s) exclusively reserved for a cgroup* .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Memory cgroup: accounting - Keeps track of pages used by each group: - file (read/write/mmap from block devices) - anonymous (stack, heap, anonymous mmap) - active (recently accessed) - inactive (candidate for eviction) - ...many other categories! - Each page is "charged" to a single group (this can result in non-deterministic "charges" for shared pages, e.g. mapped files) - To view all the counters kept by this cgroup: ```bash $ cat /sys/fs/cgroup/memory.stat ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Memory cgroup: limits and reservations - Cgroups v1 allowed to set soft and hard limits (soft limits influenced reclaim but it wasn't straightforward to use) - Cgroups v2 are way more sophisticated: - hard limits (`.max`) - thresholds triggering more evictions (`.high`) - thresholds triggering less evictions (`.low`) - reservations (`.min`) - Also limits for swap and zswap .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Hard limits - A cgroup can *never* exceed its hard limits - When a cgroup tries to use more than the hard limit: - the kernel tries to reclaim memory (buffers, mapped files...) - when there is nothing to reclaim, the OOM killer is invoked - There is a `memory.oom.group` flag to alter OOM behavior: - `0` (default) = kill processes one by one - `1` = consider the cgroup as a unit; OOM will kill it entirely .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Also... - A `.peak` value is also exposed for each tracked amount (memory, swap, zswap) - Write an amount to `memory.reclaim` to trigger reclaim (=ask the kernel to recover memory from the cgroup) - Check memory stats per NUMA nopde (`memory.numa_stat`) - And more! .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Block I/O cgroup - Keep track of I/Os for each group: - per block device - read, write, and discard - in bytes and in operations - Set hard limits for each counter - Set relative weights and latency targets .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## `io.max` - Enforce hard limits (set max number of operations, of bytes read/written...) - Each limit is per-device - Doesn't offer performance guarantees (once a device is saturated, performance will degrade for everyone) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## `io.cost.qos` - Try to offer latency guarantees - Define per-device thresholds to throttle operations "if the 95% percentile latency of read operations on this device is above 100ms... ...throttle operations on this device (queue them)" - Can also define `io.weight` for relative priorities between cgroups - Check [this document](https://facebookmicrosites.github.io/resctl-demo-website/docs/demo_docs/setting_benchmarks/iocost/) for some details and hints .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Network I/O - Cgroups v1 had net_cls and net_prio controllers - These have been deprecated in cgroups v2: *There is no direct equivalent of the net_cls and net_prio controllers from cgroups version 1. Instead, support has been added to iptables(8) to allow eBPF filters that hook on cgroup v2 pathnames to make decisions about network traffic on a per-cgroup basis.* .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Pid - Limit (and count) number of processes in a cgroup - Protects against e.g. fork bombs .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Devices - We need to limit access to device nodes - Containers should not be able to open e.g. disks and partitions directly (/dev/sda\*, /dev/nvme\*...) - However, some devices are expected to be available at all times: /dev/tty, /dev/zero, /dev/null, /dev/random... .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Cgroups v1 - There used to be a special "devices" control group - It made it easy to grand read/write/mknod permissions (individually for each device and each container) - Access could be granted/revoked/viewed through a pseudo-file: ```bash echo 'c 1:3 mr' > /sys/fs/cgroup/.../devices.allow ``` - This file doesn't exist anymore in cgroups v2! .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Cgroups v2 - Device access is controlled with eBPF programs (there is a special program type, [`cgroup_device`][bpf-cgroup-device], for that purpose) - This requires writing and compiling eBPF programs (😰) - Viewing permissions requires disassembling eBPF programs (😱) [bpf-cgroup-device]: https://docs.ebpf.io/linux/program-type/BPF_PROG_TYPE_CGROUP_DEVICE/ .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Viewing eBPF programs - Install bpf tools (package name `bpftool` or `bpf`) - View all eBPF programs attached to cgroups: ```bash sudo bpftool cgroup tree ``` - View eBPF programs attached to a Docker container: ```bash sudo bpftool cgroup list /sys/fs/cgroup/system.slice/docker-<CONTAINER_ID>.scope ``` - Disassemble an eBPF program: ```bash sudo bpftool prog dump xlated id <ID> ``` - *Bon chance* 😬 .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Some interesting nodes - `/dev/net/tun` (network interface manipulation) - `/dev/fuse` (filesystems in user space) - `/dev/kvm` (run VMs in containers) - `/dev/dri` (GPU) - `/dev/ttyUSB*`, `/dev/ttyACM*` (serial devices) - `/dev/snd/*` (sound cards) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## And the exotic ones... - `rdma`: remote memory access, infiniband - `dmem`: device memory (VRAM), relatively new (kernel 6.14, January 2025; only Intel and AMD GPU for now) - `hugetlb`: huge pages - `perf_event`: [performance profiling](https://perfwiki.github.io/main/) - `misc`: generic cgroup for other discrete resources (extension point to plug even more exotic resources) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: pic .interstitial[] --- name: toc-namespaces class: title Namespaces .nav[ [Previous part](#toc-control-groups) | [Back to table of contents](#toc-part-8) | [Next part](#toc-security-features) ] .debug[(automatically generated title slide)] --- # Namespaces - Provide processes with their own view of the system - Namespaces limit what you can see (and therefore, what you can use) - These namespaces are available in modern kernels: - pid - net - mnt - uts - ipc - user - time - cgroup (we are going to detail them individually) - Each process belongs to one namespace of each type .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Namespaces are always active - Namespaces exist even when you don't use containers - This is a bit similar to the UID field in UNIX processes: - all processes have the UID field, even if no user exists on the system - the field always has a value / the value is always defined <br/> (i.e. any process running on the system has some UID) - the value of the UID field is used when checking permissions <br/> (the UID field determines which resources the process can access) - You can replace "UID field" with "namespace" above and it still works! - In other words: even when you don't use containers, <br/>there is one namespace of each type, containing all the processes on the system .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Manipulating namespaces - Namespaces are created with two methods: - the `clone()` system call (used when creating new threads and processes) - the `unshare()` system call - The Linux tool `unshare` allows doing that from a shell - A new process can re-use none / all / some of the namespaces of its parent - It is possible to "enter" a namespace with the `setns()` system call - The Linux tool `nsenter` allows doing that from a shell .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Namespaces lifecycle - When the last process of a namespace exits, the namespace is destroyed - All the associated resources are then removed - Namespaces are materialized by pseudo-files in `/proc/<pid>/ns`. ```bash ls -l /proc/self/ns ``` - It is possible to compare namespaces by checking these files (this helps to answer the question, "are these two processes in the same namespace?") - It is possible to preserve a namespace by bind-mounting its pseudo-file .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Namespaces can be used independently - As mentioned in the previous slides: *a new process can re-use none / all / some of the namespaces of its parent* - It's possible to create e.g.: - mount namespaces to have "private" `/tmp` for each user / app - network namespaces to isolate apps or give them a special network access - It's possible to use namespaces without cgroups (and totally outside of container contexts) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## UTS namespace - gethostname / sethostname - Allows setting a custom hostname for a container - That's (mostly) it! - Also allows setting the NIS domain (if you don't know what a NIS domain is, you don't have to worry about it!) - If you're wondering: UTS = UNIX time sharing - This namespace was named like this because of the `struct utsname`, <br/> which is commonly used to obtain the machine's hostname, architecture, etc. (the more you know!) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Creating our first namespace Let's use `unshare` to create a new process that will have its own UTS namespace: ```bash $ sudo unshare --uts ``` - We have to use `sudo` for most `unshare` operations - We indicate that we want a new uts namespace, and nothing else - If we don't specify a program to run, a `$SHELL` is started .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Demonstrating our uts namespace In our new "container", check the hostname, change it, and check it: ```bash # hostname nodeX # hostname tupperware # hostname tupperware ``` In another shell, check that the machine's hostname hasn't changed: ```bash $ hostname nodeX ``` Exit the "container" with `exit` or `Ctrl-D`. .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Net namespace overview - Each network namespace has its own private network stack - The network stack includes: - network interfaces (including `lo`) - routing table**s** (as in `ip rule` etc.) - iptables chains and rules - sockets (as seen by `ss`, `netstat`) - You can move a network interface from a network namespace to another: ```bash ip link set dev eth0 netns PID ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Net namespace typical use - Each container is given its own network namespace - For each network namespace (i.e. each container), a `veth` pair is created (two `veth` interfaces act as if they were connected with a cross-over cable) - One `veth` is moved to the container network namespace (and renamed `eth0`) - The other `veth` is moved to a bridge on the host (e.g. the `docker0` bridge) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Creating a network namespace Start a new process with its own network namespace: ```bash $ sudo unshare --net ``` See that this new network namespace is unconfigured: ```bash # ping 1.1 connect: Network is unreachable # ifconfig # ip link ls 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Creating the `veth` interfaces In another shell (on the host), create a `veth` pair: ```bash $ sudo ip link add name in_host type veth peer name in_netns ``` Configure the host side (`in_host`): ```bash $ sudo ip link set in_host up $ sudo ip addr add 172.22.0.1/24 dev in_host ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Moving the `veth` interface *In the process created by `unshare`,* check the PID of our "network container": ```bash # echo $$ 533 ``` *On the host*, move the other side (`in_netns`) to the network namespace: ```bash $ sudo ip link set in_netns netns 533 ``` (Make sure to update "533" with the actual PID obtained above!) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Basic network configuration Let's set up `lo` (the loopback interface): ```bash # ip link set lo up ``` Activate the `veth` interface and rename it to `eth0`: ```bash # ip link set in_netns name eth0 up ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Allocating IP address and default route *In the process created by `unshare`,* configure the interface: ```bash # ip addr add 172.22.0.2/24 dev eth0 # ip route add default via 172.22.0.1 ``` (Make sure to update the IP addresses if necessary.) Check that we can ping the host: ```bash # ping 172.22.0.1 ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Reaching the outside world This requires to: - enable forwarding on the host - add a masquerading (SNAT) rule for traffic coming from the namespace If Docker is running on the host, we can also add the `in_host` interface to the Docker bridge, and configure the `in_netns` interface with an IP address belonging to the subnet of the Docker bridge! .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Cleaning up network namespaces - Terminate the process created by `unshare` (with `exit` or `Ctrl-D`). - Since this was the only process in the network namespace, it is destroyed. - All the interfaces in the network namespace are destroyed. - When a `veth` interface is destroyed, it also destroys the other half of the pair. - So we don't have anything else to do to clean up! .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Docker options leveraging network namespaces - `--net none` gives an empty network namespace to a container (effectively isolating it completely from the network) - `--net host` means "do not containerize the network" (no network namespace is created; the container uses the host network stack) - `--net container` means "reuse the network namespace of another container" (as a result, both containers share the same interfaces, routes, etc.) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Mnt namespace - Processes can have their own root fs (à la chroot) - Processes can also have "private" mounts; this allows: - isolating `/tmp` (per user, per service...) - masking `/proc`, `/sys` (for processes that don't need them) - mounting remote filesystems or sensitive data, <br/>but make it visible only for allowed processes - Mounts can be totally private, or shared - For a long time, there was no easy way to "move" a mount to another namespace - It's now possible; see [justincormack/addmount](https://github.com/justincormack/addmount) for a simple example .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## Setting up a private `/tmp` Create a new mount namespace: ```bash $ sudo unshare --mount ``` In that new namespace, mount a brand new `/tmp`: ```bash # mount -t tmpfs none /tmp ``` Check the content of `/tmp` in the new namespace, and compare to the host. The mount is automatically cleaned up when you exit the process. .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## PID namespace - Processes within a PID namespace only "see" processes in the same PID namespace - Each PID namespace has its own numbering (starting at 1) - When PID 1 goes away, the whole namespace is killed (when PID 1 goes away on a normal UNIX system, the kernel panics!) - Those namespaces can be nested - A process ends up having multiple PIDs (one per namespace in which it is nested) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## PID namespace in action Create a new PID namespace: ```bash $ sudo unshare --pid --fork ``` (We need the `--fork` flag because the PID namespace is special.) Check the process tree in the new namespace: ```bash # ps faux ``` -- class: extra-details, deep-dive 🤔 Why do we see all the processes?!? .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## PID namespaces and `/proc` - Tools like `ps` rely on the `/proc` pseudo-filesystem - Our new namespace still has access to the original `/proc` - Therefore, it still sees host processes - But it cannot affect them (try to `kill` a process: you will get `No such process`) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## PID namespaces, take 2 - This can be solved by mounting `/proc` in the namespace - The `unshare` utility provides a convenience flag, `--mount-proc` - This flag will mount `/proc` in the namespace - It will also unshare the mount namespace, so that this mount is local Try it: ```bash $ sudo unshare --pid --fork --mount-proc # ps faux ``` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## OK, really, why do we need `--fork`? *It is not necessary to remember all these details. <br/> This is just an illustration of the complexity of namespaces!* The `unshare` tool calls the `unshare` syscall, then `exec`s the new binary. <br/> A process calling `unshare` to create new namespaces is moved to the new namespaces... <br/> ... Except for the PID namespace. <br/> (Because this would change the current PID of the process from X to 1.) The processes created by the new binary are placed into the new PID namespace. <br/> The first one will be PID 1. <br/> If PID 1 exits, it is not possible to create additional processes in the namespace. <br/> (Attempting to do so will result in `ENOMEM`.) Without the `--fork` flag, the first command that we execute will be PID 1 ... <br/> ... And once it exits, we cannot create more processes in the namespace! Check `man 2 unshare` and `man pid_namespaces` if you want more details. .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## IPC namespace -- - Does anybody know about IPC? -- - Does anybody *care* about IPC? -- - Allows a process (or group of processes) to have own: - IPC semaphores - IPC message queues - IPC shared memory ... without risk of conflict with other instances. - Older versions of PostgreSQL cared about this. *No demo for that one.* .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## User namespace - Allows mapping UID/GID; e.g.: - UID 0→1999 in container C1 is mapped to UID 10000→11999 on host - UID 0→1999 in container C2 is mapped to UID 12000→13999 on host - etc. - UID 0 in the container can still perform privileged operations in the container (for instance: setting up network interfaces) - But outside of the container, it is a non-privileged user - It also means that the UID in containers becomes unimportant (just use UID 0 in the container, since it gets squashed to a non-privileged user outside) - Ultimately enables better privilege separation in container engines .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details, deep-dive ## User namespace challenges - UID needs to be mapped when passed between processes or kernel subsystems - Filesystem permissions and file ownership are more complicated .small[(e.g. when the same root filesystem is shared by multiple containers running with different UIDs)] - With the Docker Engine: - some feature combinations are not allowed <br/> (e.g. user namespace + host network namespace sharing) - user namespaces need to be enabled/disabled globally <br/> (when the daemon is started) - container images are stored separately <br/> (so the first time you toggle user namespaces, you need to re-pull images) *No demo for that one.* .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Time namespace - Virtualize time - Expose a slower/faster clock to some processes (for e.g. simulation purposes) - Expose a clock offset to some processes (simulation, suspend/restore...) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Cgroup namespace - Virtualize access to `/proc/<PID>/cgroup` - Lets containerized processes view their relative cgroup tree .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: pic .interstitial[] --- name: toc-security-features class: title Security features .nav[ [Previous part](#toc-namespaces) | [Back to table of contents](#toc-part-8) | [Next part](#toc-copy-on-write-filesystems) ] .debug[(automatically generated title slide)] --- # Security features - Namespaces and cgroups are not enough to ensure strong security - We need extra mechanisms: capabilities, seccomp, LSMs - These mechanisms were already used before containers to harden security - They can be used together with containers - Good container engines will automatically leverage these features. (so that you don't have to worry about it) .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Capabilities - In traditional UNIX, many operations are possible if and only if UID=0 (root) - Some of these operations are very powerful: - changing file ownership, accessing all files ... - Some of these operations deal with system configuration, but can be abused: - setting up network interfaces, mounting filesystems ... - Some of these operations are not very dangerous but are needed by servers: - binding to a port below 1024. - Capabilities are per-process flags to allow these operations individually .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Some capabilities - `CAP_CHOWN`: arbitrarily change file ownership and permissions - `CAP_DAC_OVERRIDE`: arbitrarily bypass file ownership and permissions - `CAP_NET_ADMIN`: configure network interfaces, iptables rules, etc. - `CAP_NET_BIND_SERVICE`: bind a port below 1024 See `man capabilities` for the full list and details .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Using capabilities - Container engines will typically drop all "dangerous" capabilities - You can then re-enable capabilities on a per-container basis, as needed - With the Docker engine: `docker run --cap-add ...` - From the shell: `capsh --drop=cap_net_admin --` `capsh --drop=all --` .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## File capabilities - It is also possible to give capabilities to executable files - This is comparable to the SUID bit, but with finer grain (e.g., `setcap cap_net_raw+ep /bin/ping`) - There are differences between *permitted* and *inheritable* capabilities... 🤔 .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: extra-details ## Capability sets - Permitted set (=what a process could use, provided the file has the cap) - Effective set (=what a process can actually use) - Inheritable set (=capabilities preserved across exexcve calls) - Bounding set (=system-wide limit over what can be acquired through execve / capset) - Ambient set (=capabilities retained across execve for non-privileged users) - Files can have *permitted*, *effective*, *inheritable* capability sets .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## More about capabilities - Capabilities manpage: https://man7.org/linux/man-pages/man7/capabilities.7.html - Subtleties about `capsh`: https://sites.google.com/site/fullycapable/why-didnt-that-work .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Seccomp - Seccomp is secure computing. - Achieve high level of security by restricting drastically available syscalls. - Original seccomp only allows `read()`, `write()`, `exit()`, `sigreturn()`. - The seccomp-bpf extension allows specifying custom filters with BPF rules. - This allows filtering by syscall, and by parameter. - BPF code can perform arbitrarily complex checks, quickly, and safely. - Container engines take care of this so you don't have to. .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- ## Linux Security Modules - The most popular ones are SELinux and AppArmor. - Red Hat distros generally use SELinux. - Debian distros (in particular, Ubuntu) generally use AppArmor. - LSMs add a layer of access control to all process operations. - Container engines take care of this so you don't have to. ??? :EN:Containers internals :EN:- Control groups (cgroups) :EN:- Linux kernel namespaces :FR:Fonctionnement interne des conteneurs :FR:- Les "control groups" (cgroups) :FR:- Les namespaces du noyau Linux .debug[[containers/Namespaces_Cgroups.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Namespaces_Cgroups.md)] --- class: pic .interstitial[] --- name: toc-copy-on-write-filesystems class: title Copy-on-write filesystems .nav[ [Previous part](#toc-security-features) | [Back to table of contents](#toc-part-8) | [Next part](#toc-building-containers-from-scratch) ] .debug[(automatically generated title slide)] --- # Copy-on-write filesystems Container engines rely on copy-on-write to be able to start containers quickly, regardless of their size. We will explain how that works, and review some of the copy-on-write storage systems available on Linux. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## What is copy-on-write? - Copy-on-write is a mechanism allowing to share data. - The data appears to be a copy, but is only a link (or reference) to the original data. - The actual copy happens only when someone tries to change the shared data. - Whoever changes the shared data ends up using their own copy instead of the shared data. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## A few metaphors -- - First metaphor: <br/>white board and tracing paper -- - Second metaphor: <br/>magic books with shadowy pages -- - Third metaphor: <br/>just-in-time house building .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Copy-on-write is *everywhere* - Process creation with `fork()`. - Consistent disk snapshots. - Efficient VM provisioning. - And, of course, containers. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Copy-on-write and containers Copy-on-write is essential to give us "convenient" containers. - Creating a new container (from an existing image) is "free". (Otherwise, we would have to copy the image first.) - Customizing a container (by tweaking a few files) is cheap. (Adding a 1 KB configuration file to a 1 GB container takes 1 KB, not 1 GB.) - We can take snapshots, i.e. have "checkpoints" or "save points" when building images. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## AUFS overview - The original (legacy) copy-on-write filesystem used by first versions of Docker. - Combine multiple *branches* in a specific order. - Each branch is just a normal directory. - You generally have: - at least one read-only branch (at the bottom), - exactly one read-write branch (at the top). (But other fun combinations are possible too!) .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## AUFS operations: opening a file - With `O_RDONLY` - read-only access: - look it up in each branch, starting from the top - open the first one we find - With `O_WRONLY` or `O_RDWR` - write access: - if the file exists on the top branch: open it - if the file exists on another branch: "copy up" <br/> (i.e. copy the file to the top branch and open the copy) - if the file doesn't exist on any branch: create it on the top branch That "copy-up" operation can take a while if the file is big! .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## AUFS operations: deleting a file - A *whiteout* file is created. - This is similar to the concept of "tombstones" used in some data systems. ``` # docker run ubuntu rm /etc/shadow # ls -la /var/lib/docker/aufs/diff/$(docker ps --no-trunc -lq)/etc total 8 drwxr-xr-x 2 root root 4096 Jan 27 15:36 . drwxr-xr-x 5 root root 4096 Jan 27 15:36 .. -r--r--r-- 2 root root 0 Jan 27 15:36 .wh.shadow ``` .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## AUFS performance - AUFS `mount()` is fast, so creation of containers is quick. - Read/write access has native speeds. - But initial `open()` is expensive in two scenarios: - when writing big files (log files, databases ...), - when searching many directories (PATH, classpath, etc.) over many layers. - Protip: when we built dotCloud, we ended up putting all important data on *volumes*. - When starting the same container multiple times: - the data is loaded only once from disk, and cached only once in memory; - but `dentries` will be duplicated. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Device Mapper Device Mapper is a rich subsystem with many features. It can be used for: RAID, encrypted devices, snapshots, and more. In the context of containers (and Docker in particular), "Device Mapper" means: "the Device Mapper system + its *thin provisioning target*" If you see the abbreviation "thinp" it stands for "thin provisioning". .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Device Mapper principles - Copy-on-write happens on the *block* level (instead of the *file* level). - Each container and each image get their own block device. - At any given time, it is possible to take a snapshot: - of an existing container (to create a frozen image), - of an existing image (to create a container from it). - If a block has never been written to: - it's assumed to be all zeros, - it's not allocated on disk. (That last property is the reason for the name "thin" provisioning.) .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Device Mapper operational details - Two storage areas are needed: one for *data*, another for *metadata*. - "data" is also called the "pool"; it's just a big pool of blocks. (Docker uses the smallest possible block size, 64 KB.) - "metadata" contains the mappings between virtual offsets (in the snapshots) and physical offsets (in the pool). - Each time a new block (or a copy-on-write block) is written, a block is allocated from the pool. - When there are no more blocks in the pool, attempts to write will stall until the pool is increased (or the write operation aborted). - In other words: when running out of space, containers are frozen, but operations will resume as soon as space is available. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Device Mapper performance - By default, Docker puts data and metadata on a loop device backed by a sparse file. - This is great from a usability point of view, since zero configuration is needed. - But it is terrible from a performance point of view: - each time a container writes to a new block, - a block has to be allocated from the pool, - and when it's written to, - a block has to be allocated from the sparse file, - and sparse file performance isn't great anyway. - If you use Device Mapper, make sure to put data (and metadata) on devices! .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## BTRFS principles - BTRFS is a filesystem (like EXT4, XFS, NTFS...) with built-in snapshots. - The "copy-on-write" happens at the filesystem level. - BTRFS integrates the snapshot and block pool management features at the filesystem level. (Instead of the block level for Device Mapper.) - In practice, we create a "subvolume" and later take a "snapshot" of that subvolume. Imagine: `mkdir` with Super Powers and `cp -a` with Super Powers. - These operations can be executed with the `btrfs` CLI tool. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## BTRFS in practice with Docker - Docker can use BTRFS and its snapshotting features to store container images. - The only requirement is that `/var/lib/docker` is on a BTRFS filesystem. (Or, the directory specified with the `--data-root` flag when starting the engine.) .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- class: extra-details ## BTRFS quirks - BTRFS works by dividing its storage in *chunks*. - A chunk can contain data or metadata. - You can run out of chunks (and get `No space left on device`) even though `df` shows space available. (Because chunks are only partially allocated.) - Quick fix: ``` # btrfs filesys balance start -dusage=1 /var/lib/docker ``` .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Overlay2 - Overlay2 is very similar to AUFS. - However, it has been merged in "upstream" kernel. - It is therefore available on all modern kernels. (AUFS was available on Debian and Ubuntu, but required custom kernels on other distros.) - It is simpler than AUFS (it can only have two branches, called "layers"). - The container engine abstracts this detail, so this is not a concern. - Overlay2 storage drivers generally use hard links between layers. - This improves `stat()` and `open()` performance, at the expense of inode usage. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## ZFS - ZFS is similar to BTRFS (at least from a container user's perspective). - Pros: - high performance - high reliability (with e.g. data checksums) - optional data compression and deduplication - Cons: - high memory usage - not in upstream kernel - It is available as a kernel module or through FUSE. .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- ## Which one is the best? - In modern (2015+) systems, overlay2 should be the best option. - Its memory usage is better than Device Mapper, BTRFS, or ZFS. - The remarks about *write performance* shouldn't bother you: <br/> data should always be stored in volumes anyway! ??? :EN:- Copy-on-write filesystems :EN:- Docker graph drivers :FR:- Les systèmes de fichiers "copy-on-write" :FR:- Les "graph drivers" de Docker .debug[[containers/Copy_On_Write.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Copy_On_Write.md)] --- class: pic .interstitial[] --- name: toc-building-containers-from-scratch class: title Building containers from scratch .nav[ [Previous part](#toc-copy-on-write-filesystems) | [Back to table of contents](#toc-part-8) | [Next part](#toc-security-models) ] .debug[(automatically generated title slide)] --- # Building containers from scratch (This is a "bonus section" done if time permits.) .debug[[containers/Containers_From_Scratch.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Containers_From_Scratch.md)] --- class: pic .interstitial[] --- name: toc-security-models class: title Security models .nav[ [Previous part](#toc-building-containers-from-scratch) | [Back to table of contents](#toc-part-8) | [Next part](#toc-rootless-networking) ] .debug[(automatically generated title slide)] --- # Security models In this section, we want to address a few security-related questions: - What permissions do we need to run containers or a container engine? - Can we use containers to escalate permissions? - Can we break out of a container (move from container to host)? - Is it safe to run untrusted code in containers? - What about Kubernetes? .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Running Docker, containerd, podman... - In the early days, running containers required root permissions (to set up namespaces, cgroups, networking, mount filesystems...) - Eventually, new kernel features were developed to allow "rootless" operation (user namespaces and associated tweaks) - Rootless requires a little bit of additional setup on the system (e.g. subuid) (although this is increasingly often automated in modern distros) - Docker runs as root by default; Podman runs rootless by default .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Advantages of rootless - Containers can run without any intervention from root (no package install, no daemon running as root...) - Containerized processes run with non-privileged UID - Container escape doesn't automatically result in full host compromise - Can isolate workloads by using different UID .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Downsides of rootless - *Relatively* newer (rootless Docker was introduced in 2019) - many quirks/issues/limitations in the initial implementations - kernel features and other mechanisms were introduced over time - they're not always very well documented - I/O performance (disk, network) is typically lower (due to using special mechanisms instead of more direct access) - Rootless and rootful engines must use different image storage (due to UID mapping) .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Why not rootless everywhere? - Not very useful on clusters - users shouldn't log into cluster nodes - questionable security improvement - lower I/O performance - Not very useful with Docker Desktop / Podman Desktop - container workloads are already inside a VM - could arguably provide a layer of inter-workload isolation - would require new APIs and concepts .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Permission escalation - Access to the Docker socket = root access to the machine ```bash docker run --privileged -v /:/hostfs -ti alpine ``` - That's why by default, the Docker socket access is locked down (only accessible by `root` and group `docker`) - If user `alice` has access to the Docker socket: *compromising user `alice` leads to whole host compromise!* - Doesn't fundamentally change the threat model (if `alice` gets compromised in the first place, we're in trouble!) - Enables new threats (persistence, kernel access...) .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Avoiding the problem - Rootless containers - Container VM (Docker Desktop, Podman Desktop, Orbstack...) - Unfortunately: no fine-grained access to the Docker API (no way to e.g. disable privileged containers, volume mounts...) .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Escaping containers - Very easy with some features (privileged containers, volume mounts, device access) - Otherwise impossible in theory (but of course, vulnerabilities do exist!) - **Be careful with scripts invoking `docker run`, or Compose files!** .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## Untrusted code - Should be safe as long as we're not enabling dangerous features (privileged containers, volume mounts, device access, capabilities...) - Remember that by default, containers can make network calls (but see: `--net none` and also `docker network create --internal`) - And of course, again: vulnerabilities do exist! .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- ## What about Kubernetes? - Ability to run arbitrary pods = dangerous - But there are multiple safety mechanisms available: - Pod Security Settings (limit "dangerous" features) - RBAC (control who can do what) - webhooks and policy engines for even finer grained control .debug[[containers/Security.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Security.md)] --- class: pic .interstitial[] --- name: toc-rootless-networking class: title Rootless Networking .nav[ [Previous part](#toc-security-models) | [Back to table of contents](#toc-part-8) | [Next part](#toc-deep-dive-into-images) ] .debug[(automatically generated title slide)] --- # Rootless Networking The "classic" approach for container networking is `veth` + bridge. Pros: - good performance - easy to manage and understand - flexible (possibility to use multiple, isolated bridges) Cons: - requires root access on the host to set up networking .debug[[containers/Rootless_Networking.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Rootless_Networking.md)] --- ## Rootless options - Locked down helpers - daemon, scripts started through sudo... - used by some desktop virtualization platforms - still requires root access at some point - Userland networking stacks - true solution that does not require root privileges - lower performance .debug[[containers/Rootless_Networking.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Rootless_Networking.md)] --- ## Userland stacks - [SLiRP](https://en.wikipedia.org/wiki/Slirp) *the OG project that inspired the other ones!* - [VPNKit](https://github.com/moby/vpnkit) *introduced by Docker Desktop to play nice with enterprise VPNs* - [slirp4netns](https://github.com/rootless-containers/slirp4netns) *slirp adapted for network namespaces, and therefore, containers; better performance* - [passt and pasta](https://passt.top/) *more modern approach; better support for inbound traffic; IPv6...)* .debug[[containers/Rootless_Networking.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Rootless_Networking.md)] --- ## Passt/Pasta - No dependencies - NAT (like slirp4netns) or no-NAT (for e.g. KubeVirt) - Can handle inbound traffic dynamically - No dynamic memory allocation - Good security posture - IPv6 support - Reasonable performance .debug[[containers/Rootless_Networking.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Rootless_Networking.md)] --- ## Demo? .debug[[containers/Rootless_Networking.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Rootless_Networking.md)] --- class: pic .interstitial[] --- name: toc-deep-dive-into-images class: title Deep Dive Into Images .nav[ [Previous part](#toc-rootless-networking) | [Back to table of contents](#toc-part-8) | [Next part](#toc-docker-engine-and-other-container-engines) ] .debug[(automatically generated title slide)] --- # Deep Dive Into Images - Image = files (layers) + metadata (configuration) - Layers = regular tar archives (potentially with *whiteouts*) - Configuration = everything needed to run the container (e.g. Cmd, Env, WorkdingDir...) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Image formats - Docker image [v1] (no longer used, except in `docker save` and `docker load`) - Docker image v1.1 (IDs are now hashes instead of random values) - Docker image [v2] (multi-arch support; content-addressable images) - [OCI image format][oci] (almost the same, except for media types) [v1]: https://github.com/moby/docker-image-spec?tab=readme-ov-file [v2]: https://github.com/distribution/distribution/blob/main/docs/content/spec/manifest-v2-2.md [oci]: https://github.com/opencontainers/image-spec/blob/main/spec.md .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## OCI images - Manifest = JSON document - Used by container engines to know "what should I download to unpack this image?" - Contains references to blobs, identified by their sha256 digest + size - config (single sha256 digest) - layers (list of sha256 digests) - Also annotations (key/values) - It's also possible to have a manifest list, or "fat manifest" (which lists multiple manifests; this is used for multi-arch support) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Config blob - Also a JSON document - `architecture` string (e.g. `amd64`) - `config` object Cmd, Entrypoint, Env, ExposedPorts, StopSignal, User, Volumes, WorkingDir - `history` list purely informative; shown with e.g. `docker history` - `rootfs` object `type` (always `layers`) + list of "diff ids" .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- class: extra-details ## Layers vs layers - The image configuration contains digests of *uncompressed layers* - The image manifest contains digests of *compressed layers* (layer blobs in the registry can be tar, tar+gzip, tar+zstd) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Layer format - Layer = completely normal tar archive - When a file is added or modified, it is added to the archive (note: trivial changes, e.g. permissions, require to re-add the whole file!) - When a file is deleted, a *whiteout* file is created e.g. `rm hello.txt` results in a file named `.wh.hello.txt` - Files starting with `.wh.` are forbidden in containers - There is a special file, `.wh..wh..opq`, which means "remove all siblings" (optimization to completely empty a directory) - See [layer specification](https://github.com/opencontainers/image-spec/blob/main/layer.md) for details .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- class: extra-details ## Origin of layer format - The initial storage driver for Docker was AUFS - AUFS is out-of-tree but Debian and Ubuntu included it (they used it for live CD / live USB boot) - It meant that Docker could work out of the box on these distros - Later, Docker added support for other systems (devicemapper thin provisioning, btrfs, overlay...) - Today, overlay is the best compromise for most use-cases .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Inspecting images - `skopeo` can copy images between different places (registries, Docker Engine, local storage as used by podman...) - Example: ```bash skopeo copy docker://alpine oci:/tmp/alpine.oci ``` - The image manifest will be in `/tmp/alpine.oci/index.json` - Blobs (image configuration and layers) will be in `/tmp/alpine.oci/blobs/sha256` - Note: as of version 1.20, `skopeo` doesn't handle extensions like stargz yet (copying stargz images won't transfer the special index blobs) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Layer surgery Here is an example of how to manually edit an image. https://github.com/jpetazzo/layeremove It removes a specific layer from an image. Note: it would be better to use a buildkit cache mount instead. (This is just an educative example!) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Stargz - [Stargz] = Seekable Tar Gz, or "stargazer" - Goal: start a container *before* its image has been fully downloaded - Particularly useful for huge images that take minutes to download - Also known as "streamable images" or "lazy loading" - Alternative: [SOCI] [stargz]: https://github.com/containerd/stargz-snapshotter [SOCI]: https://github.com/awslabs/soci-snapshotter .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Stargz architecture - Combination of: - a backward-compatible extension to the OCI image format - a containerd *snapshotter* (=containerd component responsible for managing container and image storage) - tooling to create, convert, optimize images - Installation requires: - running the snapshotter daemon - configuring containerd - building new images or converting the existing ones .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Stargz principle - Normal image layer = tar.gz = gzip(tar(file1, file2, ...)) - Can't access fileN without uncompressing everything before it - Seekable Tar Gz = gzip(tar(file1)) + gzip(tar(file2)) + ... + index (big files can also be chunked) - Can access individual files (and even individual chunks, if needed) - Downside: lower compression ratio (less compression context; extra gzip headers) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Stargz format - The index mentioned above is stored in separate registry blobs (one index for each layer) - The digest of the index blobs is stored in annotations in normal OCI images - Fully compatible with existing registries - Existing container engines will load images transparently (without leveraging stargz capabilities) .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- ## Stargz limitations - Tools like `skopeo` will ignore index blobs (=copying images across registries will discard stargz capabilities) - Indexes need to be downloaded before container can be started (=still significant start time when there are many files in images) - Significant latency when accessing a file lazily (need to hit the registry, typically with a range header, uncompress file) - Images can be optimized to pre-load important files .debug[[containers/Images_Deep_Dive.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Images_Deep_Dive.md)] --- class: pic .interstitial[] --- name: toc-docker-engine-and-other-container-engines class: title Docker Engine and other container engines .nav[ [Previous part](#toc-deep-dive-into-images) | [Back to table of contents](#toc-part-9) | [Next part](#toc-container-super-structure) ] .debug[(automatically generated title slide)] --- # Docker Engine and other container engines * We are going to cover the architecture of the Docker Engine. * We will also present other container engines. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- class: pic ## Docker Engine external architecture  .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## Docker Engine external architecture * The Engine is a daemon (service running in the background). * All interaction is done through a REST API exposed over a socket. * On Linux, the default socket is a UNIX socket: `/var/run/docker.sock`. * We can also use a TCP socket, with optional mutual TLS authentication. * The `docker` CLI communicates with the Engine over the socket. Note: strictly speaking, the Docker API is not fully REST. Some operations (e.g. dealing with interactive containers and log streaming) don't fit the REST model. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- class: pic ## Docker Engine internal architecture 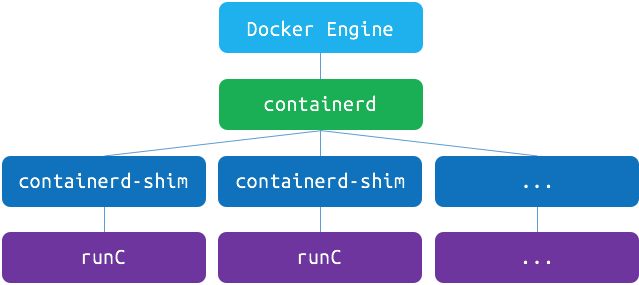 .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## Docker Engine internal architecture * Up to Docker 1.10: the Docker Engine is one single monolithic binary. * Starting with Docker 1.11, the Engine is split into multiple parts: - `dockerd` (REST API, auth, networking, storage) - `containerd` (container lifecycle, controlled over a gRPC API) - `containerd-shim` (per-container; does almost nothing but allows to restart the Engine without restarting the containers) - `runc` (per-container; does the actual heavy lifting to start the container) * Some features (like image and snapshot management) are progressively being pushed from `dockerd` to `containerd`. For more details, check [this short presentation by Phil Estes](https://www.slideshare.net/PhilEstes/diving-through-the-layers-investigating-runc-containerd-and-the-docker-engine-architecture). .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## Other container engines The following list is not exhaustive. Furthermore, we limited the scope to Linux containers. We can also find containers (or things that look like containers) on other platforms like Windows, macOS, Solaris, FreeBSD ... .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## LXC * The venerable ancestor (first released in 2008). * Docker initially relied on it to execute containers. * No daemon; no central API. * Each container is managed by a `lxc-start` process. * Each `lxc-start` process exposes a custom API over a local UNIX socket, allowing to interact with the container. * No notion of image (container filesystems had be managed manually). * Networking had to be set up manually. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## LXD * Re-uses LXC code (through liblxc). * Builds on top of LXC to offer a more modern experience. * Daemon exposing a REST API. * Can run containers and virtual machines. * Can manage images, snapshots, migrations, networking, storage. * "offers a user experience similar to virtual machines but using Linux containers instead." * Driven by Canonical. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## Incus * Community-driven fork of LXD. * Relatively recent [announced in August 2023](https://linuxcontainers.org/incus/announcement/) so time will tell what the notable differences will be. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## CRI-O * Designed to be used with Kubernetes as a simple, basic runtime. * Compares to `containerd`. * Daemon exposing a gRPC interface. * Controlled using the CRI API (Container Runtime Interface defined by Kubernetes). * Needs an underlying OCI runtime (e.g. runc). * Handles storage, images, networking (through CNI plugins). We're not aware of anyone using it directly (i.e. outside of Kubernetes). .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## systemd * "init" system (PID 1) in most modern Linux distributions. * Offers tools like `systemd-nspawn` and `machinectl` to manage containers. * `systemd-nspawn` is "In many ways it is similar to chroot(1), but more powerful". * `machinectl` can interact with VMs and containers managed by systemd. * Exposes a DBUS API. * Basic image support (tar archives and raw disk images). * Network has to be set up manually. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## [Kata containers](https://katacontainers.io/) * OCI-compliant runtime. * Fusion of two projects: Intel Clear Containers and Hyper runV. * Run each container in a lightweight virtual machine. * Requires running on bare metal *or* with nested virtualization. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## [gVisor](https://gvisor.dev/) * OCI-compliant runtime. * Implements a subset of the Linux kernel system calls. * Written in go, uses a smaller subset of system calls. * Can be heavily sandboxed. * Can run in two modes: * KVM (requires bare metal or nested virtualization), * ptrace (no requirement, but slower). .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## Others - Micro VMs: Firecracker, Edera... - [crun](https://github.com/containers/crun) (runc rewritten in C) - [youki](https://youki-dev.github.io/youki/) (runc rewritten in Rust) .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## To Docker Or Not To Docker * The Docker Engine is very developer-centric: - easy to install - easy to use - no manual setup - first-class image build and transfer * As a result, it is a fantastic tool in development environments. * On Kubernetes clusters, containerd or CRI-O are better choices. * On Kubernetes clusters, the container engine is an implementation detail. .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- ## Different levels - Directly use namespaces, cgroups, capabilities with custom code or scripts *useful for troubleshooting/debugging and for educative purposes; e.g. pipework* - Use low-level engines like runc, crun, youki *useful when building custom architectures; e.g. a brand new orchestrator* - Use low-level APIs like CRI or containerd grpc API *useful to achieve high-level features like Docker, but without Docker; e.g. ctr, nerdctl* - Use high-level APIs like Docker and Kubernetes *that's what most people will do* .debug[[containers/Container_Engines.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Container_Engines.md)] --- class: pic .interstitial[] --- name: toc-container-super-structure class: title Container Super-structure .nav[ [Previous part](#toc-docker-engine-and-other-container-engines) | [Back to table of contents](#toc-part-9) | [Next part](#toc-the-container-ecosystem) ] .debug[(automatically generated title slide)] --- # Container Super-structure - Multiple orchestration platforms support some kind of container super-structure. (i.e., a construct or abstraction bigger than a single container.) - For instance, on Kubernetes, this super-structure is called a *pod*. - A pod is a group of containers (it could be a single container, too). - These containers run together, on the same host. (A pod cannot straddle multiple hosts.) - All the containers in a pod have the same IP address. - How does that map to the Docker world? .debug[[containers/Pods_Anatomy.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Pods_Anatomy.md)] --- class: pic ## Anatomy of a Pod  .debug[[containers/Pods_Anatomy.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Pods_Anatomy.md)] --- ## Pods in Docker - The containers inside a pod share the same network namespace. (Just like when using `docker run --net=container:<container_id>` with the CLI.) - As a result, they can communicate together over `localhost`. - In addition to "our" containers, the pod has a special container, the *sandbox*. - That container uses a special image: `k8s.gcr.io/pause`. (This is visible when listing containers running on a Kubernetes node.) - Containers within a pod have independent filesystems. - They can share directories by using a mechanism called *volumes.* (Which is similar to the concept of volumes in Docker.) .debug[[containers/Pods_Anatomy.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Pods_Anatomy.md)] --- class: pic .interstitial[] --- name: toc-the-container-ecosystem class: title The container ecosystem .nav[ [Previous part](#toc-container-super-structure) | [Back to table of contents](#toc-part-9) | [Next part](#toc-orchestration-an-overview) ] .debug[(automatically generated title slide)] --- # The container ecosystem In this chapter, we will talk about a few actors of the container ecosystem. We have (arbitrarily) decided to focus on two groups: - the Docker ecosystem, - the Cloud Native Computing Foundation (CNCF) and its projects. .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- class: pic ## The Docker ecosystem 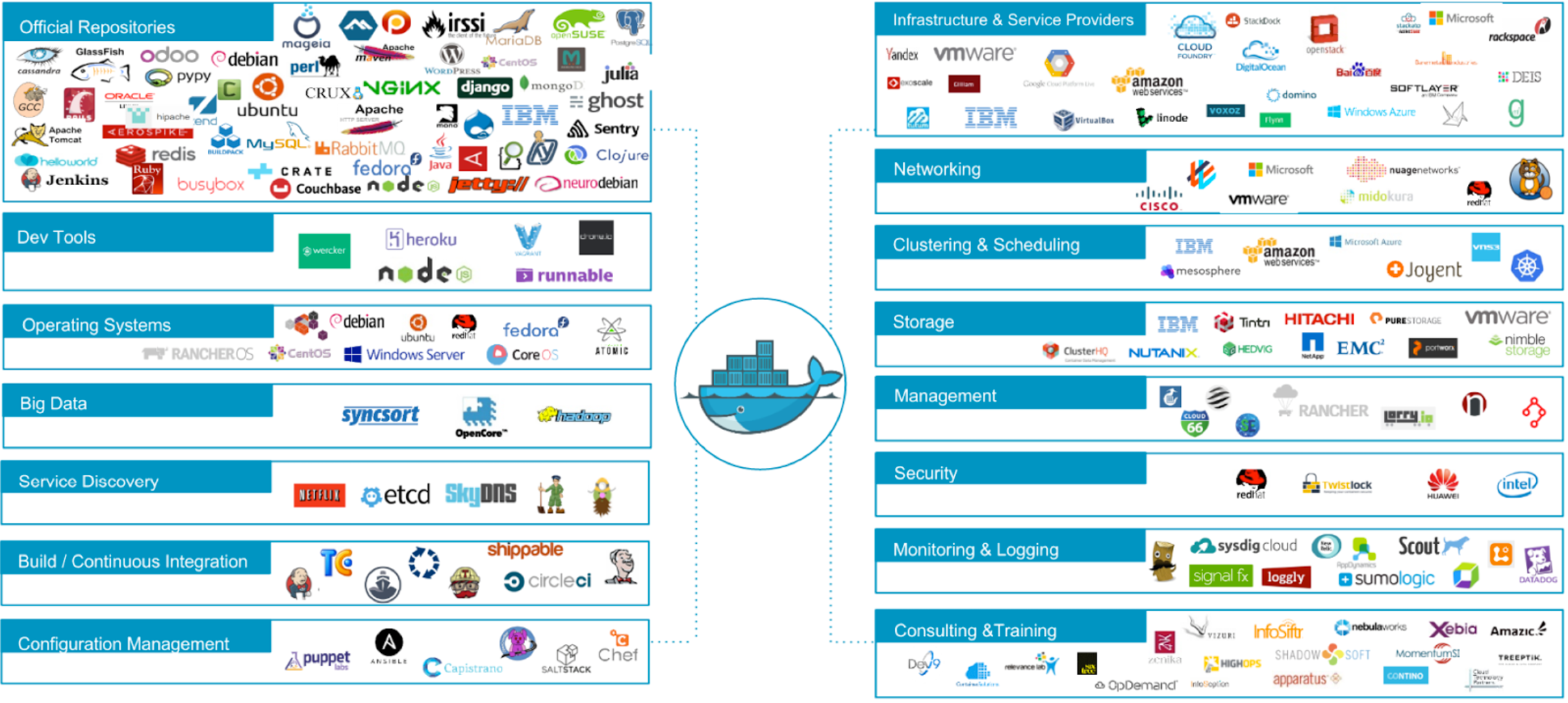 .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## Moby vs. Docker - Docker Inc. (the company) started Docker (the open source project). - At some point, it became necessary to differentiate between: - the open source project (code base, contributors...), - the product that we use to run containers (the engine), - the platform that we use to manage containerized applications, - the brand. .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- class: pic  .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## Exercise in brand management Questions: -- - What is the brand of the car on the previous slide? -- - What kind of engine does it have? -- - Would you say that it's a safe or unsafe car? -- - Harder question: can you drive from the US West to East coasts with it? -- The answers to these questions are part of the Tesla brand. .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## What if ... - The blueprints for Tesla cars were available for free. - You could legally build your own Tesla. - You were allowed to customize it entirely. (Put a combustion engine, drive it with a game pad ...) - You could even sell the customized versions. -- - ... And call your customized version "Tesla". -- Would we give the same answers to the questions on the previous slide? .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## From Docker to Moby - Docker Inc. decided to split the brand. - Moby is the open source project. (= Components and libraries that you can use, reuse, customize, sell ...) - Docker is the product. (= Software that you can use, buy support contracts ...) - Docker is made with Moby. - When Docker Inc. improves the Docker products, it improves Moby. (And vice versa.) .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## Other examples - *Read the Docs* is an open source project to generate and host documentation. - You can host it yourself (on your own servers). - You can also get hosted on readthedocs.org. - The maintainers of the open source project often receive support requests from users of the hosted product ... - ... And the maintainers of the hosted product often receive support requests from users of self-hosted instances. - Another example: *WordPress.com is a blogging platform that is owned and hosted online by Automattic. It is run on WordPress, an open source piece of software used by bloggers. (Wikipedia)* .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## Docker CE vs Docker EE - Docker CE = Community Edition. - Available on most Linux distros, Mac, Windows. - Optimized for developers and ease of use. - Docker EE = Enterprise Edition. - Available only on a subset of Linux distros + Windows servers. (Only available when there is a strong partnership to offer enterprise-class support.) - Optimized for production use. - Comes with additional components: security scanning, RBAC ... .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- ## The CNCF - Non-profit, part of the Linux Foundation; founded in December 2015. *The Cloud Native Computing Foundation builds sustainable ecosystems and fosters a community around a constellation of high-quality projects that orchestrate containers as part of a microservices architecture.* *CNCF is an open source software foundation dedicated to making cloud-native computing universal and sustainable.* - Home of Kubernetes (and many other projects now). - Funded by corporate memberships. .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- class: pic  .debug[[containers/Ecosystem.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Ecosystem.md)] --- class: pic .interstitial[] --- name: toc-orchestration-an-overview class: title Orchestration, an overview .nav[ [Previous part](#toc-the-container-ecosystem) | [Back to table of contents](#toc-part-9) | [Next part](#toc-links-and-resources) ] .debug[(automatically generated title slide)] --- # Orchestration, an overview In this chapter, we will: * Explain what is orchestration and why we would need it. * Present (from a high-level perspective) some orchestrators. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## What's orchestration?  .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## What's orchestration? According to Wikipedia: *Orchestration describes the __automated__ arrangement, coordination, and management of complex computer systems, middleware, and services.* -- *[...] orchestration is often discussed in the context of __service-oriented architecture__, __virtualization__, provisioning, Converged Infrastructure and __dynamic datacenter__ topics.* -- What does that really mean? .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Example 1: dynamic cloud instances -- - Q: do we always use 100% of our servers? -- - A: obviously not! .center[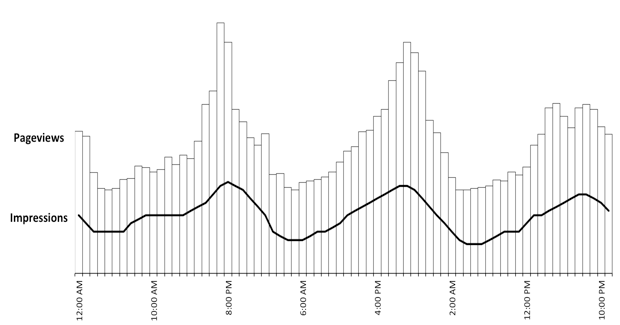] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Example 1: dynamic cloud instances - Every night, scale down (by shutting down extraneous replicated instances) - Every morning, scale up (by deploying new copies) - "Pay for what you use" (i.e. save big $$$ here) .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Example 1: dynamic cloud instances How do we implement this? - Crontab - Autoscaling (save even bigger $$$) That's *relatively* easy. Now, how are things for our IAAS provider? .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Example 2: dynamic datacenter - Q: what's the #1 cost in a datacenter? -- - A: electricity! -- - Q: what uses electricity? -- - A: servers, obviously - A: ... and associated cooling -- - Q: do we always use 100% of our servers? -- - A: obviously not! .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Example 2: dynamic datacenter - If only we could turn off unused servers during the night... - Problem: we can only turn off a server if it's totally empty! (i.e. all VMs on it are stopped/moved) - Solution: *migrate* VMs and shutdown empty servers (e.g. combine two hypervisors with 40% load into 80%+0%, <br/>and shut down the one at 0%) .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Example 2: dynamic datacenter How do we implement this? - Shut down empty hosts (but keep some spare capacity) - Start hosts again when capacity gets low - Ability to "live migrate" VMs (Xen already did this 10+ years ago) - Rebalance VMs on a regular basis - what if a VM is stopped while we move it? - should we allow provisioning on hosts involved in a migration? *Scheduling* becomes more complex. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## What is scheduling? According to Wikipedia (again): *In computing, scheduling is the method by which threads, processes or data flows are given access to system resources.* The scheduler is concerned mainly with: - throughput (total amount of work done per time unit); - turnaround time (between submission and completion); - response time (between submission and start); - waiting time (between job readiness and execution); - fairness (appropriate times according to priorities). In practice, these goals often conflict. **"Scheduling" = decide which resources to use.** .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Exercise 1 - You have: - 5 hypervisors (physical machines) - Each server has: - 16 GB RAM, 8 cores, 1 TB disk - Each week, your team requests: - one VM with X RAM, Y CPU, Z disk Scheduling = deciding which hypervisor to use for each VM. Difficulty: easy! .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- <!-- Warning, two almost identical slides (for img effect) --> ## Exercise 2 - You have: - 1000+ hypervisors (and counting!) - Each server has different resources: - 8-500 GB of RAM, 4-64 cores, 1-100 TB disk - Multiple times a day, a different team asks for: - up to 50 VMs with different characteristics Scheduling = deciding which hypervisor to use for each VM. Difficulty: ??? .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- <!-- Warning, two almost identical slides (for img effect) --> ## Exercise 2 - You have: - 1000+ hypervisors (and counting!) - Each server has different resources: - 8-500 GB of RAM, 4-64 cores, 1-100 TB disk - Multiple times a day, a different team asks for: - up to 50 VMs with different characteristics Scheduling = deciding which hypervisor to use for each VM.  .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Exercise 3 - You have machines (physical and/or virtual) - You have containers - You are trying to put the containers on the machines - Sounds familiar? .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## Scheduling with one resource .center[] ## We can't fit a job of size 6 :( .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## Scheduling with one resource .center[] ## ... Now we can! .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## Scheduling with two resources .center[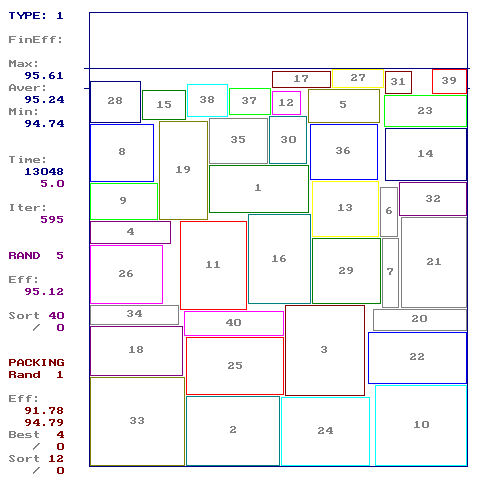] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## Scheduling with three resources .center[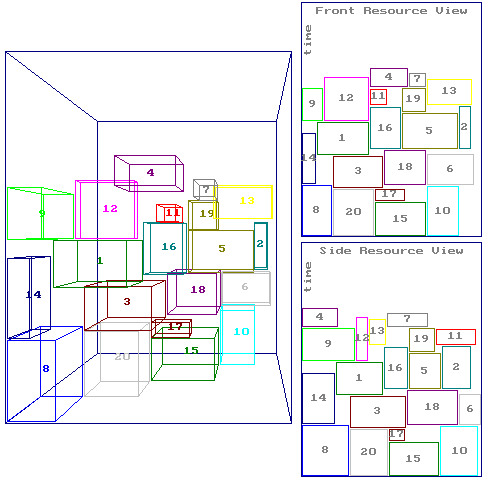] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## You need to be good at this .center[] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## But also, you must be quick! .center[] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## And be web scale! .center[] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## And think outside (?) of the box! .center[] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: pic ## Good luck! .center[] .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## TL,DR * Scheduling with multiple resources (dimensions) is hard. * Don't expect to solve the problem with a Tiny Shell Script. * There are literally tons of research papers written on this. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## But our orchestrator also needs to manage ... * Network connectivity (or filtering) between containers. * Load balancing (external and internal). * Failure recovery (if a node or a whole datacenter fails). * Rolling out new versions of our applications. (Canary deployments, blue/green deployments...) .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Some orchestrators We are going to present briefly a few orchestrators. There is no "absolute best" orchestrator. It depends on: - your applications, - your requirements, - your pre-existing skills... .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Nomad - Open Source project by Hashicorp. - Arbitrary scheduler (not just for containers). - Great if you want to schedule mixed workloads. (VMs, containers, processes...) - Less integration with the rest of the container ecosystem. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Mesos - Open Source project in the Apache Foundation. - Arbitrary scheduler (not just for containers). - Two-level scheduler. - Top-level scheduler acts as a resource broker. - Second-level schedulers (aka "frameworks") obtain resources from top-level. - Frameworks implement various strategies. (Marathon = long running processes; Chronos = run at intervals; ...) - Commercial offering through DC/OS by Mesosphere. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Rancher - Rancher 1 offered a simple interface for Docker hosts. - Rancher 2 is a complete management platform for Docker and Kubernetes. - Technically not an orchestrator, but it's a popular option. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Swarm - Tightly integrated with the Docker Engine. - Extremely simple to deploy and setup, even in multi-manager (HA) mode. - Secure by default. - Strongly opinionated: - smaller set of features, - easier to operate. .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- ## Kubernetes - Open Source project initiated by Google. - Contributions from many other actors. - *De facto* standard for container orchestration. - Many deployment options; some of them very complex. - Reputation: steep learning curve. - Reality: - true, if we try to understand *everything*; - false, if we focus on what matters. ??? :EN:- Orchestration overview :FR:- Survol de techniques d'orchestration .debug[[containers/Orchestration_Overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/Orchestration_Overview.md)] --- class: title, self-paced Thank you! .debug[[shared/thankyou.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/thankyou.md)] --- class: title, in-person That's all, folks! <br/> Questions?  .debug[[shared/thankyou.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/thankyou.md)] --- class: pic .interstitial[] --- name: toc-links-and-resources class: title Links and resources .nav[ [Previous part](#toc-orchestration-an-overview) | [Back to table of contents](#toc-part-9) | [Next part](#toc-) ] .debug[(automatically generated title slide)] --- # Links and resources - [Docker Community Slack](https://community.docker.com/registrations/groups/4316) - [Docker Community Forums](https://forums.docker.com/) - [Docker Hub](https://hub.docker.com) - [Docker Blog](https://blog.docker.com/) - [Docker documentation](https://docs.docker.com/) - [Docker on StackOverflow](https://stackoverflow.com/questions/tagged/docker) - [Docker on Twitter](https://twitter.com/docker) .footnote[These slides (and future updates) are on → https://container.training/] .debug[[containers/links.md](https://github.com/jpetazzo/container.training/tree/main/slides/containers/links.md)]