⏳️ Loading...
class: title, self-paced Kubernetes 101<br/> .nav[*Self-paced version*] .debug[ ``` ``` These slides have been built from commit: 065e0fe [shared/title.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/title.md)] --- class: title, in-person Kubernetes 101<br/><br/></br> .footnote[ **Slides[:](https://www.youtube.com/watch?v=h16zyxiwDLY) https://container.training/** ] <!-- WiFi: **Something**<br/> Password: **Something** **Be kind to the WiFi!**<br/> *Use the 5G network.* *Don't use your hotspot.*<br/> *Don't stream videos or download big files during the workshop*<br/> *Thank you!* --> .debug[[shared/title.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/title.md)] --- ## Introductions ⚠️ This slide should be customized by the tutorial instructor(s). <!-- - Hello! We are: - 👷🏻♀️ AJ ([@s0ulshake], [EphemeraSearch], [Quantgene]) - 🚁 Alexandre ([@alexbuisine], Enix SAS) - 🐳 Jérôme ([@jpetazzo], [@jpetazzo@hachyderm.io], Ardan Labs) - 🐳 Jérôme ([@jpetazzo], [@jpetazzo@hachyderm.io], Enix SAS) - 🐳 Jérôme ([@jpetazzo], [@jpetazzo@hachyderm.io], Tiny Shell Script LLC) --> <!-- - The training will run for 4 hours, with a 10 minutes break every hour (the middle break will be a bit longer) --> <!-- - The workshop will run from XXX to YYY - There will be a lunch break at ZZZ (And coffee breaks!) --> <!-- - Feel free to interrupt for questions at any time - *Especially when you see full screen container pictures!* - Live feedback, questions, help: In person! --> <!-- - You ~~should~~ must ask questions! Lots of questions! (especially when you see full screen container pictures) - Use In person! to ask questions, get help, etc. --> <!-- --> [@alexbuisine]: https://twitter.com/alexbuisine [EphemeraSearch]: https://ephemerasearch.com/ [@jpetazzo]: https://twitter.com/jpetazzo [@jpetazzo@hachyderm.io]: https://hachyderm.io/@jpetazzo [@s0ulshake]: https://twitter.com/s0ulshake [Quantgene]: https://www.quantgene.com/ .debug[[logistics.md](https://github.com/jpetazzo/container.training/tree/main/slides/logistics.md)] --- ## Exercises - At the end of each day, there is a series of exercises - To make the most out of the training, please try the exercises! (it will help to practice and memorize the content of the day) - We recommend to take at least one hour to work on the exercises (if you understood the content of the day, it will be much faster) - Each day will start with a quick review of the exercises of the previous day .debug[[logistics.md](https://github.com/jpetazzo/container.training/tree/main/slides/logistics.md)] --- ## Chat room - We've set up a chat room that we will monitor during the workshop - Don't hesitate to use it to ask questions, or get help, or share feedback - The chat room will also be available after the workshop - Join the chat room: In person! - Say hi in the chat room! .debug[[shared/chat-room-im.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/chat-room-im.md)] --- ## Accessing these slides now - We recommend that you open these slides in your browser: https://container.training/ - This is a public URL, you're welcome to share it with others! - Use arrows to move to next/previous slide (up, down, left, right, page up, page down) - Type a slide number + ENTER to go to that slide - The slide number is also visible in the URL bar (e.g. .../#123 for slide 123) .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## These slides are open source - The sources of these slides are available in a public GitHub repository: https://github.com/jpetazzo/container.training - These slides are written in Markdown - You are welcome to share, re-use, re-mix these slides - Typos? Mistakes? Questions? Feel free to hover over the bottom of the slide ... .footnote[👇 Try it! The source file will be shown and you can view it on GitHub and fork and edit it.] <!-- .lab[ ```open https://github.com/jpetazzo/container.training/tree/master/slides/common/about-slides.md``` ] --> .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## Accessing these slides later - Slides will remain online so you can review them later if needed (let's say we'll keep them online at least 1 year, how about that?) - You can download the slides using this URL: https://container.training/slides.zip (then open the file `kube-halfday.yml.html`) - You can also generate a PDF of the slides (by printing them to a file; but be patient with your browser!) .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## These slides are constantly updated - They are maintained by [Jérôme Petazzoni](https://hachyderm.io/@jpetazzo/) and [multiple contributors](https://github.com/jpetazzo/container.training/graphs/contributors) - Feel free to check the GitHub repository for updates: https://github.com/jpetazzo/container.training - Look for branches named YYYY-MM-... - You can also find specific decks and other resources on: https://container.training/ .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- class: extra-details ## Extra details - This slide has a little magnifying glass in the top left corner - This magnifying glass indicates slides that provide extra details - Feel free to skip them if: - you are in a hurry - you are new to this and want to avoid cognitive overload - you want only the most essential information - You can review these slides another time if you want, they'll be waiting for you ☺ .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## Slides ≠ documentation - We tried to include a lot of information in these slides - But they don't replace or compete with the documentation! - Treat these slides as yet another pillar to support your learning experience - Don't hesitate to frequently read the documentations ([Docker documentation][docker-docs], [Kubernetes documentation][k8s-docs]) - And online communities (e.g.: [Docker forums][docker-forums], [Docker on StackOverflow][docker-so], [Kubernetes on StackOverflow][k8s-so]) [docker-docs]: https://docs.docker.com/ [k8s-docs]: https://kubernetes.io/docs/ [docker-forums]: https://forums.docker.com/ [docker-so]: http://stackoverflow.com/questions/tagged/docker [k8s-so]: http://stackoverflow.com/questions/tagged/kubernetes .debug[[shared/about-slides.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/about-slides.md)] --- ## Pre-requirements - Be comfortable with the UNIX command line - navigating directories - editing files - a little bit of bash-fu (environment variables, loops) - Hands-on experience working with containers - building images, running them; doesn't matter how exactly - if you know `docker run`, `docker build`, `docker ps`, you're good to go! - It's totally OK if you are not a Docker expert! .debug[[k8s/prereqs-basic.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/prereqs-basic.md)] --- class: title *Tell me and I forget.* <br/> *Teach me and I remember.* <br/> *Involve me and I learn.* Misattributed to Benjamin Franklin [(Probably inspired by Chinese Confucian philosopher Xunzi)](https://www.barrypopik.com/index.php/new_york_city/entry/tell_me_and_i_forget_teach_me_and_i_may_remember_involve_me_and_i_will_lear/) .debug[[shared/handson.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/handson.md)] --- ## Hands-on, you shall practice - Nobody ever became a Jedi by spending their lives reading Wookiepedia - Someone can: - read all the docs - watch all the videos - attend all the workshops and live classes - ...This won't be enough to become an expert! - We think one needs to *put the concepts in practice* to truly memorize them - But, how? .debug[[shared/handson.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/handson.md)] --- ## Hands-on labs - These slides include *tons* of demos, examples, and exercises - Don't follow along passively; try to reproduce the demos and examples! - Each time you see a gray rectangle like this, it indicates a demo or example .lab[ - This is a command that we're gonna run: ```bash echo hello world ``` ] - Don't hesitate to try them in your environment - Don't hesitate to improvise, deviate from the script... And see what happens! .debug[[shared/handson.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/handson.md)] --- ## Where are we going to run our containers? .debug[[k8s/labs-live.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-live.md)] --- class: pic  .debug[[k8s/labs-live.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-live.md)] --- ## If you're attending a live class - Each person gets a private lab environment (depending on the scenario, this will be one VM, one cluster, multiple clusters...) - The instructor will tell you how to connect to your environment - Your lab environments will be available for the duration of the workshop (check with your instructor to know exactly when they'll be shutdown) .debug[[k8s/labs-live.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-live.md)] --- ## Why don't we run containers locally? - Setting up a local Kubernetes cluster can take time (and the procedure can differ from one system to another) - On some systems, it might be impossible (due to restrictive IT policies, lack of hardware support...) - Some labs require a "real" cluster (e.g. multiple nodes to demonstrate failover, placement policies...) - For on-site classes, it can stress the local network *"The whole team downloaded all these container images from the WiFi! <br/>... and it went great!"* (Literally no-one ever) .debug[[k8s/labs-live.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-live.md)] --- ## Connecting to our lab environment - We need an SSH client - On Linux, OS X, FreeBSD... you are probably all set; just use `ssh` - On Windows, get one of these: - [putty](https://putty.software/) - Microsoft [Win32 OpenSSH](https://github.com/PowerShell/Win32-OpenSSH/wiki/Install-Win32-OpenSSH) - [Git BASH](https://git-for-windows.github.io/) - [MobaXterm](http://mobaxterm.mobatek.net/) - On Android, [JuiceSSH](https://juicessh.com/) ([Play Store](https://play.google.com/store/apps/details?id=com.sonelli.juicessh)) works pretty well .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Testing the connection - Your instructor will tell you where to find the IP address, login, and password .lab[ - Connect to your lab environment with your SSH client: ```bash ssh `user`@`A.B.C.D` ssh -p `32323` `user`@`A.B.C.D` ``` (Make sure to replace the highlighted values with the ones provided to you!) <!-- ```bash for N in $(awk '/\Wnode/{print $2}' /etc/hosts); do ssh -o StrictHostKeyChecking=no $N true done ``` ```bash ### FIXME find a way to reset the cluster, maybe? ``` --> ] You should see a prompt looking like this: ``` [A.B.C.D] (...) user@machine ~ $ ``` .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Checking the lab environment In Docker classes, run `docker version`. The output should look like this: .small[ ```bash Client: Version: 29.1.1 API version: 1.52 Go version: go1.25.4 X:nodwarf5 Git commit: 0aedba58c2 Built: Fri Nov 28 14:28:26 2025 OS/Arch: linux/amd64 Context: default Server: Engine: Version: 29.1.1 API version: 1.52 (minimum version 1.44) Go version: go1.25.4 X:nodwarf5 Git commit: 9a84135d52 Built: Fri Nov 28 14:28:26 2025 OS/Arch: linux/amd64 Experimental: false ... ``` ] .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Checking the lab environment In Kubernetes classes, run `kubectl get nodes`. The output should look like this: ```bash $ k get nodes NAME STATUS ROLES AGE VERSION node1 Ready control-plane 7d6h v1.34.0 node2 Ready <none> 7d6h v1.34.0 node3 Ready <none> 7d6h v1.34.0 node4 Ready <none> 7d6h v1.34.0 ``` .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## If it doesn't work... Ask an instructor or assistant to help you! .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## `tailhist` - The shell history of the instructor is available online in real time - The instructor will share a special URL with you (typically, the instructor's lab address on port 1088 or 30088) - Open that URL in your browser and you should see the history - The history is updated in real time (using a WebSocket connection) - It should be green when the WebSocket is connected (if it turns red, reloading the page should fix it) .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Terminals Once in a while, the instructions will say: <br/>"Open a new terminal." There are multiple ways to do this: - create a new window or tab on your machine, and SSH into the VM; - use screen or tmux on the VM and open a new window from there. You are welcome to use the method that you feel the most comfortable with. .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Tmux cheat sheet (basic) [Tmux](https://en.wikipedia.org/wiki/Tmux) is a terminal multiplexer like `screen`. *You don't have to use it or even know about it to follow along. <br/> But some of us like to use it to switch between terminals. <br/> It has been preinstalled on your workshop nodes.* - You can start a new session with `tmux` <br/> (or resume or share an existing session with `tmux attach`) - Then use these keyboard shortcuts: - Ctrl-b c → creates a new window - Ctrl-b n → go to next window - Ctrl-b p → go to previous window - Ctrl-b " → split window top/bottom - Ctrl-b % → split window left/right - Ctrl-b arrows → navigate within split windows .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Tmux cheat sheet (advanced) - Ctrl-b d → detach session <br/> (resume it later with `tmux attach`) - Ctrl-b Alt-1 → rearrange windows in columns - Ctrl-b Alt-2 → rearrange windows in rows - Ctrl-b , → rename window - Ctrl-b Ctrl-o → cycle pane position (e.g. switch top/bottom) - Ctrl-b PageUp → enter scrollback mode <br/> (use PageUp/PageDown to scroll; Ctrl-c or Enter to exit scrollback) .debug[[shared/connecting.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/connecting.md)] --- ## Running your own lab environments - To practice outside of live classes, you will need your own cluster - We'll give you 4 possibilities, depending on your goals: - level 0 (no installation required) - level 1 (local development cluster) - level 2 (cluster with multiple nodes) - level 3 ("real" cluster with all the bells and whistles) .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## Level 0 - Use a free, cloud-based, environment - Pros: free, and nothing to install locally - Cons: lots of limitations - requires online access - resources (CPU, RAM, disk) are limited - provides a single-node cluster - by default, only available through the online IDE <br/>(extra steps required to use local tools and IDE) - networking stack is different from a normal cluster - cluster might be automatically destroyed once in a while .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## When is it a good match? - Great for your first steps with Kubernetes - Convenient for "bite-sized" learning (a few minutes at a time without spending time on installs and setup) - Not-so-great beyond your first steps - We recommend to "level up" to a local cluster ASAP! .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## How to obtain it - We prepared a "Dev container configuration" (that you can use with GitHub Codespaces) - This requires a GitHub account (no credit card or personal information is needed, though) - Option 1: [follow that link][codespaces] - Option 2: go to [this repo][repo], click on `<> Code v` and `Create codespace on main` .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## Level 1 - Install a local Kubernetes dev cluster - Pros: free, can work with local tools - Cons: - usually, you get a one-node cluster <br/>(but some tools let you create multiple nodes) - resources can be limited <br/>(depends on how much CPU/RAM you have on your machine) - cluster is on a private network <br/>(not great for labs involving load balancers, ingress controllers...) - support for persistent volumes might be limited <br/>(or non-existent) .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## When is it a good match? - Ideal for most classes and labs (from basic to advanced) - Notable exceptions: - when you need multiple "real" nodes <br/>(e.g. resource scheduling, cluster autoscaling...) - when you want to expose things to the outside world <br/>(e.g. ingress, gateway API, cert-manager...) - Very easy to reset the environment to a clean slate - Great way to prepare a lab or demo before executing it on a "real" cluster .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## How to obtain it - There are many options available to run local Kubernetes clusters! - If you already have Docker up and running: *check [KinD] or [k3d]* - Otherwise: *check [Docker Desktop][docker-desktop] or [Rancher Desktop][rancher-desktop]* - There are also other options; this is just a shortlist! [KinD]: https://kind.sigs.k8s.io/ [k3d]:https://k3d.io/ [docker-desktop]: https://docs.docker.com/desktop/use-desktop/kubernetes/ [rancher-desktop]: https://docs.rancherdesktop.io/ui/preferences/kubernetes/ .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## Level 2 - Install a Kubernetes cluster on a few machines (physical machines, virtual machines, cloud, on-premises...) - Pros: - very flexible; works almost anywhere (cloud VMs, home lab...) - can even run "real" applications (serving real traffic) - Cons: - typically costs some money (hardware investment or cloud costs) - still missing a few things compared to a "real" cluster <br/>(cloud controller manager, storage class, control plane high availability...) .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## When is it a good match? - If you already have a "home lab" or a lab at work (because the machines already exist) - If you want more visibility and/or control: - enable alpha/experimental options and features - start, stop, view logs... of individual components - If you want multiple nodes to experiment with scheduling, autoscaling... - To host applications that remain available when your laptop is offline :) .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## How to obtain it - Option 1: *provision a few machines; [install `kubeadm`][kubeadm]; use `kubeadm` to install cluster* - Option 2: *use [`labctl`][labctl] to automate the previous steps* *(labctl supports [10+ public and private cloud platforms][labctl-vms])* - Option 3: *use the Kubernetes distro of your choice!* .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## Level 3 - Use a managed Kubernetes cluster - Pros: - it's the real deal! - Cons: - recurring cloud costs .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## When is it a good match? - If you want a highly-available cluster and control plane - To have all the cloud features (`LoadBalancer` services, `StorageClass` for stateful apps, cluster autoscaling...) - To host your first production stacks .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## How to obtain it - Option 1: *use the CLI / Web UI / Terraform... for your cloud provider* - Option 2: *use [`labctl`][labctl] to provision a cluster with Terraform/OpenTofu* .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## What's `labctl`? - `labctl` is the tool that we use to provision virtual machines and clusters for live classes - It can create and configure hundreds of VMs and clusters in a few minutes - It supports 10+ cloud providers - It's very useful if you need to provision many clusters (e.g. to run your own workshop with your team!) - It can also be used to provision a single cluster quickly (for testing or educational purposes) - Its Terraform configurations can also be useful on their own (e.g. as a base when building your own infra-as-code) .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- ## Our Kubernetes toolbox - We're going to use a lot of different tools (kubectl, stern, helm, k9s, krew, and many more) - We suggest that you install them progressively (when we introduce them, if you think they'll be useful to you!) - We have also prepared a container image: [jpetazzo/shpod] - `shpod` contains 30+ Docker and Kubernetes tools (along with shell customizations like prompt, completion...) - You can use it to work with your Kubernetes clusters - It can also be used as an SSH server if needed [codespaces]: https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=37004081&skip_quickstart=true [repo]: https://github.com/jpetazzo/container.training [kubeadm]: https://kubernetes.io/docs/reference/setup-tools/kubeadm/ [labctl]: https://github.com/jpetazzo/container.training/tree/main/prepare-labs [labctl-vms]: https://github.com/jpetazzo/container.training/tree/main/prepare-labs/terraform/virtual-machines [jpetazzo/shpod]: https://github.com/jpetazzo/shpod .debug[[k8s/labs-async.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/labs-async.md)] --- name: toc-part-1 ## Part 1 - [Our sample application](#toc-our-sample-application) - [Kubernetes concepts](#toc-kubernetes-concepts) - [Declarative vs imperative](#toc-declarative-vs-imperative) - [First contact with `kubectl`](#toc-first-contact-with-kubectl) - [Setting up Kubernetes](#toc-setting-up-kubernetes) .debug[(auto-generated TOC)] --- name: toc-part-2 ## Part 2 - [Running our first containers on Kubernetes](#toc-running-our-first-containers-on-kubernetes) - [Revisiting `kubectl logs`](#toc-revisiting-kubectl-logs) - [Exposing containers](#toc-exposing-containers) - [Shipping images with a registry](#toc-shipping-images-with-a-registry) - [Running our application on Kubernetes](#toc-running-our-application-on-kubernetes) .debug[(auto-generated TOC)] --- name: toc-part-3 ## Part 3 - [The Kubernetes dashboard](#toc-the-kubernetes-dashboard) - [Security implications of `kubectl apply`](#toc-security-implications-of-kubectl-apply) - [Scaling our demo app](#toc-scaling-our-demo-app) - [Daemon sets](#toc-daemon-sets) - [Labels and selectors](#toc-labels-and-selectors) - [Rolling updates](#toc-rolling-updates) .debug[(auto-generated TOC)] --- name: toc-part-4 ## Part 4 - [Accessing logs from the CLI](#toc-accessing-logs-from-the-cli) - [Namespaces](#toc-namespaces) - [Managing stacks with Helm](#toc-managing-stacks-with-helm) - [Creating a basic chart](#toc-creating-a-basic-chart) - [Next steps](#toc-next-steps) - [Links and resources](#toc-links-and-resources) .debug[(auto-generated TOC)] .debug[[shared/toc.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/toc.md)] --- class: pic .interstitial[] --- name: toc-our-sample-application class: title Our sample application .nav[ [Previous part](#toc-) | [Back to table of contents](#toc-part-1) | [Next part](#toc-kubernetes-concepts) ] .debug[(automatically generated title slide)] --- # Our sample application - We will clone the GitHub repository onto our `node1` - The repository also contains scripts and tools that we will use through the workshop .lab[ <!-- ```bash cd ~ if [ -d container.training ]; then mv container.training container.training.$RANDOM fi ``` --> - Clone the repository on `node1`: ```bash git clone https://github.com/jpetazzo/container.training ``` ] (You can also fork the repository on GitHub and clone your fork if you prefer that.) .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Downloading and running the application Let's start this before we look around, as downloading will take a little time... .lab[ - Go to the `dockercoins` directory, in the cloned repository: ```bash cd ~/container.training/dockercoins ``` - Use Compose to build and run all containers: ```bash docker-compose up ``` <!-- ```longwait units of work done``` --> ] Compose tells Docker to build all container images (pulling the corresponding base images), then starts all containers, and displays aggregated logs. .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## What's this application? -- - It is a DockerCoin miner! 💰🐳📦🚢 -- - No, you can't buy coffee with DockerCoin -- - How dockercoins works: - generate a few random bytes - hash these bytes - increment a counter (to keep track of speed) - repeat forever! -- - DockerCoin is *not* a cryptocurrency (the only common points are "randomness," "hashing," and "coins" in the name) .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## DockerCoin in the microservices era - The dockercoins app is made of 5 services: - `rng` = web service generating random bytes - `hasher` = web service computing hash of POSTed data - `worker` = background process calling `rng` and `hasher` - `webui` = web interface to watch progress - `redis` = data store (holds a counter updated by `worker`) - These 5 services are visible in the application's Compose file, [docker-compose.yml]( https://github.com/jpetazzo/container.training/blob/master/dockercoins/docker-compose.yml) .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## How dockercoins works - `worker` invokes web service `rng` to generate random bytes - `worker` invokes web service `hasher` to hash these bytes - `worker` does this in an infinite loop - every second, `worker` updates `redis` to indicate how many loops were done - `webui` queries `redis`, and computes and exposes "hashing speed" in our browser *(See diagram on next slide!)* .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- class: pic 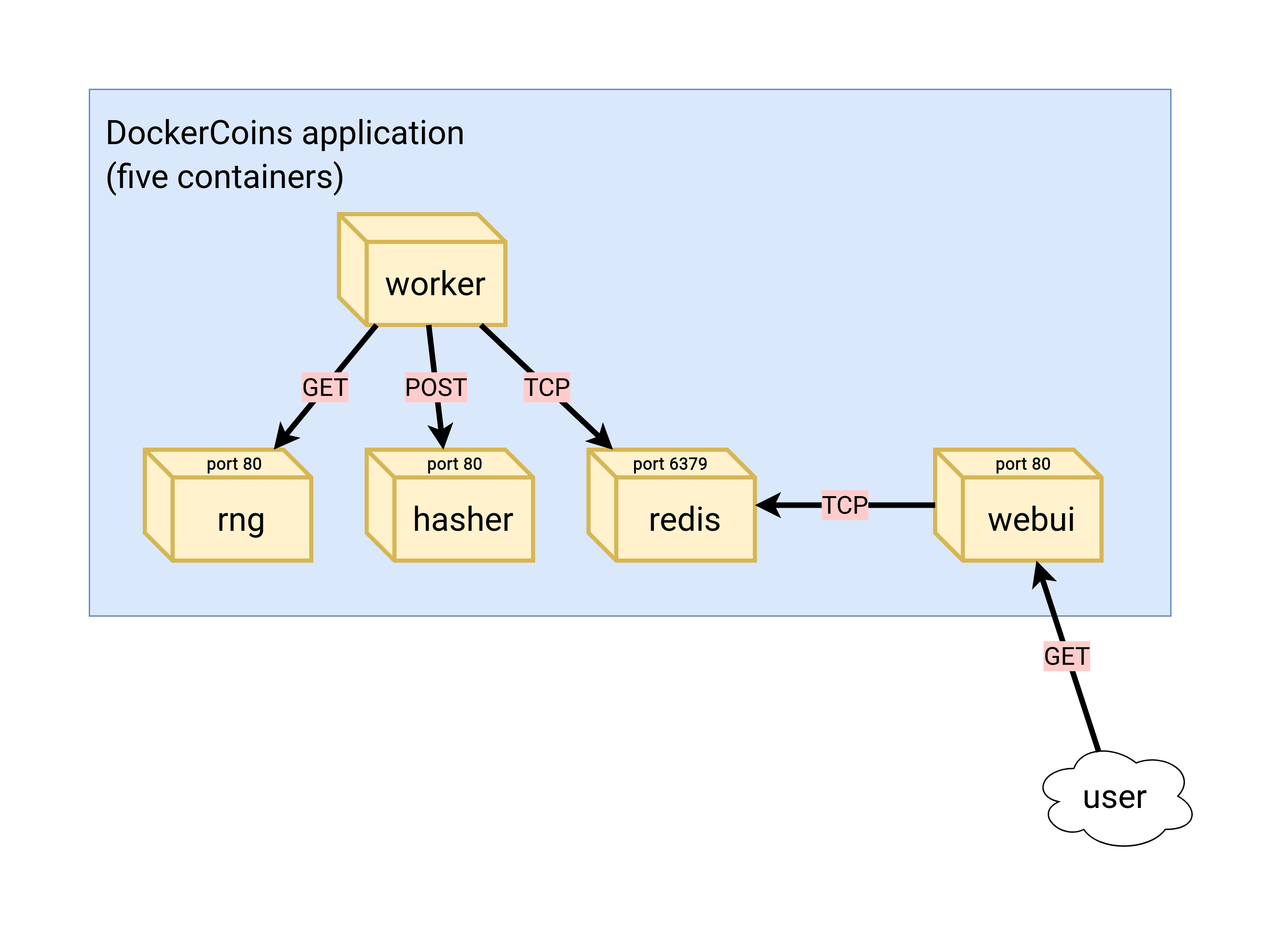 .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Service discovery in container-land How does each service find out the address of the other ones? -- - We do not hard-code IP addresses in the code - We do not hard-code FQDNs in the code, either - We just connect to a service name, and container-magic does the rest (And by container-magic, we mean "a crafty, dynamic, embedded DNS server") .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Example in `worker/worker.py` ```python redis = Redis("`redis`") def get_random_bytes(): r = requests.get("http://`rng`/32") return r.content def hash_bytes(data): r = requests.post("http://`hasher`/", data=data, headers={"Content-Type": "application/octet-stream"}) ``` (Full source code available [here]( https://github.com/jpetazzo/container.training/blob/8279a3bce9398f7c1a53bdd95187c53eda4e6435/dockercoins/worker/worker.py#L17 )) .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- class: extra-details ## Links, naming, and service discovery - Containers can have network aliases (resolvable through DNS) - Compose file version 2+ makes each container reachable through its service name - Compose file version 1 required "links" sections to accomplish this - Network aliases are automatically namespaced - you can have multiple apps declaring and using a service named `database` - containers in the blue app will resolve `database` to the IP of the blue database - containers in the green app will resolve `database` to the IP of the green database .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Show me the code! - You can check the GitHub repository with all the materials of this workshop: <br/>https://github.com/jpetazzo/container.training - The application is in the [dockercoins]( https://github.com/jpetazzo/container.training/tree/master/dockercoins) subdirectory - The Compose file ([docker-compose.yml]( https://github.com/jpetazzo/container.training/blob/master/dockercoins/docker-compose.yml)) lists all 5 services - `redis` is using an official image from the Docker Hub - `hasher`, `rng`, `worker`, `webui` are each built from a Dockerfile - Each service's Dockerfile and source code is in its own directory (`hasher` is in the [hasher](https://github.com/jpetazzo/container.training/blob/master/dockercoins/hasher/) directory, `rng` is in the [rng](https://github.com/jpetazzo/container.training/blob/master/dockercoins/rng/) directory, etc.) .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- class: extra-details ## Compose file format version *This is relevant only if you have used Compose before 2016...* - Compose 1.6 introduced support for a new Compose file format (aka "v2") - Services are no longer at the top level, but under a `services` section - There has to be a `version` key at the top level, with value `"2"` (as a string, not an integer) - Containers are placed on a dedicated network, making links unnecessary - There are other minor differences, but upgrade is easy and straightforward .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Our application at work - On the left-hand side, the "rainbow strip" shows the container names - On the right-hand side, we see the output of our containers - We can see the `worker` service making requests to `rng` and `hasher` - For `rng` and `hasher`, we see HTTP access logs .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Connecting to the web UI - "Logs are exciting and fun!" (No-one, ever) - The `webui` container exposes a web dashboard; let's view it .lab[ - With a web browser, connect to `node1` on port 8000 - Remember: the `nodeX` aliases are valid only on the nodes themselves - In your browser, you need to enter the IP address of your node <!-- ```open http://node1:8000``` --> ] A drawing area should show up, and after a few seconds, a blue graph will appear. .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- class: self-paced, extra-details ## If the graph doesn't load If you just see a `Page not found` error, it might be because your Docker Engine is running on a different machine. This can be the case if: - you are using the Docker Toolbox - you are using a VM (local or remote) created with Docker Machine - you are controlling a remote Docker Engine When you run DockerCoins in development mode, the web UI static files are mapped to the container using a volume. Alas, volumes can only work on a local environment, or when using Docker Desktop for Mac or Windows. How to fix this? Stop the app with `^C`, edit `dockercoins.yml`, comment out the `volumes` section, and try again. .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- class: extra-details ## Why does the speed seem irregular? - It *looks like* the speed is approximately 4 hashes/second - Or more precisely: 4 hashes/second, with regular dips down to zero - Why? -- class: extra-details - The app actually has a constant, steady speed: 3.33 hashes/second <br/> (which corresponds to 1 hash every 0.3 seconds, for *reasons*) - Yes, and? .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- class: extra-details ## The reason why this graph is *not awesome* - The worker doesn't update the counter after every loop, but up to once per second - The speed is computed by the browser, checking the counter about once per second - Between two consecutive updates, the counter will increase either by 4, or by 0 - The perceived speed will therefore be 4 - 4 - 4 - 0 - 4 - 4 - 0 etc. - What can we conclude from this? -- class: extra-details - "I'm clearly incapable of writing good frontend code!" 😀 — Jérôme .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Stopping the application - If we interrupt Compose (with `^C`), it will politely ask the Docker Engine to stop the app - The Docker Engine will send a `TERM` signal to the containers - If the containers do not exit in a timely manner, the Engine sends a `KILL` signal .lab[ - Stop the application by hitting `^C` <!-- ```key ^C``` --> ] -- Some containers exit immediately, others take longer. The containers that do not handle `SIGTERM` end up being killed after a 10s timeout. If we are very impatient, we can hit `^C` a second time! .debug[[shared/sampleapp.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/sampleapp.md)] --- ## Clean up - Before moving on, let's remove those containers .lab[ - Tell Compose to remove everything: ```bash docker-compose down ``` ] .debug[[shared/composedown.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/composedown.md)] --- class: pic .interstitial[] --- name: toc-kubernetes-concepts class: title Kubernetes concepts .nav[ [Previous part](#toc-our-sample-application) | [Back to table of contents](#toc-part-1) | [Next part](#toc-declarative-vs-imperative) ] .debug[(automatically generated title slide)] --- # Kubernetes concepts - Kubernetes is a container management system - It runs and manages containerized applications on a cluster -- - What does that really mean? .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## What can we do with Kubernetes? - Let's imagine that we have a 3-tier e-commerce app: - web frontend - API backend - database - We have built images for our frontend and backend components (e.g. with Dockerfiles and `docker build`) - We are running them successfully with a local environment (e.g. with Docker Compose) - Let's see how we would deploy our app on Kubernetes! .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes, level 1 -- - Leave our database outside of Kubernetes (because database be scary🥺) -- - Deploy a managed Kubernetes cluster (cloud or [professional services][enix-k8s-expert]) -- - Start 5 containers using image `atseashop/api:v1.3` -- - Place an internal load balancer in front of these containers -- - Start 10 containers using image `atseashop/webfront:v1.3` -- - Place a public load balancer in front of these containers -- - It's Black Friday (or Christmas), traffic spikes, grow our cluster and add containers -- - New release! Replace my containers with the new image `atseashop/webfront:v1.4` -- - Keep processing requests during the upgrade; update my containers one at a time [enix-k8s-expert]: https://enix.io/en/kubernetes-expert/ .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes, level 2 - Deploy a pre-production environment (still using our external database, for now) - Resource management and scheduling (reserve CPU/RAM for containers; placement constraints; priorities) - Autoscaling (straightforward on CPU; more complex on other metrics) - Advanced rollout patterns (blue/green deployment, canary deployment) -- .footnote[ On the next page: canary cage with an oxygen bottle, designed to keep the canary alive. <br/> (See https://post.lurk.org/@zilog/109632335293371919 for details.) ] .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes, level 3 - Run staging databases on the cluster (no replication, no backups, no scaling) - Automatic or semi-automatic deployment of feature branches (each with its own database) - Fine-grained access control (defining *what* can be done by *whom* on *which* resources) - Batch jobs (one-off; parallel; also cron-style periodic execution) - Package applications with e.g. Helm charts .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes, level 4 - Stateful services with persistence, replication, backups (databases, message queues, etc.) - Automate complex tasks with *operators* (e.g. database replication, failover, etc.) - Combine the two previous points with database operators like [CloudNativePG][cnpg] (learn more about database operators: [FR][pirates-video-fr], [EN][pirates-video-en]) - Leverage advanced storage with e.g. local ZFS volumes (learn more about ZFS and databases on k8s: [FR][zfs-video-fr], [EN][zfs-video-en]) - Deploy and manage clusters in-house [cnpg]: https://cloudnative-pg.io/ [pirates-video-fr]: https://www.youtube.com/watch?v=d_ka7PlWo1I [pirates-video-en]: https://www.youtube.com/watch?v=ojUdBjbiKWk&t=5s [zfs-video-fr]: https://www.youtube.com/watch?v=XN9YL93f8tI [zfs-video-en]: https://www.youtube.com/watch?v=3sJIYiDnod4 .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes, level 5 - Deploying and managing clusters at scale (hundreds of clusters, thousands of nodes...) - Writing custom operators - Hybrid deployments .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Disclaimer The levels mentioned in the previous slides are not necessarily linear. They aren't exhaustive either (we didn't mention e.g. observability and alerting). .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes architecture .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes architecture - Ha ha ha ha - OK, I was trying to scare you, it's much simpler than that ❤️ .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Credits - The first schema is a Kubernetes cluster with storage backed by multi-path iSCSI (Courtesy of [Yongbok Kim](https://www.yongbok.net/blog/)) - The second one is a simplified representation of a Kubernetes cluster (Courtesy of [Imesh Gunaratne](https://medium.com/containermind/a-reference-architecture-for-deploying-wso2-middleware-on-kubernetes-d4dee7601e8e)) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes architecture: the nodes - The nodes executing our containers run a collection of services: - a container Engine (typically Docker) - kubelet (the "node agent") - kube-proxy (a necessary but not sufficient network component) - Nodes were formerly called "minions" (You might see that word in older articles or documentation) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Kubernetes architecture: the control plane - The Kubernetes logic (its "brains") is a collection of services: - the API server (our point of entry to everything!) - core services like the scheduler and controller manager - `etcd` (a highly available key/value store; the "database" of Kubernetes) - Together, these services form the control plane of our cluster - The control plane is also called the "master" .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## Running the control plane on special nodes - It is common to reserve a dedicated node for the control plane (Except for single-node development clusters, like when using minikube) - This node is then called a "master" (Yes, this is ambiguous: is the "master" a node, or the whole control plane?) - Normal applications are restricted from running on this node (By using a mechanism called ["taints"](https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/)) - When high availability is required, each service of the control plane must be resilient - The control plane is then replicated on multiple nodes (This is sometimes called a "multi-master" setup) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## Running the control plane outside containers - The services of the control plane can run in or out of containers - For instance: since `etcd` is a critical service, some people deploy it directly on a dedicated cluster (without containers) (This is illustrated on the first "super complicated" schema) - In some hosted Kubernetes offerings (e.g. AKS, GKE, EKS), the control plane is invisible (We only "see" a Kubernetes API endpoint) - In that case, there is no "master node" *For this reason, it is more accurate to say "control plane" rather than "master."* .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## How many nodes should a cluster have? - There is no particular constraint (no need to have an odd number of nodes for quorum) - A cluster can have zero node (but then it won't be able to start any pods) - For testing and development, having a single node is fine - For production, make sure that you have extra capacity (so that your workload still fits if you lose a node or a group of nodes) - Kubernetes is tested with [up to 5000 nodes](https://kubernetes.io/docs/setup/best-practices/cluster-large/) (however, running a cluster of that size requires a lot of tuning) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## Do we need to run Docker at all? No! -- - The Docker Engine used to be the default option to run containers with Kubernetes - Support for Docker (specifically: dockershim) was removed in Kubernetes 1.24 - We can leverage other pluggable runtimes through the *Container Runtime Interface* - <del>We could also use `rkt` ("Rocket") from CoreOS</del> (deprecated) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## Some runtimes available through CRI - [containerd](https://github.com/containerd/containerd/blob/master/README.md) - maintained by Docker, IBM, and community - used by Docker Engine, microk8s, k3s, GKE; also standalone - comes with its own CLI, `ctr` - [CRI-O](https://github.com/cri-o/cri-o/blob/master/README.md): - maintained by Red Hat, SUSE, and community - used by OpenShift and Kubic - designed specifically as a minimal runtime for Kubernetes - [And more](https://kubernetes.io/docs/setup/production-environment/container-runtimes/) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## Do we need to run Docker at all? Yes! -- - In this workshop, we run our app on a single node first - We will need to build images and ship them around - We can do these things without Docker <br/> (but with some languages/frameworks, it might be much harder) - Docker is still the most stable container engine today <br/> (but other options are maturing very quickly) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: extra-details ## Do we need to run Docker at all? - On our Kubernetes clusters: *Not anymore* - On our development environments, CI pipelines ... : *Yes, almost certainly* .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Interacting with Kubernetes - We will interact with our Kubernetes cluster through the Kubernetes API - The Kubernetes API is (mostly) RESTful - It allows us to create, read, update, delete *resources* - A few common resource types are: - node (a machine — physical or virtual — in our cluster) - pod (group of containers running together on a node) - service (stable network endpoint to connect to one or multiple containers) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic  .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Scaling - How would we scale the pod shown on the previous slide? - **Do** create additional pods - each pod can be on a different node - each pod will have its own IP address - **Do not** add more NGINX containers in the pod - all the NGINX containers would be on the same node - they would all have the same IP address <br/>(resulting in `Address already in use` errors) .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Together or separate - Should we put e.g. a web application server and a cache together? <br/> ("cache" being something like e.g. Memcached or Redis) - Putting them **in the same pod** means: - they have to be scaled together - they can communicate very efficiently over `localhost` - Putting them **in different pods** means: - they can be scaled separately - they must communicate over remote IP addresses <br/>(incurring more latency, lower performance) - Both scenarios can make sense, depending on our goals .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- ## Credits - The first diagram is courtesy of Lucas Käldström, in [this presentation](https://speakerdeck.com/luxas/kubeadm-cluster-creation-internals-from-self-hosting-to-upgradability-and-ha) - it's one of the best Kubernetes architecture diagrams available! - The second diagram is courtesy of Weave Works - a *pod* can have multiple containers working together - IP addresses are associated with *pods*, not with individual containers Both diagrams used with permission. ??? :EN:- Kubernetes concepts :FR:- Kubernetes en théorie .debug[[k8s/concepts-k8s.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/concepts-k8s.md)] --- class: pic .interstitial[] --- name: toc-declarative-vs-imperative class: title Declarative vs imperative .nav[ [Previous part](#toc-kubernetes-concepts) | [Back to table of contents](#toc-part-1) | [Next part](#toc-first-contact-with-kubectl) ] .debug[(automatically generated title slide)] --- # Declarative vs imperative - Our container orchestrator puts a very strong emphasis on being *declarative* - Declarative: *I would like a cup of tea.* - Imperative: *Boil some water. Pour it in a teapot. Add tea leaves. Steep for a while. Serve in a cup.* -- - Declarative seems simpler at first ... -- - ... As long as you know how to brew tea .debug[[shared/declarative.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/declarative.md)] --- ## Declarative vs imperative - What declarative would really be: *I want a cup of tea, obtained by pouring an infusion¹ of tea leaves in a cup.* -- *¹An infusion is obtained by letting the object steep a few minutes in hot² water.* -- *²Hot liquid is obtained by pouring it in an appropriate container³ and setting it on a stove.* -- *³Ah, finally, containers! Something we know about. Let's get to work, shall we?* -- .footnote[Did you know there was an [ISO standard](https://en.wikipedia.org/wiki/ISO_3103) specifying how to brew tea?] .debug[[shared/declarative.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/declarative.md)] --- ## Declarative vs imperative - Imperative systems: - simpler - if a task is interrupted, we have to restart from scratch - Declarative systems: - if a task is interrupted (or if we show up to the party half-way through), we can figure out what's missing and do only what's necessary - we need to be able to *observe* the system - ... and compute a "diff" between *what we have* and *what we want* .debug[[shared/declarative.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/declarative.md)] --- ## Declarative vs imperative in Kubernetes - With Kubernetes, we cannot say: "run this container" - All we can do is write a *spec* and push it to the API server (by creating a resource like e.g. a Pod or a Deployment) - The API server will validate that spec (and reject it if it's invalid) - Then it will store it in etcd - A *controller* will "notice" that spec and act upon it .debug[[k8s/declarative.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/declarative.md)] --- ## Reconciling state - Watch for the `spec` fields in the YAML files later! - The *spec* describes *how we want the thing to be* - Kubernetes will *reconcile* the current state with the spec <br/>(technically, this is done by a number of *controllers*) - When we want to change some resource, we update the *spec* - Kubernetes will then *converge* that resource ??? :EN:- Declarative vs imperative models :FR:- Modèles déclaratifs et impératifs .debug[[k8s/declarative.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/declarative.md)] --- class: pic .interstitial[] --- name: toc-first-contact-with-kubectl class: title First contact with `kubectl` .nav[ [Previous part](#toc-declarative-vs-imperative) | [Back to table of contents](#toc-part-1) | [Next part](#toc-setting-up-kubernetes) ] .debug[(automatically generated title slide)] --- # First contact with `kubectl` - `kubectl` is (almost) the only tool we'll need to talk to Kubernetes - It is a rich CLI tool around the Kubernetes API (Everything you can do with `kubectl`, you can do directly with the API) - On our machines, there is a `~/.kube/config` file with: - the Kubernetes API address - the path to our TLS certificates used to authenticate - You can also use the `--kubeconfig` flag to pass a config file - Or directly `--server`, `--user`, etc. - `kubectl` can be pronounced "Cube C T L", "Cube cuttle", "Cube cuddle"... .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## `kubectl` is the new SSH - We often start managing servers with SSH (installing packages, troubleshooting ...) - At scale, it becomes tedious, repetitive, error-prone - Instead, we use config management, central logging, etc. - In many cases, we still need SSH: - as the underlying access method (e.g. Ansible) - to debug tricky scenarios - to inspect and poke at things .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## The parallel with `kubectl` - We often start managing Kubernetes clusters with `kubectl` (deploying applications, troubleshooting ...) - At scale (with many applications or clusters), it becomes tedious, repetitive, error-prone - Instead, we use automated pipelines, observability tooling, etc. - In many cases, we still need `kubectl`: - to debug tricky scenarios - to inspect and poke at things - The Kubernetes API is always the underlying access method .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## `kubectl get` - Let's look at our `Node` resources with `kubectl get`! .lab[ - Look at the composition of our cluster: ```bash kubectl get node ``` - These commands are equivalent: ```bash kubectl get no kubectl get node kubectl get nodes ``` ] .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Obtaining machine-readable output - `kubectl get` can output JSON, YAML, or be directly formatted .lab[ - Give us more info about the nodes: ```bash kubectl get nodes -o wide ``` - Let's have some YAML: ```bash kubectl get no -o yaml ``` See that `kind: List` at the end? It's the type of our result! ] .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## (Ab)using `kubectl` and `jq` - It's super easy to build custom reports .lab[ - Show the capacity of all our nodes as a stream of JSON objects: ```bash kubectl get nodes -o json | jq ".items[] | {name:.metadata.name} + .status.capacity" ``` ] .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## Exploring types and definitions - We can list all available resource types by running `kubectl api-resources` <br/> (In Kubernetes 1.10 and prior, this command used to be `kubectl get`) - We can view the definition for a resource type with: ```bash kubectl explain type ``` - We can view the definition of a field in a resource, for instance: ```bash kubectl explain node.spec ``` - Or get the full definition of all fields and sub-fields: ```bash kubectl explain node --recursive ``` .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## Introspection vs. documentation - We can access the same information by reading the [API documentation](https://kubernetes.io/docs/reference/#api-reference) - The API documentation is usually easier to read, but: - it won't show custom types (like Custom Resource Definitions) - we need to make sure that we look at the correct version - `kubectl api-resources` and `kubectl explain` perform *introspection* (they communicate with the API server and obtain the exact type definitions) .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Type names - The most common resource names have three forms: - singular (e.g. `node`, `service`, `deployment`) - plural (e.g. `nodes`, `services`, `deployments`) - short (e.g. `no`, `svc`, `deploy`) - Some resources do not have a short name - `Endpoints` only have a plural form (because even a single `Endpoints` resource is actually a list of endpoints) .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Viewing details - We can use `kubectl get -o yaml` to see all available details - However, YAML output is often simultaneously too much and not enough - For instance, `kubectl get node node1 -o yaml` is: - too much information (e.g.: list of images available on this node) - not enough information (e.g.: doesn't show pods running on this node) - difficult to read for a human operator - For a comprehensive overview, we can use `kubectl describe` instead .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## `kubectl describe` - `kubectl describe` needs a resource type and (optionally) a resource name - It is possible to provide a resource name *prefix* (all matching objects will be displayed) - `kubectl describe` will retrieve some extra information about the resource .lab[ - Look at the information available for `node1` with one of the following commands: ```bash kubectl describe node/node1 kubectl describe node node1 ``` ] (We should notice a bunch of control plane pods.) .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Listing running containers - Containers are manipulated through *pods* - A pod is a group of containers: - running together (on the same node) - sharing resources (RAM, CPU; but also network, volumes) .lab[ - List pods on our cluster: ```bash kubectl get pods ``` ] -- *Where are the pods that we saw just a moment earlier?!?* .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Namespaces - Namespaces allow us to segregate resources .lab[ - List the namespaces on our cluster with one of these commands: ```bash kubectl get namespaces kubectl get namespace kubectl get ns ``` ] -- *You know what ... This `kube-system` thing looks suspicious.* *In fact, I'm pretty sure it showed up earlier, when we did:* `kubectl describe node node1` .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Accessing namespaces - By default, `kubectl` uses the `default` namespace - We can see resources in all namespaces with `--all-namespaces` .lab[ - List the pods in all namespaces: ```bash kubectl get pods --all-namespaces ``` - Since Kubernetes 1.14, we can also use `-A` as a shorter version: ```bash kubectl get pods -A ``` ] *Here are our system pods!* .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## What are all these control plane pods? - `etcd` is our etcd server - `kube-apiserver` is the API server - `kube-controller-manager` and `kube-scheduler` are other control plane components - `coredns` provides DNS-based service discovery ([replacing kube-dns as of 1.11](https://kubernetes.io/blog/2018/07/10/coredns-ga-for-kubernetes-cluster-dns/)) - `kube-proxy` is the (per-node) component managing internal service access - `cilium` is the (per-node) component managing the network overlay - the `READY` column indicates the number of containers in each pod (which will often be 1 for most pods!) .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Scoping another namespace - We can also look at a different namespace (other than `default`) .lab[ - List only the pods in the `kube-system` namespace: ```bash kubectl get pods --namespace=kube-system kubectl get pods -n kube-system ``` ] .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Namespaces and other `kubectl` commands - We can use `-n`/`--namespace` with almost every `kubectl` command - Example: - `kubectl create --namespace=X` to create something in namespace X - We can use `-A`/`--all-namespaces` with most commands that manipulate multiple objects - Examples: - `kubectl delete` can delete resources across multiple namespaces - `kubectl label` can add/remove/update labels across multiple namespaces .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## What about `kube-public`? .lab[ - List the pods in the `kube-public` namespace: ```bash kubectl -n kube-public get pods ``` ] Nothing! `kube-public` is created by kubeadm & [used for security bootstrapping](https://kubernetes.io/blog/2017/01/stronger-foundation-for-creating-and-managing-kubernetes-clusters). .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## Exploring `kube-public` - The only interesting object in `kube-public` is a ConfigMap named `cluster-info` .lab[ - List ConfigMap objects: ```bash kubectl -n kube-public get configmaps ``` - Inspect `cluster-info`: ```bash kubectl -n kube-public get configmap cluster-info -o yaml ``` ] Note the `selfLink` URI: `/api/v1/namespaces/kube-public/configmaps/cluster-info` We can use that! .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## Accessing `cluster-info` - Earlier, when trying to access the API server, we got a `Forbidden` message - But `cluster-info` is readable by everyone (even without authentication) .lab[ - Retrieve `cluster-info`: ```bash curl -k https://10.96.0.1/api/v1/namespaces/kube-public/configmaps/cluster-info ``` ] - We were able to access `cluster-info` (without auth) - It contains a `kubeconfig` file .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## Retrieving `kubeconfig` - We can easily extract the `kubeconfig` file from this ConfigMap .lab[ - Display the content of `kubeconfig`: ```bash curl -sk https://10.96.0.1/api/v1/namespaces/kube-public/configmaps/cluster-info \ | jq -r .data.kubeconfig ``` ] - This file holds the canonical address of the API server, and the public key of the CA - This file *does not* hold client keys or tokens - This is not sensitive information, but allows us to establish trust .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: extra-details ## What about `kube-node-lease`? - Starting with Kubernetes 1.14, there is a `kube-node-lease` namespace (or in Kubernetes 1.13 if the NodeLease feature gate is enabled) - That namespace contains one Lease object per node - *Node leases* are a new way to implement node heartbeats (i.e. node regularly pinging the control plane to say "I'm alive!") - For more details, see [Efficient Node Heartbeats KEP] or the [node controller documentation] [Efficient Node Heartbeats KEP]: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/589-efficient-node-heartbeats/README.md [node controller documentation]: https://kubernetes.io/docs/concepts/architecture/nodes/#node-controller .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Services - A *service* is a stable endpoint to connect to "something" (In the initial proposal, they were called "portals") .lab[ - List the services on our cluster with one of these commands: ```bash kubectl get services kubectl get svc ``` ] -- There is already one service on our cluster: the Kubernetes API itself. .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## ClusterIP services - A `ClusterIP` service is internal, available from the cluster only - This is useful for introspection from within containers .lab[ - Try to connect to the API: ```bash curl -k https://`10.96.0.1` ``` - `-k` is used to skip certificate verification - Make sure to replace 10.96.0.1 with the CLUSTER-IP shown by `kubectl get svc` ] The command above should either time out, or show an authentication error. Why? .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Time out - Connections to ClusterIP services only work *from within the cluster* - If we are outside the cluster, the `curl` command will probably time out (Because the IP address, e.g. 10.96.0.1, isn't routed properly outside the cluster) - This is the case with most "real" Kubernetes clusters - To try the connection from within the cluster, we can use [shpod](https://github.com/jpetazzo/shpod) .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Authentication error This is what we should see when connecting from within the cluster: ```json $ curl -k https://10.96.0.1 { "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403 } ``` .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## Explanations - We can see `kind`, `apiVersion`, `metadata` - These are typical of a Kubernetes API reply - Because we *are* talking to the Kubernetes API - The Kubernetes API tells us "Forbidden" (because it requires authentication) - The Kubernetes API is reachable from within the cluster (many apps integrating with Kubernetes will use this) .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- ## DNS integration - Each service also gets a DNS record - The Kubernetes DNS resolver is available *from within pods* (and sometimes, from within nodes, depending on configuration) - Code running in pods can connect to services using their name (e.g. https://kubernetes/...) ??? :EN:- Getting started with kubectl :FR:- Se familiariser avec kubectl .debug[[k8s/kubectlget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlget.md)] --- class: pic .interstitial[] --- name: toc-setting-up-kubernetes class: title Setting up Kubernetes .nav[ [Previous part](#toc-first-contact-with-kubectl) | [Back to table of contents](#toc-part-1) | [Next part](#toc-running-our-first-containers-on-kubernetes) ] .debug[(automatically generated title slide)] --- # Setting up Kubernetes - Kubernetes is made of many components that require careful configuration - Secure operation typically requires TLS certificates and a local CA (certificate authority) - Setting up everything manually is possible, but rarely done (except for learning purposes) - Let's do a quick overview of available options! .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Local development - Are you writing code that will eventually run on Kubernetes? - Then it's a good idea to have a development cluster! - Instead of shipping containers images, we can test them on Kubernetes - Extremely useful when authoring or testing Kubernetes-specific objects (ConfigMaps, Secrets, StatefulSets, Jobs, RBAC, etc.) - Extremely convenient to quickly test/check what a particular thing looks like (e.g. what are the fields a Deployment spec?) .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## One-node clusters - It's perfectly fine to work with a cluster that has only one node - It simplifies a lot of things: - pod networking doesn't even need CNI plugins, overlay networks, etc. - these clusters can be fully contained (no pun intended) in an easy-to-ship VM or container image - some of the security aspects may be simplified (different threat model) - images can be built directly on the node (we don't need to ship them with a registry) - Examples: Docker Desktop, k3d, KinD, MicroK8s, Minikube (some of these also support clusters with multiple nodes) .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Managed clusters ("Turnkey Solutions") - Many cloud providers and hosting providers offer "managed Kubernetes" - The deployment and maintenance of the *control plane* is entirely managed by the provider (ideally, clusters can be spun up automatically through an API, CLI, or web interface) - Given the complexity of Kubernetes, this approach is *strongly recommended* (at least for your first production clusters) - After working for a while with Kubernetes, you will be better equipped to decide: - whether to operate it yourself or use a managed offering - which offering or which distribution works best for you and your needs .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Managed ≠ managed - Managed Kubernetes ≠ managed hosting - Managed hosting typically means that the hosting provider takes care of: - installation, upgrades, time-sensitive security patches, backups - logging and metrics collection - setting up supervision, alerts, and on-call rotation - Managed Kubernetes typically means that the hosting provider takes care of: - installation - maybe upgrades (kind of; you typically need to initiate/coordinate them) - and that's it! .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## "Managed" Kubernetes - "Managed Kubernetes" gives us the equivalent of a raw VM - We still need to add a lot of things to make it production-ready (upgrades, logging, supervision...) - We also need some almost-essential components that don't always come out of the box - ingress controller - network policy controller - storage class... 📽️[How to make Kubernetes ryhme with production readiness](https://www.youtube.com/watch?v=6G4v-ZE6OHI ) .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Observability - Logging, metrics, traces... - Pick a solution (self-hosted, as-a-service?) - Configure control plane, nodes, various components - Set up dashboards, track important metrics (e.g. on AWS, track inter-AZ and external traffic per app to avoid $$$ surprises) - Set up supervision, on-call notifications, on-call rotation .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Backups - Full machine backups of the nodes? (not very effective) - Backup of control plane data? (important; it's not always possible to obtain etcd backups) - Backup of persistent volumes? (good idea; but not always effective) - App-level backups, e.g. database dumps, log-shipping? (more effective and reliable; more work depending on the app and database) .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Upgrades - Control plane *typically automated by the provider; but might cause breakage* - Nodes *best case scenario: can be done in-place; otherwise: requires provisioning new nodes* - Additional components (ingress controller, operators, etc.) *depends wildly of the components!* .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## It's dangerous to go alone! Don't hesitate to hire help before going to production with your first K8S app! .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Node management - Most "Turnkey Solutions" offer fully managed control planes (including control plane upgrades, sometimes done automatically) - However, with most providers, we still need to take care of *nodes* (provisioning, upgrading, scaling the nodes) - Example with Amazon EKS ["managed node groups"](https://docs.aws.amazon.com/eks/latest/userguide/managed-node-groups.html): *...when bugs or issues are reported [...] you're responsible for deploying these patched AMI versions to your managed node groups.* .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Managed clusters differences - Most providers let you pick which Kubernetes version you want - some providers offer up-to-date versions - others lag significantly (sometimes by 2 or 3 minor versions) - Some providers offer multiple networking or storage options - Others will only support one, tied to their infrastructure (changing that is in theory possible, but might be complex or unsupported) - Some providers let you configure or customize the control plane (generally through Kubernetes "feature gates") .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Choosing a provider - Pricing models differ from one provider to another - nodes are generally charged at their usual price - control plane may be free or incur a small nominal fee - Beyond pricing, there are *huge* differences in features between providers - The "major" providers are not always the best ones! - See [this page](https://kubernetes.io/docs/setup/production-environment/turnkey-solutions/) for a list of available providers .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Kubernetes distributions and installers - If you want to run Kubernetes yourselves, there are many options (free, commercial, proprietary, open source ...) - Some of them are installers, while some are complete platforms - Some of them leverage other well-known deployment tools (like Puppet, Terraform ...) - There are too many options to list them all (check [this page](https://kubernetes.io/partners/#iframe-landscape-conformance) for an overview!) .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## kubeadm - kubeadm is a tool part of Kubernetes to facilitate cluster setup - Many other installers and distributions use it (but not all of them) - It can also be used by itself - Excellent starting point to install Kubernetes on your own machines (virtual, physical, it doesn't matter) - It even supports highly available control planes, or "multi-master" (this is more complex, though, because it introduces the need for an API load balancer) .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## Manual setup - The resources below are mainly for educational purposes! - [Kubernetes The Hard Way](https://github.com/kelseyhightower/kubernetes-the-hard-way) by Kelsey Hightower *step by step guide to install Kubernetes on GCP, with certificates, HA...* - [Deep Dive into Kubernetes Internals for Builders and Operators](https://www.youtube.com/watch?v=3KtEAa7_duA) *conference talk setting up a simplified Kubernetes cluster - no security or HA* - 🇫🇷[Démystifions les composants internes de Kubernetes](https://www.youtube.com/watch?v=OCMNA0dSAzc) *improved version of the previous one, with certs and recent k8s versions* .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## About our training clusters - How did we set up these Kubernetes clusters that we're using? -- - We used `kubeadm` on freshly installed VM instances running Ubuntu LTS 1. Install Docker 2. Install Kubernetes packages 3. Run `kubeadm init` on the first node (it deploys the control plane on that node) 4. Set up Cilium (the overlay network) with a single `helm install` command 5. Run `kubeadm join` on the other nodes (with the token produced by `kubeadm init`) 6. Copy the configuration file generated by `kubeadm init` - Check the [prepare VMs README](https://github.com/jpetazzo/container.training/blob/master/prepare-vms/README.md) for more details .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- ## `kubeadm` "drawbacks" - Doesn't set up Docker or any other container engine (this is by design, to give us choice) - Doesn't set up the overlay network (this is also by design, for the same reasons) - HA control plane requires [some extra steps](https://kubernetes.io/docs/setup/independent/high-availability/) - Note that HA control plane also requires setting up a specific API load balancer (which is beyond the scope of kubeadm) ??? :EN:- Various ways to install Kubernetes :FR:- Survol des techniques d'installation de Kubernetes .debug[[k8s/setup-overview.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/setup-overview.md)] --- class: pic .interstitial[] --- name: toc-running-our-first-containers-on-kubernetes class: title Running our first containers on Kubernetes .nav[ [Previous part](#toc-setting-up-kubernetes) | [Back to table of contents](#toc-part-2) | [Next part](#toc-revisiting-kubectl-logs) ] .debug[(automatically generated title slide)] --- # Running our first containers on Kubernetes - First things first: we cannot run a container -- - We are going to run a pod, and in that pod there will be a single container -- - In that container in the pod, we are going to run a simple `ping` command .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- class: extra-details ## If you're running Kubernetes 1.17 (or older)... - This material assumes that you're running a recent version of Kubernetes (at least 1.19) <!-- ##VERSION## --> - You can check your version number with `kubectl version` (look at the server part) - In Kubernetes 1.17 and older, `kubectl run` creates a Deployment - If you're running such an old version: - it's obsolete and no longer maintained - Kubernetes 1.17 is [EOL since January 2021][nonactive] - **upgrade NOW!** [nonactive]: https://kubernetes.io/releases/patch-releases/#non-active-branch-history .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Starting a simple pod with `kubectl run` - `kubectl run` is convenient to start a single pod - We need to specify at least a *name* and the image we want to use - Optionally, we can specify the command to run in the pod .lab[ - Let's ping the address of `localhost`, the loopback interface: ```bash kubectl run pingpong --image alpine ping 127.0.0.1 ``` <!-- ```hide kubectl wait pod --selector=run=pingpong --for condition=ready``` --> ] The output tells us that a Pod was created: ``` pod/pingpong created ``` .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Viewing container output - Let's use the `kubectl logs` command - It takes a Pod name as argument - Unless specified otherwise, it will only show logs of the first container in the pod (Good thing there's only one in ours!) .lab[ - View the result of our `ping` command: ```bash kubectl logs pingpong ``` ] .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Streaming logs in real time - Just like `docker logs`, `kubectl logs` supports convenient options: - `-f`/`--follow` to stream logs in real time (à la `tail -f`) - `--tail` to indicate how many lines you want to see (from the end) - `--since` to get logs only after a given timestamp .lab[ - View the latest logs of our `ping` command: ```bash kubectl logs pingpong --tail 1 --follow ``` - Stop it with Ctrl-C <!-- ```wait seq=3``` ```keys ^C``` --> ] .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Scaling our application - `kubectl` gives us a simple command to scale a workload: `kubectl scale TYPE NAME --replicas=HOWMANY` - Let's try it on our Pod, so that we have more Pods! .lab[ - Try to scale the Pod: ```bash kubectl scale pod pingpong --replicas=3 ``` ] 🤔 We get the following error, what does that mean? ``` Error from server (NotFound): the server could not find the requested resource ``` .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Scaling a Pod - We cannot "scale a Pod" (that's not completely true; we could give it more CPU/RAM) - If we want more Pods, we need to create more Pods (i.e. execute `kubectl run` multiple times) - There must be a better way! (spoiler alert: yes, there is a better way!) .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- class: extra-details ## `NotFound` - What's the meaning of that error? ``` Error from server (NotFound): the server could not find the requested resource ``` - When we execute `kubectl scale THAT-RESOURCE --replicas=THAT-MANY`, <br/> it is like telling Kubernetes: *go to THAT-RESOURCE and set the scaling button to position THAT-MANY* - Pods do not have a "scaling button" - Try to execute the `kubectl scale pod` command with `-v6` - We see a `PATCH` request to `/scale`: that's the "scaling button" (technically it's called a *subresource* of the Pod) .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Creating more pods - We are going to create a ReplicaSet (= set of replicas = set of identical pods) - In fact, we will create a Deployment, which itself will create a ReplicaSet - Why so many layers? We'll explain that shortly, don't worry! .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Creating a Deployment running `ping` - Let's create a Deployment instead of a single Pod .lab[ - Create the Deployment; pay attention to the `--`: ```bash kubectl create deployment pingpong --image=alpine -- ping 127.0.0.1 ``` ] - The `--` is used to separate: - "options/flags of `kubectl create` - command to run in the container .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## What has been created? .lab[ <!-- ```hide kubectl wait pod --selector=app=pingpong --for condition=ready ``` --> - Check the resources that were created: ```bash kubectl get all ``` ] Note: `kubectl get all` is a lie. It doesn't show everything. (But it shows a lot of "usual suspects", i.e. commonly used resources.) .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## There's a lot going on here! ``` NAME READY STATUS RESTARTS AGE pod/pingpong 1/1 Running 0 4m17s pod/pingpong-6ccbc77f68-kmgfn 1/1 Running 0 11s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3h45 NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/pingpong 1/1 1 1 11s NAME DESIRED CURRENT READY AGE replicaset.apps/pingpong-6ccbc77f68 1 1 1 11s ``` Our new Pod is not named `pingpong`, but `pingpong-xxxxxxxxxxx-yyyyy`. We have a Deployment named `pingpong`, and an extra ReplicaSet, too. What's going on? .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## From Deployment to Pod We have the following resources: - `deployment.apps/pingpong` This is the Deployment that we just created. - `replicaset.apps/pingpong-xxxxxxxxxx` This is a Replica Set created by this Deployment. - `pod/pingpong-xxxxxxxxxx-yyyyy` This is a *pod* created by the Replica Set. Let's explain what these things are. .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Pod - Can have one or multiple containers - Runs on a single node (Pod cannot "straddle" multiple nodes) - Pods cannot be moved (e.g. in case of node outage) - Pods cannot be scaled horizontally (except by manually creating more Pods) .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- class: extra-details ## Pod details - A Pod is not a process; it's an environment for containers - it cannot be "restarted" - it cannot "crash" - The containers in a Pod can crash - They may or may not get restarted (depending on Pod's restart policy) - If all containers exit successfully, the Pod ends in "Succeeded" phase - If some containers fail and don't get restarted, the Pod ends in "Failed" phase .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Replica Set - Set of identical (replicated) Pods - Defined by a pod template + number of desired replicas - If there are not enough Pods, the Replica Set creates more (e.g. in case of node outage; or simply when scaling up) - If there are too many Pods, the Replica Set deletes some (e.g. if a node was disconnected and comes back; or when scaling down) - We can scale up/down a Replica Set - we update the manifest of the Replica Set - as a consequence, the Replica Set controller creates/deletes Pods .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Deployment - Replica Sets control *identical* Pods - Deployments are used to roll out different Pods (different image, command, environment variables, ...) - When we update a Deployment with a new Pod definition: - a new Replica Set is created with the new Pod definition - that new Replica Set is progressively scaled up - meanwhile, the old Replica Set(s) is(are) scaled down - This is a *rolling update*, minimizing application downtime - When we scale up/down a Deployment, it scales up/down its Replica Set .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Can we scale now? - Let's try `kubectl scale` again, but on the Deployment! .lab[ - Scale our `pingpong` deployment: ```bash kubectl scale deployment pingpong --replicas 3 ``` - Note that we could also write it like this: ```bash kubectl scale deployment/pingpong --replicas 3 ``` - Check that we now have multiple pods: ```bash kubectl get pods ``` ] .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- class: extra-details ## Scaling a Replica Set - What if we scale the Replica Set instead of the Deployment? - The Deployment would notice it right away and scale back to the initial level - The Replica Set makes sure that we have the right numbers of Pods - The Deployment makes sure that the Replica Set has the right size (conceptually, it delegates the management of the Pods to the Replica Set) - This might seem weird (why this extra layer?) but will soon make sense (when we will look at how rolling updates work!) .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Checking Deployment logs - `kubectl logs` needs a Pod name - But it can also work with a *type/name* (e.g. `deployment/pingpong`) .lab[ - View the result of our `ping` command: ```bash kubectl logs deploy/pingpong --tail 2 ``` ] - It shows us the logs of the first Pod of the Deployment - We'll see later how to get the logs of *all* the Pods! .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Resilience - The *deployment* `pingpong` watches its *replica set* - The *replica set* ensures that the right number of *pods* are running - What happens if pods disappear? .lab[ - In a separate window, watch the list of pods: ```bash watch kubectl get pods ``` <!-- ```wait Every 2.0s``` ```tmux split-pane -v``` --> - Destroy the pod currently shown by `kubectl logs`: ``` kubectl delete pod pingpong-xxxxxxxxxx-yyyyy ``` <!-- ```tmux select-pane -t 0``` ```copy pingpong-[^-]*-.....``` ```tmux last-pane``` ```keys kubectl delete pod ``` ```paste``` ```key ^J``` ```check``` --> ] .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## What happened? - `kubectl delete pod` terminates the pod gracefully (sending it the TERM signal and waiting for it to shutdown) - As soon as the pod is in "Terminating" state, the Replica Set replaces it - But we can still see the output of the "Terminating" pod in `kubectl logs` - Until 30 seconds later, when the grace period expires - The pod is then killed, and `kubectl logs` exits .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- ## Deleting a standalone Pod - What happens if we delete a standalone Pod? (like the first `pingpong` Pod that we created) .lab[ - Delete the Pod: ```bash kubectl delete pod pingpong ``` <!-- ```key ^D``` ```key ^C``` --> ] - No replacement Pod gets created because there is no *controller* watching it - That's why we will rarely use standalone Pods in practice (except for e.g. punctual debugging or executing a short supervised task) ??? :EN:- Running pods and deployments :FR:- Créer un pod et un déploiement .debug[[k8s/kubectl-run.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-run.md)] --- class: pic .interstitial[] --- name: toc-revisiting-kubectl-logs class: title Revisiting `kubectl logs` .nav[ [Previous part](#toc-running-our-first-containers-on-kubernetes) | [Back to table of contents](#toc-part-2) | [Next part](#toc-exposing-containers) ] .debug[(automatically generated title slide)] --- # Revisiting `kubectl logs` - In this section, we assume that we have a Deployment with multiple Pods (e.g. `pingpong` that we scaled to at least 3 pods) - We will highlights some of the limitations of `kubectl logs` .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- ## Streaming logs of multiple pods - By default, `kubectl logs` shows us the output of a single Pod .lab[ - Try to check the output of the Pods related to a Deployment: ```bash kubectl logs deploy/pingpong --tail 1 --follow ``` <!-- ```wait using pod/pingpong-``` ```keys ^C``` --> ] `kubectl logs` only shows us the logs of one of the Pods. .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- ## Viewing logs of multiple pods - When we specify a deployment name, only one single pod's logs are shown - We can view the logs of multiple pods by specifying a *selector* - If we check the pods created by the deployment, they all have the label `app=pingpong` (this is just a default label that gets added when using `kubectl create deployment`) .lab[ - View the last line of log from all pods with the `app=pingpong` label: ```bash kubectl logs -l app=pingpong --tail 1 ``` ] .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- ## Streaming logs of multiple pods - Can we stream the logs of all our `pingpong` pods? .lab[ - Combine `-l` and `-f` flags: ```bash kubectl logs -l app=pingpong --tail 1 -f ``` <!-- ```wait seq=``` ```key ^C``` --> ] *Note: combining `-l` and `-f` is only possible since Kubernetes 1.14!* *Let's try to understand why ...* .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- class: extra-details ## Streaming logs of many pods - Let's see what happens if we try to stream the logs for more than 5 pods .lab[ - Scale up our deployment: ```bash kubectl scale deployment pingpong --replicas=8 ``` - Stream the logs: ```bash kubectl logs -l app=pingpong --tail 1 -f ``` <!-- ```wait error:``` --> ] We see a message like the following one: ``` error: you are attempting to follow 8 log streams, but maximum allowed concurency is 5, use --max-log-requests to increase the limit ``` .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- class: extra-details ## Why can't we stream the logs of many pods? - `kubectl` opens one connection to the API server per pod - For each pod, the API server opens one extra connection to the corresponding kubelet - If there are 1000 pods in our deployment, that's 1000 inbound + 1000 outbound connections on the API server - This could easily put a lot of stress on the API server - Prior Kubernetes 1.14, it was decided to *not* allow multiple connections - From Kubernetes 1.14, it is allowed, but limited to 5 connections (this can be changed with `--max-log-requests`) - For more details about the rationale, see [PR #67573](https://github.com/kubernetes/kubernetes/pull/67573) .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- ## Shortcomings of `kubectl logs` - We don't see which pod sent which log line - If pods are restarted / replaced, the log stream stops - If new pods are added, we don't see their logs - To stream the logs of multiple pods, we need to write a selector - There are external tools to address these shortcomings (e.g.: [Stern](https://github.com/stern/stern)) .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- class: extra-details ## `kubectl logs -l ... --tail N` - If we run this with Kubernetes 1.12, the last command shows multiple lines - This is a regression when `--tail` is used together with `-l`/`--selector` - It always shows the last 10 lines of output for each container (instead of the number of lines specified on the command line) - The problem was fixed in Kubernetes 1.13 *See [#70554](https://github.com/kubernetes/kubernetes/issues/70554) for details.* ??? :EN:- Viewing logs with "kubectl logs" :FR:- Consulter les logs avec "kubectl logs" .debug[[k8s/kubectl-logs.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectl-logs.md)] --- ## 19,000 words They say, "a picture is worth one thousand words." The following 19 slides show what really happens when we run: ```bash kubectl create deployment web --image=nginx ``` .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic  .debug[[k8s/deploymentslideshow.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/deploymentslideshow.md)] --- class: pic .interstitial[] --- name: toc-exposing-containers class: title Exposing containers .nav[ [Previous part](#toc-revisiting-kubectl-logs) | [Back to table of contents](#toc-part-2) | [Next part](#toc-shipping-images-with-a-registry) ] .debug[(automatically generated title slide)] --- # Exposing containers - We can connect to our pods using their IP address - Then we need to figure out a lot of things: - how do we look up the IP address of the pod(s)? - how do we connect from outside the cluster? - how do we load balance traffic? - what if a pod fails? - Kubernetes has a resource type named *Service* - Services address all these questions! .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## ⚠️ Heads up! - We're going to connect directly to pods and services, using internal addresses - This will only work: - if you're attending a live class with our special lab environment - or if you're using our dev containers within codespaces - If you're using a "normal" Kubernetes cluster (including minikube, KinD, etc): *you will not be able to access these internal addresses directly!* - In that case, we suggest that you run an interactive container, e.g.: ```bash kubectl run --rm -ti --image=archlinux myshell ``` - ...And each time you see a `curl` or `ping` command run it in that container instead .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: extra-details ## But, why? - Internal addresses are only reachable from within the cluster (=from a pod, or when logged directly inside a node) - Our special lab environments and our dev containers let us do it anyways (because it's nice and convenient when learning Kubernetes) - But that doesn't work on "normal" Kubernetes clusters - Instead, we can use [`kubectl port-forward`][kubectl-port-forward] on these clusters [kubectl-port-forward]: https://kubernetes.io/docs/reference/kubectl/generated/kubectl_port-forward/ .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Running containers with open ports - Let's run a small web server in a container - We are going to use `jpetazzo/color`, a tiny HTTP server written in Go - `jpetazzo/color` listens on port 80 - It serves a page showing the pod's name (this will be useful when checking load balancing behavior) - We could also use the `nginx` official image instead (but we wouldn't be able to tell the backends from each other) .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Running our HTTP server - We will create a deployment with `kubectl create deployment` - This will create a Pod running our HTTP server .lab[ - Create a deployment named `blue`: ```bash kubectl create deployment blue --image=jpetazzo/color ``` ] .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Connecting to the HTTP server - Let's connect to the HTTP server directly (just to make sure everything works fine; we'll add the Service later) .lab[ - Get the IP address of the Pod: ```bash kubectl get pods -o wide ``` - Send an HTTP request to the Pod: ```bash curl http://`IP-ADDRESS` ``` ] You should see a response from the Pod. .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## The Pod doesn't have a "stable identity" - The IP address that we used above isn't "stable" (if the Pod gets deleted, the replacement Pod will have a different address) .lab[ - Check the IP addresses of running Pods: ```bash watch kubectl get pods -o wide ``` - Delete the Pod: ```bash kubectl delete pod `blue-xxxxxxxx-yyyyy` ``` - Check that the replacement Pod has a different IP address ] .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Services in a nutshell - Services give us a *stable endpoint* to connect to a pod or a group of pods - An easy way to create a service is to use `kubectl expose` - If we have a deployment named `my-little-deploy`, we can run: `kubectl expose deployment my-little-deploy --port=80` ... and this will create a service with the same name (`my-little-deploy`) - Services are automatically added to an internal DNS zone (in the example above, our code can now connect to http://my-little-deploy/) .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Exposing our deployment - Let's create a Service for our Deployment .lab[ - Expose the HTTP port of our server: ```bash kubectl expose deployment blue --port=80 ``` - Look up which IP address was allocated: ```bash kubectl get service ``` ] - By default, this created a `ClusterIP` service (we'll discuss later the different types of services) .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: extra-details ## Services are layer 4 constructs - Services can have IP addresses, but they are still *layer 4* (i.e. a service is not just an IP address; it's an IP address + protocol + port) - As a result: you *have to* indicate the port number for your service (with some exceptions, like `ExternalName` or headless services, covered later) .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Testing our service - We will now send a few HTTP requests to our Pod .lab[ - Let's obtain the IP address that was allocated for our service, *programmatically:* ```bash CLUSTER_IP=$(kubectl get svc blue -o go-template='{{ .spec.clusterIP }}') ``` <!-- ```hide kubectl wait deploy blue --for condition=available``` ```key ^D``` ```key ^C``` --> - Send a few requests: ```bash for i in $(seq 10); do curl http://$CLUSTER_IP; done ``` ] .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## A *stable* endpoint - Let's see what happens when the Pod has a problem .lab[ - Keep sending requests to the Service address: ```bash while sleep 0.3; do curl -m1 http://$CLUSTER_IP; done ``` - Meanwhile, delete the Pod: ```bash kubectl delete pod `blue-xxxxxxxx-yyyyy` ``` ] - There might be a short interruption when we delete the pod... - ...But requests will keep flowing after that (without requiring a manual intervention) - The `-m1` option is here to specify a 1-second timeout .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Load balancing - The Service will also act as a load balancer (if there are multiple Pods in the Deployment) .lab[ - Scale up the Deployment: ```bash kubectl scale deployment blue --replicas=3 ``` - Send a bunch of requests to the Service: ```bash for i in $(seq 20); do curl http://$CLUSTER_IP; done ``` ] - Our requests are load balanced across the Pods! .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## DNS integration - Kubernetes provides an internal DNS resolver - The resolver maps service names to their internal addresses - By default, this only works *inside Pods* (not from the nodes themselves) .lab[ - Get a shell in a Pod: ```bash kubectl run --rm -it --image=archlinux test-dns-integration ``` - Try to resolve the `blue` Service from the Pod: ```bash curl blue ``` ] .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: extra-details ## Under the hood... - Let's check the content of `/etc/resolv.conf` inside a Pod - It should look approximately like this: ``` search default.svc.cluster.local svc.cluster.local cluster.local ... nameserver 10.96.0.10 options ndots:5 ``` - Let's break down what these lines mean... .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: extra-details ## `nameserver 10.96.0.10` - This is the address of the DNS server used by programs running in the Pod - The exact address might be different (this one is the default one when setting up a cluster with `kubeadm`) - This address will correspond to a Service on our cluster - Check what we have in `kube-system`: ```bash kubectl get services --namespace=kube-system ``` - There will typically be a service named `kube-dns` with that exact address (that's Kubernetes' internal DNS service!) .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: extra-details ## `search default.svc.cluster.local ...` - This is the "search list" - When a program tries to resolve `foo`, the resolver will try to resolve: `foo.default.svc.cluster.local` (if the Pod is in the `default` Namespace) `foo.svc.cluster.local` `foo.cluster.local` ...(the other entries in the search list)... `foo` - As a result, if there is Service named `foo` in the Pod's Namespace, we obtain its address! .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: extra-details ## Do You Want To Know More? - If you want even more details about DNS resolution on Kubernetes and Linux... check [this blog post][dnsblog]! [dnsblog]: https://jpetazzo.github.io/2024/05/12/understanding-kubernetes-dns-hostnetwork-dnspolicy-dnsconfigforming/ .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- ## Advantages of services - We don't need to look up the IP address of the pod(s) (we resolve the IP address of the service using DNS) - There are multiple service types; some of them allow external traffic (e.g. `LoadBalancer` and `NodePort`) - Services provide load balancing (for both internal and external traffic) - Service addresses are independent from pods' addresses (when a pod fails, the service seamlessly sends traffic to its replacement) ??? :EN:- Accessing pods through services :EN:- Service discovery and load balancing :FR:- Exposer un service :FR:- Le DNS interne de Kubernetes et la *service discovery* .debug[[k8s/kubectlexpose.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/kubectlexpose.md)] --- class: pic .interstitial[] --- name: toc-shipping-images-with-a-registry class: title Shipping images with a registry .nav[ [Previous part](#toc-exposing-containers) | [Back to table of contents](#toc-part-2) | [Next part](#toc-running-our-application-on-kubernetes) ] .debug[(automatically generated title slide)] --- # Shipping images with a registry - Initially, our app was running on a single node - We could *build* and *run* in the same place - Therefore, we did not need to *ship* anything - Now that we want to run on a cluster, things are different - The easiest way to ship container images is to use a registry .debug[[k8s/shippingimages.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/shippingimages.md)] --- ## How Docker registries work (a reminder) - What happens when we execute `docker run alpine` ? - If the Engine needs to pull the `alpine` image, it expands it into `library/alpine` - `library/alpine` is expanded into `index.docker.io/library/alpine` - The Engine communicates with `index.docker.io` to retrieve `library/alpine:latest` - To use something else than `index.docker.io`, we specify it in the image name - Examples: ```bash docker pull gcr.io/google-containers/alpine-with-bash:1.0 docker build -t registry.mycompany.io:5000/myimage:awesome . docker push registry.mycompany.io:5000/myimage:awesome ``` .debug[[k8s/shippingimages.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/shippingimages.md)] --- ## Running DockerCoins on Kubernetes - Create one deployment for each component (hasher, redis, rng, webui, worker) - Expose deployments that need to accept connections (hasher, redis, rng, webui) - For redis, we can use the official redis image - For the 4 others, we need to build images and push them to some registry .debug[[k8s/shippingimages.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/shippingimages.md)] --- ## Building and shipping images - There are *many* options! - Manually: - build locally (with `docker build` or otherwise) - push to the registry - Automatically: - build and test locally - when ready, commit and push a code repository - the code repository notifies an automated build system - that system gets the code, builds it, pushes the image to the registry .debug[[k8s/shippingimages.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/shippingimages.md)] --- ## Which registry do we want to use? - There are SAAS products like Docker Hub, Quay ... - Each major cloud provider has an option as well (ACR on Azure, ECR on AWS, GCR on Google Cloud...) - There are also commercial products to run our own registry (Docker EE, Quay...) - And open source options, too! - When picking a registry, pay attention to its build system (when it has one) .debug[[k8s/shippingimages.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/shippingimages.md)] --- ## Building on the fly - Conceptually, it is possible to build images on the fly from a repository - Example: [ctr.run](https://ctr.run/) (deprecated in August 2020, after being aquired by Datadog) - It did allow something like this: ```bash docker run ctr.run/github.com/jpetazzo/container.training/dockercoins/hasher ``` - No alternative yet (free startup idea, anyone?) ??? :EN:- Shipping images to Kubernetes :FR:- Déployer des images sur notre cluster .debug[[k8s/shippingimages.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/shippingimages.md)] --- ## Using images from the Docker Hub - For everyone's convenience, we took care of building DockerCoins images - We pushed these images to the DockerHub, under the [dockercoins](https://hub.docker.com/u/dockercoins) user - These images are *tagged* with a version number, `v0.1` - The full image names are therefore: - `dockercoins/hasher:v0.1` - `dockercoins/rng:v0.1` - `dockercoins/webui:v0.1` - `dockercoins/worker:v0.1` .debug[[k8s/buildshiprun-dockerhub.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/buildshiprun-dockerhub.md)] --- class: pic .interstitial[] --- name: toc-running-our-application-on-kubernetes class: title Running our application on Kubernetes .nav[ [Previous part](#toc-shipping-images-with-a-registry) | [Back to table of contents](#toc-part-2) | [Next part](#toc-the-kubernetes-dashboard) ] .debug[(automatically generated title slide)] --- # Running our application on Kubernetes - We can now deploy our code (as well as a redis instance) .lab[ - Deploy `redis`: ```bash kubectl create deployment redis --image=redis ``` - Deploy everything else: ```bash kubectl create deployment hasher --image=dockercoins/hasher:v0.1 kubectl create deployment rng --image=dockercoins/rng:v0.1 kubectl create deployment webui --image=dockercoins/webui:v0.1 kubectl create deployment worker --image=dockercoins/worker:v0.1 ``` ] .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- class: extra-details ## Deploying other images - If we wanted to deploy images from another registry ... - ... Or with a different tag ... - ... We could use the following snippet: ```bash REGISTRY=dockercoins TAG=v0.1 for SERVICE in hasher rng webui worker; do kubectl create deployment $SERVICE --image=$REGISTRY/$SERVICE:$TAG done ``` .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- ## Is this working? - After waiting for the deployment to complete, let's look at the logs! (Hint: use `kubectl get deploy -w` to watch deployment events) .lab[ <!-- ```hide kubectl wait deploy/rng --for condition=available kubectl wait deploy/worker --for condition=available ``` --> - Look at some logs: ```bash kubectl logs deploy/rng kubectl logs deploy/worker ``` ] -- 🤔 `rng` is fine ... But not `worker`. -- 💡 Oh right! We forgot to `expose`. .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- ## Connecting containers together - Three deployments need to be reachable by others: `hasher`, `redis`, `rng` - `worker` doesn't need to be exposed - `webui` will be dealt with later .lab[ - Expose each deployment, specifying the right port: ```bash kubectl expose deployment redis --port 6379 kubectl expose deployment rng --port 80 kubectl expose deployment hasher --port 80 ``` ] .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- ## Is this working yet? - The `worker` has an infinite loop, that retries 10 seconds after an error .lab[ - Stream the worker's logs: ```bash kubectl logs deploy/worker --follow ``` (Give it about 10 seconds to recover) <!-- ```wait units of work done, updating hash counter``` ```key ^C``` --> ] -- We should now see the `worker`, well, working happily. .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- ## Exposing services for external access - Now we would like to access the Web UI - We will expose it with a `NodePort` (just like we did for the registry) .lab[ - Create a `NodePort` service for the Web UI: ```bash kubectl expose deploy/webui --type=NodePort --port=80 ``` - Check the port that was allocated: ```bash kubectl get svc ``` ] .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- ## Accessing the web UI - We can now connect to *any node*, on the allocated node port, to view the web UI .lab[ - Open the web UI in your browser (http://node-ip-address:3xxxx/) <!-- ```open http://node1:3xxxx/``` --> ] -- Yes, this may take a little while to update. *(Narrator: it was DNS.)* -- *Alright, we're back to where we started, when we were running on a single node!* ??? :EN:- Running our demo app on Kubernetes :FR:- Faire tourner l'application de démo sur Kubernetes .debug[[k8s/ourapponkube.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/ourapponkube.md)] --- class: pic .interstitial[] --- name: toc-the-kubernetes-dashboard class: title The Kubernetes dashboard .nav[ [Previous part](#toc-running-our-application-on-kubernetes) | [Back to table of contents](#toc-part-3) | [Next part](#toc-security-implications-of-kubectl-apply) ] .debug[(automatically generated title slide)] --- # The Kubernetes dashboard - Kubernetes resources can also be viewed with a web dashboard - Dashboard users need to authenticate (typically with a token) - The dashboard should be exposed over HTTPS (to prevent interception of the aforementioned token) - Ideally, this requires obtaining a proper TLS certificate (for instance, with Let's Encrypt) .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Three ways to install the dashboard - Our `k8s` directory has no less than three manifests! - `dashboard-recommended.yaml` (purely internal dashboard; user must be created manually) - `dashboard-with-token.yaml` (dashboard exposed with NodePort; creates an admin user for us) - `dashboard-insecure.yaml` aka *YOLO* (dashboard exposed over HTTP; gives root access to anonymous users) .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## `dashboard-insecure.yaml` - This will allow anyone to deploy anything on your cluster (without any authentication whatsoever) - **Do not** use this, except maybe on a local cluster (or a cluster that you will destroy a few minutes later) - On "normal" clusters, use `dashboard-with-token.yaml` instead! .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## What's in the manifest? - The dashboard itself - An HTTP/HTTPS unwrapper (using `socat`) - The guest/admin account .lab[ - Create all the dashboard resources, with the following command: ```bash kubectl apply -f ~/container.training/k8s/dashboard-insecure.yaml ``` ] .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Connecting to the dashboard .lab[ - Check which port the dashboard is on: ```bash kubectl get svc dashboard ``` ] You'll want the `3xxxx` port. .lab[ - Connect to http://oneofournodes:3xxxx/ <!-- ```open http://node1:3xxxx/``` --> ] The dashboard will then ask you which authentication you want to use. .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Dashboard authentication - We have three authentication options at this point: - token (associated with a role that has appropriate permissions) - kubeconfig (e.g. using the `~/.kube/config` file from `node1`) - "skip" (use the dashboard "service account") - Let's use "skip": we're logged in! -- .warning[Remember, we just added a backdoor to our Kubernetes cluster!] .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Closing the backdoor - Seriously, don't leave that thing running! .lab[ - Remove what we just created: ```bash kubectl delete -f ~/container.training/k8s/dashboard-insecure.yaml ``` ] .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## The risks - The steps that we just showed you are *for educational purposes only!* - If you do that on your production cluster, people [can and will abuse it](https://redlock.io/blog/cryptojacking-tesla) - For an in-depth discussion about securing the dashboard, <br/> check [this excellent post on Heptio's blog](https://blog.heptio.com/on-securing-the-kubernetes-dashboard-16b09b1b7aca) .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## `dashboard-with-token.yaml` - This is a less risky way to deploy the dashboard - It's not completely secure, either: - we're using a self-signed certificate - this is subject to eavesdropping attacks - Using `kubectl port-forward` or `kubectl proxy` is even better .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## What's in the manifest? - The dashboard itself (but exposed with a `NodePort`) - A ServiceAccount with `cluster-admin` privileges (named `kubernetes-dashboard:cluster-admin`) .lab[ - Create all the dashboard resources, with the following command: ```bash kubectl apply -f ~/container.training/k8s/dashboard-with-token.yaml ``` ] .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Obtaining the token - The manifest creates a ServiceAccount - Kubernetes will automatically generate a token for that ServiceAccount .lab[ - Display the token: ```bash kubectl --namespace=kubernetes-dashboard \ describe secret cluster-admin-token ``` ] The token should start with `eyJ...` (it's a JSON Web Token). Note that the secret name will actually be `cluster-admin-token-xxxxx`. <br/> (But `kubectl` prefix matches are great!) .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Connecting to the dashboard .lab[ - Check which port the dashboard is on: ```bash kubectl get svc --namespace=kubernetes-dashboard ``` ] You'll want the `3xxxx` port. .lab[ - Connect to http://oneofournodes:3xxxx/ <!-- ```open http://node1:3xxxx/``` --> ] The dashboard will then ask you which authentication you want to use. .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Dashboard authentication - Select "token" authentication - Copy paste the token (starting with `eyJ...`) obtained earlier - We're logged in! .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## Other dashboards - [Kube Web View](https://codeberg.org/hjacobs/kube-web-view) - read-only dashboard - optimized for "troubleshooting and incident response" - see [vision and goals](https://kube-web-view.readthedocs.io/en/latest/vision.html#vision) for details - [Kube Ops View](https://codeberg.org/hjacobs/kube-ops-view) - "provides a common operational picture for multiple Kubernetes clusters" .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- class: pic .interstitial[] --- name: toc-security-implications-of-kubectl-apply class: title Security implications of `kubectl apply` .nav[ [Previous part](#toc-the-kubernetes-dashboard) | [Back to table of contents](#toc-part-3) | [Next part](#toc-scaling-our-demo-app) ] .debug[(automatically generated title slide)] --- # Security implications of `kubectl apply` - When we do `kubectl apply -f <URL>`, we create arbitrary resources - Resources can be evil; imagine a `deployment` that ... -- - starts bitcoin miners on the whole cluster -- - hides in a non-default namespace -- - bind-mounts our nodes' filesystem -- - inserts SSH keys in the root account (on the node) -- - encrypts our data and ransoms it -- - ☠️☠️☠️ .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- ## `kubectl apply` is the new `curl | sh` - `curl | sh` is convenient - It's safe if you use HTTPS URLs from trusted sources -- - `kubectl apply -f` is convenient - It's safe if you use HTTPS URLs from trusted sources - Example: the official setup instructions for most pod networks -- - It introduces new failure modes (for instance, if you try to apply YAML from a link that's no longer valid) ??? :EN:- The Kubernetes dashboard :FR:- Le *dashboard* Kubernetes .debug[[k8s/dashboard.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/dashboard.md)] --- class: pic .interstitial[] --- name: toc-scaling-our-demo-app class: title Scaling our demo app .nav[ [Previous part](#toc-security-implications-of-kubectl-apply) | [Back to table of contents](#toc-part-3) | [Next part](#toc-daemon-sets) ] .debug[(automatically generated title slide)] --- # Scaling our demo app - Our ultimate goal is to get more DockerCoins (i.e. increase the number of loops per second shown on the web UI) - Let's look at the architecture again:  - The loop is done in the worker; perhaps we could try adding more workers? .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Adding another worker - All we have to do is scale the `worker` Deployment .lab[ - Open a new terminal to keep an eye on our pods: ```bash kubectl get pods -w ``` <!-- ```wait RESTARTS``` ```tmux split-pane -h``` --> - Now, create more `worker` replicas: ```bash kubectl scale deployment worker --replicas=2 ``` ] After a few seconds, the graph in the web UI should show up. .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Adding more workers - If 2 workers give us 2x speed, what about 3 workers? .lab[ - Scale the `worker` Deployment further: ```bash kubectl scale deployment worker --replicas=3 ``` ] The graph in the web UI should go up again. (This is looking great! We're gonna be RICH!) .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Adding even more workers - Let's see if 10 workers give us 10x speed! .lab[ - Scale the `worker` Deployment to a bigger number: ```bash kubectl scale deployment worker --replicas=10 ``` <!-- ```key ^D``` ```key ^C``` --> ] -- The graph will peak at 10 hashes/second. (We can add as many workers as we want: we will never go past 10 hashes/second.) .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- class: extra-details ## Didn't we briefly exceed 10 hashes/second? - It may *look like it*, because the web UI shows instant speed - The instant speed can briefly exceed 10 hashes/second - The average speed cannot - The instant speed can be biased because of how it's computed .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- class: extra-details ## Why instant speed is misleading - The instant speed is computed client-side by the web UI - The web UI checks the hash counter once per second <br/> (and does a classic (h2-h1)/(t2-t1) speed computation) - The counter is updated once per second by the workers - These timings are not exact <br/> (e.g. the web UI check interval is client-side JavaScript) - Sometimes, between two web UI counter measurements, <br/> the workers are able to update the counter *twice* - During that cycle, the instant speed will appear to be much bigger <br/> (but it will be compensated by lower instant speed before and after) .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Why are we stuck at 10 hashes per second? - If this was high-quality, production code, we would have instrumentation (Datadog, Honeycomb, New Relic, statsd, Sumologic, ...) - It's not! - Perhaps we could benchmark our web services? (with tools like `ab`, or even simpler, `httping`) .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Benchmarking our web services - We want to check `hasher` and `rng` - We are going to use `httping` - It's just like `ping`, but using HTTP `GET` requests (it measures how long it takes to perform one `GET` request) - It's used like this: ``` httping [-c count] http://host:port/path ``` - Or even simpler: ``` httping ip.ad.dr.ess ``` - We will use `httping` on the ClusterIP addresses of our services .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Obtaining ClusterIP addresses - We can simply check the output of `kubectl get services` - Or do it programmatically, as in the example below .lab[ - Retrieve the IP addresses: ```bash HASHER=$(kubectl get svc hasher -o go-template={{.spec.clusterIP}}) RNG=$(kubectl get svc rng -o go-template={{.spec.clusterIP}}) ``` ] Now we can access the IP addresses of our services through `$HASHER` and `$RNG`. .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Checking `hasher` and `rng` response times .lab[ - Check the response times for both services: ```bash httping -c 3 $HASHER httping -c 3 $RNG ``` ] - `hasher` is fine (it should take a few milliseconds to reply) - `rng` is not (it should take about 700 milliseconds if there are 10 workers) - Something is wrong with `rng`, but ... what? ??? :EN:- Scaling up our demo app :FR:- *Scale up* de l'application de démo .debug[[k8s/scalingdockercoins.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/scalingdockercoins.md)] --- ## Let's draw hasty conclusions - The bottleneck seems to be `rng` - *What if* we don't have enough entropy and can't generate enough random numbers? - We need to scale out the `rng` service on multiple machines! Note: this is a fiction! We have enough entropy. But we need a pretext to scale out. (In fact, the code of `rng` uses `/dev/urandom`, which never runs out of entropy... <br/> ...and is [just as good as `/dev/random`](http://www.slideshare.net/PacSecJP/filippo-plain-simple-reality-of-entropy).) .debug[[shared/hastyconclusions.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/hastyconclusions.md)] --- class: pic .interstitial[] --- name: toc-daemon-sets class: title Daemon sets .nav[ [Previous part](#toc-scaling-our-demo-app) | [Back to table of contents](#toc-part-3) | [Next part](#toc-labels-and-selectors) ] .debug[(automatically generated title slide)] --- # Daemon sets - We want to scale `rng` in a way that is different from how we scaled `worker` - We want one (and exactly one) instance of `rng` per node - We *do not want* two instances of `rng` on the same node - We will do that with a *daemon set* .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Why not a deployment? - Can't we just do `kubectl scale deployment rng --replicas=...`? -- - Nothing guarantees that the `rng` containers will be distributed evenly - If we add nodes later, they will not automatically run a copy of `rng` - If we remove (or reboot) a node, one `rng` container will restart elsewhere (and we will end up with two instances `rng` on the same node) - By contrast, a daemon set will start one pod per node and keep it that way (as nodes are added or removed) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Daemon sets in practice - Daemon sets are great for cluster-wide, per-node processes: - network components like `kube-proxy`, `calico`, `cilium`... - storage components (e.g. CSI plugins) - monitoring agents - hardware management tools (e.g. SCSI/FC HBA agents) - etc. - They can also be restricted to run [only on some nodes](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/#running-pods-on-only-some-nodes) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Creating a daemon set <!-- ##VERSION## --> - Unfortunately, as of Kubernetes 1.36, the CLI cannot create daemon sets -- - More precisely: it doesn't have a subcommand to create a daemon set -- - But any kind of resource can always be created by providing a YAML description: ```bash kubectl apply -f foo.yaml ``` -- - How do we create the YAML file for our daemon set? -- - option 1: [read the docs](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/#create-a-daemonset) -- - option 2: `vi` our way out of it .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Creating the YAML file for our daemon set - DaemonSets and Deployments should be *pretty similar* - They both define how to create Pods - Can we transform a Deployment into a DaemonSet? 🤔 - Let's try! .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Generating a Deployment manifest - Let's use `kubectl create deployment -o yaml --dry-run=client` .lab[ - Generate the YAML for a Deployment: ```bash kubectl create deployment rng --image=dockercoins/rng:v0.1 \ -o yaml --dry-run=client ``` - Save it to a file: ```bash kubectl create deployment rng --image=dockercoins/rng:v0.1 \ -o yaml --dry-run=client \ > rng.yaml ``` ] .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Changing the `kind` - Edit the YAML manifest and replace `Deployment` with `DaemonSet` .lab[ - Edit the YAML file and make the change <!-- ```bash vim rng.yaml``` ```wait kind: Deployment``` ```keys /Deployment``` ```key ^J``` ```keys cwDaemonSet``` ```key ^[``` ] ```keys :wq``` ```key ^J``` --> - Or, alternatively: ```bash sed -i "s/kind: Deployment/kind: DaemonSet/" ``` ] .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Creating the DaemonSet - Let's see if our DaemonSet manifest is valid! .lab[ - Try to `kubectl apply` our new YAML: ```bash kubectl apply -f rng.yaml ``` ] -- - Unfortunately, that doesn't work! .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Understanding the problem - The core of the error is: ``` unknown field "spec.replicas", unknown field "spec.strategy" ``` -- - *Obviously,* it doesn't make sense to specify a number of replicas for a daemon set (the field `spec.strategy` is also specific to Deployments) -- - Workaround: fix the YAML and remove these fields .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Fixing the problem - Let's remove the `replicas` field and try again .lab[ - Edit the `rng.yaml` file and remove the `replicas:` line - Then try to create the DaemonSet again: ```bash kubectl apply -f rng.yaml ``` ] - This time it should work! .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Checking what we've done - Did we transform our `deployment` into a `daemonset`? .lab[ - Look at the resources that we have now: ```bash kubectl get all ``` ] -- We have two resources called `rng`: - the *deployment* that was existing before - the *daemon set* that we just created We also have one too many pods. <br/> (The pod corresponding to the *deployment* still exists.) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## `deploy/rng` and `ds/rng` - You can have different resource types with the same name (i.e. a *deployment* and a *daemon set* both named `rng`) - We still have the old `rng` *deployment* ``` NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/rng 1 1 1 1 18m ``` - But now we have the new `rng` *daemon set* as well ``` NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/rng 2 2 2 2 2 <none> 9s ``` .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Too many pods - If we check with `kubectl get pods`, we see: - *one pod* for the deployment (named `rng-xxxxxxxxxx-yyyyy`) - *one pod per node* for the daemon set (named `rng-zzzzz`) ``` NAME READY STATUS RESTARTS AGE rng-54f57d4d49-7pt82 1/1 Running 0 11m rng-b85tm 1/1 Running 0 25s rng-hfbrr 1/1 Running 0 25s [...] ``` -- The daemon set created one pod per node, except on the control plane node. The control plane node has [taints](https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/) preventing pods from running there. (To schedule a pod on this node anyway, the pod will require appropriate [tolerations](https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/).) .footnote[(Off by one? We don't run these pods on the node hosting the control plane.)] .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Is this working? - Look at the web UI -- - The graph should now go above 10 hashes per second! -- - It looks like the newly created pods are serving traffic correctly - How and why did this happen? (We didn't do anything special to add them to the `rng` service load balancer!) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: pic .interstitial[] --- name: toc-labels-and-selectors class: title Labels and selectors .nav[ [Previous part](#toc-daemon-sets) | [Back to table of contents](#toc-part-3) | [Next part](#toc-rolling-updates) ] .debug[(automatically generated title slide)] --- # Labels and selectors - The `rng` *service* is load balancing requests to a set of pods - That set of pods is defined by the *selector* of the `rng` service .lab[ - Check the *selector* in the `rng` service definition: ```bash kubectl describe service rng ``` ] - The selector is `app=rng` - It means "all the pods having the label `app=rng`" (They can have additional labels as well, that's OK!) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Selector evaluation - We can use selectors with many `kubectl` commands - For instance, with `kubectl get`, `kubectl logs`, `kubectl delete` ... and more .lab[ - Get the list of pods matching selector `app=rng`: ```bash kubectl get pods -l app=rng kubectl get pods --selector app=rng ``` ] But ... why do these pods (in particular, the *new* ones) have this `app=rng` label? .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Where do labels come from? - When we create a deployment with `kubectl create deployment rng`, <br/>this deployment gets the label `app=rng` - The replica sets created by this deployment also get the label `app=rng` - The pods created by these replica sets also get the label `app=rng` - When we created the daemon set from the deployment, we re-used the same spec - Therefore, the pods created by the daemon set get the same labels .footnote[Note: when we use `kubectl run stuff`, the label is `run=stuff` instead.] .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Updating load balancer configuration - We would like to remove a pod from the load balancer - What would happen if we removed that pod, with `kubectl delete pod ...`? -- It would be re-created immediately (by the replica set or the daemon set) -- - What would happen if we removed the `app=rng` label from that pod? -- It would *also* be re-created immediately -- Why?!? .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Selectors for replica sets and daemon sets - The "mission" of a replica set is: "Make sure that there is the right number of pods matching this spec!" - The "mission" of a daemon set is: "Make sure that there is a pod matching this spec on each node!" -- - *In fact,* replica sets and daemon sets do not check pod specifications - They merely have a *selector*, and they look for pods matching that selector - Yes, we can fool them by manually creating pods with the "right" labels - Bottom line: if we remove our `app=rng` label ... ... The pod "disappears" for its parent, which re-creates another pod to replace it .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## Isolation of replica sets and daemon sets - Since both the `rng` daemon set and the `rng` replica set use `app=rng` ... ... Why don't they "find" each other's pods? -- - *Replica sets* have a more specific selector, visible with `kubectl describe` (It looks like `app=rng,pod-template-hash=abcd1234`) - *Daemon sets* also have a more specific selector, but it's invisible (It looks like `app=rng,controller-revision-hash=abcd1234`) - As a result, each controller only "sees" the pods it manages .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Removing a pod from the load balancer - Currently, the `rng` service is defined by the `app=rng` selector - The only way to remove a pod is to remove or change the `app` label - ... But that will cause another pod to be created instead! - What's the solution? -- - We need to change the selector of the `rng` service! - Let's add another label to that selector (e.g. `active=yes`) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Selectors with multiple labels - If a selector specifies multiple labels, they are understood as a logical *AND* (in other words: the pods must match all the labels) - We cannot have a logical *OR* (e.g. `app=api AND (release=prod OR release=preprod)`) - We can, however, apply as many extra labels as we want to our pods: - use selector `app=api AND prod-or-preprod=yes` - add `prod-or-preprod=yes` to both sets of pods - We will see later that in other places, we can use more advanced selectors .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## The plan 1. Add the label `active=yes` to all our `rng` pods 2. Update the selector for the `rng` service to also include `active=yes` 3. Toggle traffic to a pod by manually adding/removing the `active` label 4. Profit! *Note: if we swap steps 1 and 2, it will cause a short service disruption, because there will be a period of time during which the service selector won't match any pod. During that time, requests to the service will time out. By doing things in the order above, we guarantee that there won't be any interruption.* .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Adding labels to pods - We want to add the label `active=yes` to all pods that have `app=rng` - We could edit each pod one by one with `kubectl edit` ... - ... Or we could use `kubectl label` to label them all - `kubectl label` can use selectors itself .lab[ - Add `active=yes` to all pods that have `app=rng`: ```bash kubectl label pods -l app=rng active=yes ``` ] .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Updating the service selector - We need to edit the service specification - Reminder: in the service definition, we will see `app: rng` in two places - the label of the service itself (we don't need to touch that one) - the selector of the service (that's the one we want to change) .lab[ - Update the service to add `active: yes` to its selector: ```bash kubectl edit service rng ``` <!-- ```wait Please edit the object below``` ```keys /app: rng``` ```key ^J``` ```keys noactive: yes``` ```key ^[``` ] ```keys :wq``` ```key ^J``` --> ] -- ... And then we get *the weirdest error ever.* Why? .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## When the YAML parser is being too smart - YAML parsers try to help us: - `xyz` is the string `"xyz"` - `42` is the integer `42` - `yes` is the boolean value `true` - If we want the string `"42"` or the string `"yes"`, we have to quote them - So we have to use `active: "yes"` .footnote[For a good laugh: if we had used "ja", "oui", "si" ... as the value, it would have worked!] .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Updating the service selector, take 2 .lab[ - Update the YAML manifest of the service - Add `active: "yes"` to its selector <!-- ```wait Please edit the object below``` ```keys /yes``` ```key ^J``` ```keys cw"yes"``` ```key ^[``` ] ```keys :wq``` ```key ^J``` --> ] This time it should work! If we did everything correctly, the web UI shouldn't show any change. .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Updating labels - We want to disable the pod that was created by the deployment - All we have to do, is remove the `active` label from that pod - To identify that pod, we can use its name - ... Or rely on the fact that it's the only one with a `pod-template-hash` label - Good to know: - `kubectl label ... foo=` doesn't remove a label (it sets it to an empty string) - to remove label `foo`, use `kubectl label ... foo-` - to change an existing label, we would need to add `--overwrite` .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Removing a pod from the load balancer .lab[ - In one window, check the logs of that pod: ```bash POD=$(kubectl get pod -l app=rng,pod-template-hash -o name) kubectl logs --tail 1 --follow $POD ``` (We should see a steady stream of HTTP logs) <!-- ```wait HTTP/1.1``` ```tmux split-pane -v``` --> - In another window, remove the label from the pod: ```bash kubectl label pod -l app=rng,pod-template-hash active- ``` (The stream of HTTP logs should stop immediately) <!-- ```key ^D``` ```key ^C``` --> ] There might be a slight change in the web UI (since we removed a bit of capacity from the `rng` service). If we remove more pods, the effect should be more visible. .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## Updating the daemon set - If we scale up our cluster by adding new nodes, the daemon set will create more pods - These pods won't have the `active=yes` label - If we want these pods to have that label, we need to edit the daemon set spec - We can do that with e.g. `kubectl edit daemonset rng` .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## We've put resources in your resources - Reminder: a daemon set is a resource that creates more resources! - There is a difference between: - the label(s) of a resource (in the `metadata` block in the beginning) - the selector of a resource (in the `spec` block) - the label(s) of the resource(s) created by the first resource (in the `template` block) - We would need to update the selector and the template (metadata labels are not mandatory) - The template must match the selector (i.e. the resource will refuse to create resources that it will not select) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Labels and debugging - When a pod is misbehaving, we can delete it: another one will be recreated - But we can also change its labels - It will be removed from the load balancer (it won't receive traffic anymore) - Another pod will be recreated immediately - But the problematic pod is still here, and we can inspect and debug it - We can even re-add it to the rotation if necessary (Very useful to troubleshoot intermittent and elusive bugs) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- ## Labels and advanced rollout control - Conversely, we can add pods matching a service's selector - These pods will then receive requests and serve traffic - Examples: - one-shot pod with all debug flags enabled, to collect logs - pods created automatically, but added to rotation in a second step <br/> (by setting their label accordingly) - This gives us building blocks for canary and blue/green deployments .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## Advanced label selectors - As indicated earlier, service selectors are limited to a `AND` - But in many other places in the Kubernetes API, we can use complex selectors (e.g. Deployment, ReplicaSet, DaemonSet, NetworkPolicy ...) - These allow extra operations; specifically: - checking for presence (or absence) of a label - checking if a label is (or is not) in a given set - Relevant documentation: [Service spec](https://kubernetes.io/docs/reference/kubernetes-api/service-resources/service-v1/#ServiceSpec), [LabelSelector spec](https://kubernetes.io/docs/reference/kubernetes-api/common-definitions/label-selector/), [label selector doc](https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#label-selectors) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## Example of advanced selector ```yaml theSelector: matchLabels: app: portal component: api matchExpressions: - key: release operator: In values: [ production, preproduction ] - key: signed-off-by operator: Exists ``` This selector matches pods that meet *all* the indicated conditions. `operator` can be `In`, `NotIn`, `Exists`, `DoesNotExist`. A `nil` selector matches *nothing*, a `{}` selector matches *everything*. <br/> (Because that means "match all pods that meet at least zero condition".) .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## Services and Endpoints - Each Service has a corresponding Endpoints resource (see `kubectl get endpoints` or `kubectl get ep`) - That Endpoints resource is used by various controllers (e.g. `kube-proxy` when setting up `iptables` rules for ClusterIP services) - These Endpoints are populated (and updated) with the Service selector - We can update the Endpoints manually, but our changes will get overwritten - ... Except if the Service selector is empty! .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: extra-details ## Empty Service selector - If a service selector is empty, Endpoints don't get updated automatically (but we can still set them manually) - This lets us create Services pointing to arbitrary destinations (potentially outside the cluster; or things that are not in pods) - Another use-case: the `kubernetes` service in the `default` namespace (its Endpoints are maintained automatically by the API server) ??? :EN:- Scaling with Daemon Sets :FR:- Utilisation de Daemon Sets .debug[[k8s/daemonset.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/daemonset.md)] --- class: pic .interstitial[] --- name: toc-rolling-updates class: title Rolling updates .nav[ [Previous part](#toc-labels-and-selectors) | [Back to table of contents](#toc-part-3) | [Next part](#toc-accessing-logs-from-the-cli) ] .debug[(automatically generated title slide)] --- # Rolling updates - How should we update a running application? - Strategy 1: delete old version, then deploy new version (not great, because it obviously provokes downtime!) - Strategy 2: deploy new version, then delete old version (uses a lot of resources; also how do we shift traffic?) - Strategy 3: replace running pods one at a time (sounds interesting; and good news, Kubernetes does it for us!) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Rolling updates - With rolling updates, when a Deployment is updated, it happens progressively - The Deployment controls multiple Replica Sets - Each Replica Set is a group of identical Pods (with the same image, arguments, parameters ...) - During the rolling update, we have at least two Replica Sets: - the "new" set (corresponding to the "target" version) - at least one "old" set - We can have multiple "old" sets (if we start another update before the first one is done) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Update strategy - Two parameters determine the pace of the rollout: `maxUnavailable` and `maxSurge` - They can be specified in absolute number of pods, or percentage of the `replicas` count - At any given time ... - there will always be at least `replicas`-`maxUnavailable` pods available - there will never be more than `replicas`+`maxSurge` pods in total - there will therefore be up to `maxUnavailable`+`maxSurge` pods being updated - We have the possibility of rolling back to the previous version <br/>(if the update fails or is unsatisfactory in any way) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Checking current rollout parameters - Recall how we build custom reports with `kubectl` and `jq`: .lab[ - Show the rollout plan for our deployments: ```bash kubectl get deploy -o json | jq ".items[] | {name:.metadata.name} + .spec.strategy.rollingUpdate" ``` ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Rolling updates in practice - As of Kubernetes 1.8, we can do rolling updates with: `deployments`, `daemonsets`, `statefulsets` - Editing one of these resources will automatically result in a rolling update - Rolling updates can be monitored with the `kubectl rollout` subcommand .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Rolling out the new `worker` service .lab[ - Let's monitor what's going on by opening a few terminals, and run: ```bash kubectl get pods -w kubectl get replicasets -w kubectl get deployments -w ``` <!-- ```wait NAME``` ```key ^C``` --> - Update `worker` either with `kubectl edit`, or by running: ```bash kubectl set image deploy worker worker=dockercoins/worker:v0.2 ``` ] -- That rollout should be pretty quick. What shows in the web UI? .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Give it some time - At first, it looks like nothing is happening (the graph remains at the same level) - According to `kubectl get deploy -w`, the `deployment` was updated really quickly - But `kubectl get pods -w` tells a different story - The old `pods` are still here, and they stay in `Terminating` state for a while - Eventually, they are terminated; and then the graph decreases significantly - This delay is due to the fact that our worker doesn't handle signals - Kubernetes sends a "polite" shutdown request to the worker, which ignores it - After a grace period, Kubernetes gets impatient and kills the container (The grace period is 30 seconds, but [can be changed](https://kubernetes.io/docs/concepts/workloads/pods/pod/#termination-of-pods) if needed) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Rolling out something invalid - What happens if we make a mistake? .lab[ - Update `worker` by specifying a non-existent image: ```bash kubectl set image deploy worker worker=dockercoins/worker:v0.3 ``` - Check what's going on: ```bash kubectl rollout status deploy worker ``` <!-- ```wait Waiting for deployment``` ```key ^C``` --> ] -- Our rollout is stuck. However, the app is not dead. (After a minute, it will stabilize to be 20-25% slower.) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## What's going on with our rollout? - Why is our app a bit slower? - Because `MaxUnavailable=25%` ... So the rollout terminated 2 replicas out of 10 available - Okay, but why do we see 5 new replicas being rolled out? - Because `MaxSurge=25%` ... So in addition to replacing 2 replicas, the rollout is also starting 3 more - It rounded down the number of MaxUnavailable pods conservatively, <br/> but the total number of pods being rolled out is allowed to be 25+25=50% .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- class: extra-details ## The nitty-gritty details - We start with 10 pods running for the `worker` deployment - Current settings: MaxUnavailable=25% and MaxSurge=25% - When we start the rollout: - two replicas are taken down (as per MaxUnavailable=25%) - two others are created (with the new version) to replace them - three others are created (with the new version) per MaxSurge=25%) - Now we have 8 replicas up and running, and 5 being deployed - Our rollout is stuck at this point! .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Checking the dashboard during the bad rollout If you didn't deploy the Kubernetes dashboard earlier, just skip this slide. .lab[ - Connect to the dashboard that we deployed earlier - Check that we have failures in Deployments, Pods, and Replica Sets - Can we see the reason for the failure? ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Recovering from a bad rollout - We could push some `v0.3` image (the pod retry logic will eventually catch it and the rollout will proceed) - Or we could invoke a manual rollback .lab[ <!-- ```key ^C``` --> - Cancel the deployment and wait for the dust to settle: ```bash kubectl rollout undo deploy worker kubectl rollout status deploy worker ``` ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Rolling back to an older version - We reverted to `v0.2` - But this version still has a performance problem - How can we get back to the previous version? .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Multiple "undos" - What happens if we try `kubectl rollout undo` again? .lab[ - Try it: ```bash kubectl rollout undo deployment worker ``` - Check the web UI, the list of pods ... ] 🤔 That didn't work. .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Multiple "undos" don't work - If we see successive versions as a stack: - `kubectl rollout undo` doesn't "pop" the last element from the stack - it copies the N-1th element to the top - Multiple "undos" just swap back and forth between the last two versions! .lab[ - Go back to v0.2 again: ```bash kubectl rollout undo deployment worker ``` ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## In this specific scenario - Our version numbers are easy to guess - What if we had used git hashes? - What if we had changed other parameters in the Pod spec? .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Listing versions - We can list successive versions of a Deployment with `kubectl rollout history` .lab[ - Look at our successive versions: ```bash kubectl rollout history deployment worker ``` ] We don't see *all* revisions. We might see something like 1, 4, 5. (Depending on how many "undos" we did before.) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Explaining deployment revisions - These revisions correspond to our Replica Sets - This information is stored in the Replica Set annotations .lab[ - Check the annotations for our replica sets: ```bash kubectl describe replicasets -l app=worker | grep -A3 ^Annotations ``` ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- class: extra-details ## What about the missing revisions? - The missing revisions are stored in another annotation: `deployment.kubernetes.io/revision-history` - These are not shown in `kubectl rollout history` - We could easily reconstruct the full list with a script (if we wanted to!) .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- ## Rolling back to an older version - `kubectl rollout undo` can work with a revision number .lab[ - Roll back to the "known good" deployment version: ```bash kubectl rollout undo deployment worker --to-revision=1 ``` - Check the web UI or the list of pods ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- class: extra-details ## Changing rollout parameters - We want to: - revert to `v0.1` - be conservative on availability (always have desired number of available workers) - go slow on rollout speed (update only one pod at a time) - give some time to our workers to "warm up" before starting more The corresponding changes can be expressed in the following YAML snippet: .small[ ```yaml spec: template: spec: containers: - name: worker image: dockercoins/worker:v0.1 strategy: rollingUpdate: maxUnavailable: 0 maxSurge: 1 minReadySeconds: 10 ``` ] .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- class: extra-details ## Applying changes through a YAML patch - We could use `kubectl edit deployment worker` - But we could also use `kubectl patch` with the exact YAML shown before .lab[ .small[ - Apply all our changes and wait for them to take effect: ```bash kubectl patch deployment worker -p " spec: template: spec: containers: - name: worker image: dockercoins/worker:v0.1 strategy: rollingUpdate: maxUnavailable: 0 maxSurge: 1 minReadySeconds: 10 " kubectl rollout status deployment worker kubectl get deploy -o json worker | jq "{name:.metadata.name} + .spec.strategy.rollingUpdate" ``` ] ] ??? :EN:- Rolling updates :EN:- Rolling back a bad deployment :FR:- Mettre à jour un déploiement :FR:- Concept de *rolling update* et *rollback* :FR:- Paramétrer la vitesse de déploiement .debug[[k8s/rollout.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/rollout.md)] --- class: pic .interstitial[] --- name: toc-accessing-logs-from-the-cli class: title Accessing logs from the CLI .nav[ [Previous part](#toc-rolling-updates) | [Back to table of contents](#toc-part-4) | [Next part](#toc-namespaces) ] .debug[(automatically generated title slide)] --- # Accessing logs from the CLI - The `kubectl logs` command has limitations: - it cannot stream logs from multiple pods at a time - when showing logs from multiple pods, it mixes them all together - We are going to see how to do it better .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Doing it manually - We *could* (if we were so inclined) write a program or script that would: - take a selector as an argument - enumerate all pods matching that selector (with `kubectl get -l ...`) - fork one `kubectl logs --follow ...` command per container - annotate the logs (the output of each `kubectl logs ...` process) with their origin - preserve ordering by using `kubectl logs --timestamps ...` and merge the output -- - We *could* do it, but thankfully, others did it for us already! .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Stern [Stern](https://github.com/stern/stern) is an open source project originally by [Wercker](http://www.wercker.com/). From the README: *Stern allows you to tail multiple pods on Kubernetes and multiple containers within the pod. Each result is color coded for quicker debugging.* *The query is a regular expression so the pod name can easily be filtered and you don't need to specify the exact id (for instance omitting the deployment id). If a pod is deleted it gets removed from tail and if a new pod is added it automatically gets tailed.* Exactly what we need! .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Checking if Stern is installed - Run `stern` (without arguments) to check if it's installed: ``` $ stern Tail multiple pods and containers from Kubernetes Usage: stern pod-query [flags] ``` - If it's missing, let's see how to install it .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Installing Stern - Stern is written in Go - Go programs are usually very easy to install (no dependencies, extra libraries to install, etc) - Binary releases are available [on GitHub][stern-releases] - Stern is also available through most package managers (e.g. on macOS, we can `brew install stern` or `sudo port install stern`) [stern-releases]: https://github.com/stern/stern/releases .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Using Stern - There are two ways to specify the pods whose logs we want to see: - `-l` followed by a selector expression (like with many `kubectl` commands) - with a "pod query," i.e. a regex used to match pod names - These two ways can be combined if necessary .lab[ - View the logs for all the pingpong containers: ```bash stern pingpong ``` <!-- ```wait seq=``` ```key ^C``` --> ] .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Stern convenient options - The `--tail N` flag shows the last `N` lines for each container (Instead of showing the logs since the creation of the container) - The `-t` / `--timestamps` flag shows timestamps - The `--all-namespaces` flag is self-explanatory .lab[ - View what's up with the `coredns` system containers: ```bash stern --tail 1 --timestamps --all-namespaces coredns ``` <!-- ```wait coredns-``` ```key ^C``` --> ] .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Using Stern with a selector - When specifying a selector, we can omit the value for a label - This will match all objects having that label (regardless of the value) - Everything created with `kubectl run` has a label `run` - Everything created with `kubectl create deployment` has a label `app` - We can use that property to view the logs of all the pods created with `kubectl create deployment` .lab[ - View the logs for all the things started with `kubectl create deployment`: ```bash stern -l app ``` <!-- ```wait seq=``` ```key ^C``` --> ] .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- ## Other useful tools - `kl` (https://github.com/robinovitch61/kl) *select containers interactively , navigate/view/search logs* - `gonzo` (https://github.com/control-theory/gonzo) *real-time stream analysis, statistics, etc.* ??? :EN:- Viewing pod logs from the CLI :FR:- Consulter les logs des pods depuis la CLI .debug[[k8s/logs-cli.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/logs-cli.md)] --- class: pic .interstitial[] --- name: toc-namespaces class: title Namespaces .nav[ [Previous part](#toc-accessing-logs-from-the-cli) | [Back to table of contents](#toc-part-4) | [Next part](#toc-managing-stacks-with-helm) ] .debug[(automatically generated title slide)] --- # Namespaces - Resources like Pods, Deployments, Services... exist in *Namespaces* - So far, we (probably) have been using the `default` Namespace - We can create other Namespaces to organize our resources .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Use-cases - Example: a "dev" cluster where each developer has their own Namespace (and they only have access to their own Namespace, not to other folks' Namespaces) - Example: a cluster with one `production` and one `staging` Namespace (with similar applications running in each of them, but with different sizes) - Example: a "production" cluster with one Namespace per application (or one Namespace per component of a bigger application) - Example: a "production" cluster with many instances of the same application (e.g. SAAS application with one instance per customer) .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Pre-existing Namespaces - On a freshly deployed cluster, we typically have the following four Namespaces: - `default` (initial Namespace for our applications; also holds the `kubernetes` Service) - `kube-system` (for the control plane) - `kube-public` (contains one ConfigMap for cluster discovery) - `kube-node-lease` (in Kubernetes 1.14 and later; contains Lease objects) - Over time, we will almost certainly create more Namespaces! .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Creating a Namespace - Let's see two ways to create a Namespace! .lab[ - First, with `kubectl create namespace`: ```bash kubectl create namespace blue ``` - Then, with a YAML snippet: ```bash kubectl apply -f- <<EOF apiVersion: v1 kind: Namespace metadata: name: green EOF ``` ] .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Using namespaces - We can pass a `-n` or `--namespace` flag to most `kubectl` commands .lab[ - Create a Deployment in the `blue` Namespace: ```bash kubectl create deployment purple --image jpetazzo/color --namespace blue ``` - Check the Pods that were just created: ```bash kubectl get pods --all-namespaces kubectl get pods --all-namespaces --selector app=purple ``` ] .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Switching the active Namespace - We can change the "active" Namespace - This is useful if we're going to work in a given Namespace for a while - it is easier than passing `--namespace ...` all the time - it helps to avoid mistakes <br/> (e.g.: `kubectl delete -f foo.yaml` whoops wrong Namespace!) - We're going to see ~~one~~ ~~two~~ three different methods to switch namespaces! .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Method 1 (kubens/kns) - To switch to the `blue` Namespace, run: ```bash kubens blue ``` - `kubens` is sometimes renamed or aliased to `kns` (even less keystrokes!) - `kubens -` switches back to the previous Namespace - Pros: probably the easiest method out there - Cons: `kubens` is an extra tool that you need to install .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Method 2 (edit kubeconfig) - Edit `~/.kube/config` - There should be a `namespace:` field somewhere - except if we haven't changed Namespace yet! - in that case, change Namespace at least once using another method - We can just edit that file, and `kubectl` will use the new Namespace from now on - Pros: kind of easy; doesn't require extra tools - Cons: there can be multiple `namespace:` fields in that file; difficult to automate .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Method 3 (kubectl config) - To switch to the `blue` Namespace, run: ```bash kubectl config set-context --current --namespace blue ``` - This automatically edits the kubeconfig file - This is exactly what `kubens` does behind the scenes! - Pros: always works (as long as we have `kubectl`) - Cons: long and complicated to type (but it's a good exercise for our fingers, maybe?) .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- class: extra-details ## What are contexts? - Context = cluster + user + namespace - Useful to quickly switch between multiple clusters (e.g. dev, prod, or different applications, different customers...) - Also useful to quickly switch between identities (e.g. developer with "regular" access vs. cluster-admin) - Switch context with `kubectl config set-context` or `kubectx` / `kctx` - It is also possible to switch the kubeconfig file altogether (by specifying `--kubeconfig` or setting the `KUBECONFIG` environment variable) .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- class: extra-details ## What's in a context - NAME is an arbitrary string to identify the context - CLUSTER is a reference to a cluster (i.e. API endpoint URL, and optional certificate) - AUTHINFO is a reference to the authentication information to use (i.e. a TLS client certificate, token, or otherwise) - NAMESPACE is the namespace (empty string = `default`) .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Namespaces, Services, and DNS - When a Service is created, a record is added to the Kubernetes DNS - For instance, for service `auth` in domain `staging`, this is typically: `auth.staging.svc.cluster.local` - By default, Pods are configured to resolve names in their Namespace's domain - For instance, a Pod in Namespace `staging` will have the following "search list": `search staging.svc.cluster.local svc.cluster.local cluster.local` .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Pods connecting to Services - Let's assume that we are in Namespace `staging` - ... and there is a Service named `auth` - ... and we have code running in a Pod in that same Namespace - Our code can: - connect to Service `auth` in the same Namespace with `http://auth/` - connect to Service `auth` in another Namespace (e.g. `prod`) with `http://auth.prod` - ... or `http://auth.prod.svc` or `http://auth.prod.svc.cluster.local` .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Deploying multiple instances of a stack If all the containers in a given stack use DNS for service discovery, that stack can be deployed identically in multiple Namespaces. Each copy of the stack will communicate with the services belonging to the stack's Namespace. Example: we can deploy multiple copies of DockerCoins, one per Namespace, without changing a single line of code in DockerCoins, and even without changing a single line of code in our YAML manifests! This is similar to what can be achieved e.g. with Docker Compose (but with Docker Compose, each stack is deployed in a Docker "network" instead of a Kubernetes Namespace). .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Namespaces and isolation - Namespaces *do not* provide isolation - By default, Pods in e.g. `prod` and `staging` Namespaces can communicate - Actual isolation is implemented with *network policies* - Network policies are resources (like deployments, services, namespaces...) - Network policies specify which flows are allowed: - between pods - from pods to the outside world - and vice-versa .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## `kubens` and `kubectx` - These tools are available from https://github.com/ahmetb/kubectx - They were initially simple shell scripts, and are now full-fledged Go programs - On our clusters, they are installed as `kns` and `kctx` (for brevity and to avoid completion clashes between `kubectx` and `kubectl`) .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## `kube-ps1` - It's easy to lose track of our current cluster / context / namespace - `kube-ps1` makes it easy to track these, by showing them in our shell prompt - It is installed on our training clusters, and when using [shpod](https://github.com/jpetazzo/shpod) - It gives us a prompt looking like this one: ``` [123.45.67.89] `(kubernetes-admin@kubernetes:default)` docker@node1 ~ ``` (The highlighted part is `context:namespace`, managed by `kube-ps1`) - Highly recommended if you work across multiple contexts or namespaces! .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- ## Installing `kube-ps1` - It's a simple shell script available from https://github.com/jonmosco/kube-ps1 - It needs to be [installed in our profile/rc files](https://github.com/jonmosco/kube-ps1#installing) (instructions differ depending on platform, shell, etc.) - Once installed, it defines aliases called `kube_ps1`, `kubeon`, `kubeoff` (to selectively enable/disable it when needed) - Pro-tip: install it on your machine during the next break! ??? :EN:- Organizing resources with Namespaces :FR:- Organiser les ressources avec des *namespaces* .debug[[k8s/namespaces.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/namespaces.md)] --- class: pic .interstitial[] --- name: toc-managing-stacks-with-helm class: title Managing stacks with Helm .nav[ [Previous part](#toc-namespaces) | [Back to table of contents](#toc-part-4) | [Next part](#toc-creating-a-basic-chart) ] .debug[(automatically generated title slide)] --- # Managing stacks with Helm - Helm is a (kind of!) package manager for Kubernetes - We can use it to: - find existing packages (called "charts") created by other folks - install these packages, configuring them for our particular setup - package our own things (for distribution or for internal use) - manage the lifecycle of these installs (rollback to previous version etc.) - It's a "CNCF graduate project", indicating a certain level of maturity (more on that later) .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Helm features - With Helm, we create "charts" - These charts can be used internally or distributed publicly - Public charts can be indexed through the [Artifact Hub](https://artifacthub.io/) - This gives us a way to find and install other folks' charts - Helm also gives us ways to manage the lifecycle of what we install: - keep track of what we have installed - upgrade versions, change parameters, roll back, uninstall - Furthermore, even if it's not "the" standard, it's definitely "a" standard! .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## CNCF graduation status - On April 30th 2020, Helm was the 10th project to *graduate* within the CNCF (alongside Containerd, Prometheus, and Kubernetes itself) - This is an acknowledgement by the CNCF for projects that *demonstrate thriving adoption, an open governance process, <br/> and a strong commitment to community, sustainability, and inclusivity.* - See [CNCF announcement](https://www.cncf.io/announcement/2020/04/30/cloud-native-computing-foundation-announces-helm-graduation/) and [Helm announcement](https://helm.sh/blog/celebrating-helms-cncf-graduation/) - In other words: Helm is here to stay .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Helm concepts - `helm` is a CLI tool - It is used to find, install, upgrade *charts* - A chart is an archive containing templatized YAML bundles - Charts are versioned - Charts can be stored on private or public repositories .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Differences between charts and packages - A package (deb, rpm...) contains binaries, libraries, etc. - A chart contains YAML manifests (the binaries, libraries, etc. are in the images referenced by the chart) - On most distributions, a package can only be installed once (installing another version replaces the installed one) - A chart can be installed multiple times - Each installation is called a *release* - This allows to install e.g. 10 instances of MongoDB (with potentially different versions and configurations) .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- class: extra-details ## Wait a minute ... *But, on my Debian system, I have Python 2 **and** Python 3. <br/> Also, I have multiple versions of the Postgres database engine!* Yes! But they have different package names: - `python2.7`, `python3.8` - `postgresql-10`, `postgresql-11` Good to know: the Postgres package in Debian includes provisions to deploy multiple Postgres servers on the same system, but it's an exception (and it's a lot of work done by the package maintainer, not by the `dpkg` or `apt` tools). .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Helm 2 vs Helm 3 - Helm 3 was released [November 13, 2019](https://helm.sh/blog/helm-3-released/) - Charts remain compatible between Helm 2 and Helm 3 - The CLI is very similar (with minor changes to some commands) - The main difference is that Helm 2 uses `tiller`, a server-side component - Helm 3 doesn't use `tiller` at all, making it simpler (yay!) - If you see references to `tiller` in a tutorial, documentation... that doc is obsolete! .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- class: extra-details ## What was the problem with `tiller`? - With Helm 3: - the `helm` CLI communicates directly with the Kubernetes API - it creates resources (deployments, services...) with our credentials - With Helm 2: - the `helm` CLI communicates with `tiller`, telling `tiller` what to do - `tiller` then communicates with the Kubernetes API, using its own credentials - This indirect model caused significant permissions headaches - It also made it more complicated to embed Helm in other tools .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Installing Helm - If the `helm` CLI is not installed in your environment, install it .lab[ - Check if `helm` is installed: ```bash helm ``` - If it's not installed, run the following command: ```bash curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get-helm-3 \ | bash ``` ] (To install Helm 2, replace `get-helm-3` with `get`.) .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Charts and repositories - A *repository* (or repo in short) is a collection of charts - It's just a bunch of files (they can be hosted by a static HTTP server, or on a local directory) - We can add "repos" to Helm, giving them a nickname - The nickname is used when referring to charts on that repo (for instance, if we try to install `hello/world`, that means the chart `world` on the repo `hello`; and that repo `hello` might be something like https://blahblah.hello.io/charts/) .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## How to find charts - Go to the [Artifact Hub](https://artifacthub.io/packages/search?kind=0) (https://artifacthub.io) - Or use `helm search hub ...` from the CLI - Let's try to find a Helm chart for something called "OWASP Juice Shop"! (it is a famous demo app used in security challenges) .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Finding charts from the CLI - We can use `helm search hub <keyword>` .lab[ - Look for the OWASP Juice Shop app: ```bash helm search hub owasp juice ``` - Since the URLs are truncated, try with the YAML output: ```bash helm search hub owasp juice -o yaml ``` ] Then go to → https://artifacthub.io/packages/helm/securecodebox/juice-shop .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Finding charts on the web - We can also use the Artifact Hub search feature .lab[ - Go to https://artifacthub.io/ - In the search box on top, enter "owasp juice" - Click on the "juice-shop" result (not "multi-juicer" or "juicy-ctf") ] .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Installing the chart - Click on the "Install" button, it will show instructions .lab[ - First, add the repository for that chart: ```bash helm repo add juice https://charts.securecodebox.io ``` - Then, install the chart: ```bash helm install my-juice-shop juice/juice-shop ``` ] Note: it is also possible to install directly a chart, with `--repo https://...` .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Charts and releases - "Installing a chart" means creating a *release* - In the previous example, the release was named "my-juice-shop" - We can also use `--generate-name` to ask Helm to generate a name for us .lab[ - List the releases: ```bash helm list ``` - Check that we have a `my-juice-shop-...` Pod up and running: ```bash kubectl get pods ``` ] .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Viewing resources of a release - This specific chart labels all its resources with a `release` label - We can use a selector to see these resources .lab[ - List all the resources created by this release: ```bash kubectl get all --selector=app.kubernetes.io/instance=my-juice-shop ``` ] Note: this label wasn't added automatically by Helm. <br/> It is defined in that chart. In other words, not all charts will provide this label. .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Configuring a release - By default, `juice/juice-shop` creates a service of type `ClusterIP` - We would like to change that to a `NodePort` - We could use `kubectl edit service my-juice-shop`, but ... ... our changes would get overwritten next time we update that chart! - Instead, we are going to *set a value* - Values are parameters that the chart can use to change its behavior - Values have default values - Each chart is free to define its own values and their defaults .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Checking possible values - We can inspect a chart with `helm show` or `helm inspect` .lab[ - Look at the README for the app: ```bash helm show readme juice/juice-shop ``` - Look at the values and their defaults: ```bash helm show values juice/juice-shop ``` ] The `values` may or may not have useful comments. The `readme` may or may not have (accurate) explanations for the values. (If we're unlucky, there won't be any indication about how to use the values!) .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Setting values - Values can be set when installing a chart, or when upgrading it - We are going to update `my-juice-shop` to change the type of the service .lab[ - Update `my-juice-shop`: ```bash helm upgrade my-juice-shop juice/juice-shop \ --set service.type=NodePort ``` ] Note that we have to specify the chart that we use (`juice/my-juice-shop`), even if we just want to update some values. We can set multiple values. If we want to set many values, we can use `-f`/`--values` and pass a YAML file with all the values. All unspecified values will take the default values defined in the chart. .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- ## Connecting to the Juice Shop - Let's check the app that we just installed .lab[ - Check the node port allocated to the service: ```bash kubectl get service my-juice-shop PORT=$(kubectl get service my-juice-shop -o jsonpath={..nodePort}) ``` - Connect to it: ```bash curl localhost:$PORT/ ``` ] ??? :EN:- Helm concepts :EN:- Installing software with Helm :EN:- Finding charts on the Artifact Hub :FR:- Fonctionnement général de Helm :FR:- Installer des composants via Helm :FR:- Trouver des *charts* sur *Artifact Hub* :T: Getting started with Helm and its concepts :Q: Which comparison is the most adequate? :A: Helm is a firewall, charts are access lists :A: ✔️Helm is a package manager, charts are packages :A: Helm is an artefact repository, charts are artefacts :A: Helm is a CI/CD platform, charts are CI/CD pipelines :Q: What's required to distribute a Helm chart? :A: A Helm commercial license :A: A Docker registry :A: An account on the Helm Hub :A: ✔️An HTTP server .debug[[k8s/helm-intro.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-intro.md)] --- class: pic .interstitial[] --- name: toc-creating-a-basic-chart class: title Creating a basic chart .nav[ [Previous part](#toc-managing-stacks-with-helm) | [Back to table of contents](#toc-part-4) | [Next part](#toc-next-steps) ] .debug[(automatically generated title slide)] --- # Creating a basic chart - We are going to show a way to create a *very simplified* chart - In a real chart, *lots of things* would be templatized (Resource names, service types, number of replicas...) .lab[ - Create a sample chart: ```bash helm create dockercoins ``` - Move away the sample templates and create an empty template directory: ```bash mv dockercoins/templates dockercoins/default-templates mkdir dockercoins/templates ``` ] .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Adding the manifests of our app - There is a convenient `dockercoins.yml` in the repo .lab[ - Copy the YAML file to the `templates` subdirectory in the chart: ```bash cp ~/container.training/k8s/dockercoins.yaml dockercoins/templates ``` ] - Note: it is probably easier to have multiple YAML files (rather than a single, big file with all the manifests) - But that works too! .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Testing our Helm chart - Our Helm chart is now ready (as surprising as it might seem!) .lab[ - Let's try to install the chart: ``` helm install helmcoins dockercoins ``` (`helmcoins` is the name of the release; `dockercoins` is the local path of the chart) ] -- - If the application is already deployed, this will fail: ``` Error: rendered manifests contain a resource that already exists. Unable to continue with install: existing resource conflict: kind: Service, namespace: default, name: hasher ``` .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Switching to another namespace - If there is already a copy of dockercoins in the current namespace: - we can switch with `kubens` or `kubectl config set-context` - we can also tell Helm to use a different namespace .lab[ - Create a new namespace: ```bash kubectl create namespace helmcoins ``` - Deploy our chart in that namespace: ```bash helm install helmcoins dockercoins --namespace=helmcoins ``` ] .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Helm releases are namespaced - Let's try to see the release that we just deployed .lab[ - List Helm releases: ```bash helm list ``` ] Our release doesn't show up! We have to specify its namespace (or switch to that namespace). .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Specifying the namespace - Try again, with the correct namespace .lab[ - List Helm releases in `helmcoins`: ```bash helm list --namespace=helmcoins ``` ] .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Checking our new copy of DockerCoins - We can check the worker logs, or the web UI .lab[ - Retrieve the NodePort number of the web UI: ```bash kubectl get service webui --namespace=helmcoins ``` - Open it in a web browser - Look at the worker logs: ```bash kubectl logs deploy/worker --tail=10 --follow --namespace=helmcoins ``` ] Note: it might take a minute or two for the worker to start. .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Discussion, shortcomings - Helm (and Kubernetes) best practices recommend to add a number of annotations (e.g. `app.kubernetes.io/name`, `helm.sh/chart`, `app.kubernetes.io/instance` ...) - Our basic chart doesn't have any of these - Our basic chart doesn't use any template tag - Does it make sense to use Helm in that case? - *Yes,* because Helm will: - track the resources created by the chart - save successive revisions, allowing us to rollback [Helm docs][helm-labels] and [Kubernetes docs][k8s-labels] have details about recommended annotations and labels. [helm-labels]: https://helm.sh/docs/chart_best_practices/labels/ [k8s-labels]: https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Cleaning up - Let's remove that chart before moving on .lab[ - Delete the release (don't forget to specify the namespace): ```bash helm delete helmcoins --namespace=helmcoins ``` ] .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Tips when writing charts - It is not necessary to `helm install`/`upgrade` to test a chart - If we just want to look at the generated YAML, use `helm template`: ```bash helm template ./my-chart helm template release-name ./my-chart ``` - Of course, we can use `--set` and `--values` too - Note that this won't fully validate the YAML! (e.g. if there is `apiVersion: klingon` it won't complain) - This can be used when trying things out .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- ## Exploring the templating system Try to put something like this in a file in the `templates` directory: ```yaml hello: {{ .Values.service.port }} comment: {{/* something completely.invalid !!! */}} type: {{ .Values.service | typeOf | printf }} ### print complex value {{ .Values.service | toYaml }} ### indent it indented: {{ .Values.service | toYaml | indent 2 }} ``` Then run `helm template`. The result is not a valid YAML manifest, but this is a great debugging tool! ??? :EN:- Writing a basic Helm chart for the whole app :FR:- Écriture d'un *chart* Helm simplifié .debug[[k8s/helm-create-basic-chart.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/helm-create-basic-chart.md)] --- class: pic .interstitial[] --- name: toc-next-steps class: title Next steps .nav[ [Previous part](#toc-creating-a-basic-chart) | [Back to table of contents](#toc-part-4) | [Next part](#toc-links-and-resources) ] .debug[(automatically generated title slide)] --- # Next steps *Alright, how do I get started and containerize my apps?* -- Suggested containerization checklist: .checklist[ - write a Dockerfile for one service in one app - write Dockerfiles for the other (buildable) services - write a Compose file for that whole app - make sure that devs are empowered to run the app in containers - set up automated builds of container images from the code repo - set up a CI pipeline using these container images - set up a CD pipeline (for staging/QA) using these images ] And *then* it is time to look at orchestration! .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Options for our first production cluster - Get a managed cluster from a major cloud provider (AKS, EKS, GKE...) (price: $, difficulty: medium) - Hire someone to deploy it for us (price: $$, difficulty: easy) - Do it ourselves (price: $-$$$, difficulty: hard) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## One big cluster vs. multiple small ones - Yes, it is possible to have prod+dev in a single cluster (and implement good isolation and security with RBAC, network policies...) - But it is not a good idea to do that for our first deployment - Start with a production cluster + at least a test cluster - Implement and check RBAC and isolation on the test cluster (e.g. deploy multiple test versions side-by-side) - Make sure that all our devs have usable dev clusters (whether it's a local minikube or a full-blown multi-node cluster) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Namespaces - Namespaces let you run multiple identical stacks side by side - Two namespaces (e.g. `blue` and `green`) can each have their own `redis` service - Each of the two `redis` services has its own `ClusterIP` - CoreDNS creates two entries, mapping to these two `ClusterIP` addresses: `redis.blue.svc.cluster.local` and `redis.green.svc.cluster.local` - Pods in the `blue` namespace get a *search suffix* of `blue.svc.cluster.local` - As a result, resolving `redis` from a pod in the `blue` namespace yields the "local" `redis` .warning[This does not provide *isolation*! That would be the job of network policies.] .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Relevant sections - [Namespaces](kube-selfpaced.yml.html#toc-namespaces) - [Network Policies](kube-selfpaced.yml.html#toc-network-policies) - [Role-Based Access Control](kube-selfpaced.yml.html#toc-authentication-and-authorization) (covers permissions model, user and service accounts management ...) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Stateful services (databases etc.) - As a first step, it is wiser to keep stateful services *outside* of the cluster - Exposing them to pods can be done with multiple solutions: - `ExternalName` services <br/> (`redis.blue.svc.cluster.local` will be a `CNAME` record) - `ClusterIP` services with explicit `Endpoints` <br/> (instead of letting Kubernetes generate the endpoints from a selector) - Ambassador services <br/> (application-level proxies that can provide credentials injection and more) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Stateful services (second take) - If we want to host stateful services on Kubernetes, we can use: - a storage provider - persistent volumes, persistent volume claims - stateful sets - Good questions to ask: - what's the *operational cost* of running this service ourselves? - what do we gain by deploying this stateful service on Kubernetes? - Relevant sections: [Volumes](kube-selfpaced.yml.html#toc-volumes) | [Stateful Sets](kube-selfpaced.yml.html#toc-stateful-sets) | [Persistent Volumes](kube-selfpaced.yml.html#toc-highly-available-persistent-volumes) - Excellent [blog post](http://www.databasesoup.com/2018/07/should-i-run-postgres-on-kubernetes.html) tackling the question: “Should I run Postgres on Kubernetes?” .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## HTTP traffic handling - *Services* are layer 4 constructs - HTTP is a layer 7 protocol - It is handled by *ingresses* (a different resource kind) - *Ingresses* allow: - virtual host routing - session stickiness - URI mapping - and much more! - [This section](kube-selfpaced.yml.html#toc-exposing-http-services-with-ingress-resources) shows how to expose multiple HTTP apps using [Træfik](https://docs.traefik.io/user-guide/kubernetes/) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Logging - Logging is delegated to the container engine - Logs are exposed through the API - Logs are also accessible through local files (`/var/log/containers`) - Log shipping to a central platform is usually done through these files (e.g. with an agent bind-mounting the log directory) - [This section](kube-selfpaced.yml.html#toc-centralized-logging) shows how to do that with [Fluentd](https://docs.fluentd.org/v0.12/articles/kubernetes-fluentd) and the EFK stack .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Metrics - The kubelet embeds [cAdvisor](https://github.com/google/cadvisor), which exposes container metrics (cAdvisor might be separated in the future for more flexibility) - It is a good idea to start with [Prometheus](https://prometheus.io/) (even if you end up using something else) - Starting from Kubernetes 1.8, we can use the [Metrics API](https://kubernetes.io/docs/tasks/debug-application-cluster/core-metrics-pipeline/) - [Heapster](https://github.com/kubernetes/heapster) was a popular add-on (but is being [deprecated](https://github.com/kubernetes/heapster/blob/master/docs/deprecation.md) starting with Kubernetes 1.11) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Managing the configuration of our applications - Two constructs are particularly useful: secrets and config maps - They allow to expose arbitrary information to our containers - **Avoid** storing configuration in container images (There are some exceptions to that rule, but it's generally a Bad Idea) - **Never** store sensitive information in container images (It's the container equivalent of the password on a post-it note on your screen) - [This section](kube-selfpaced.yml.html#toc-managing-configuration) shows how to manage app config with config maps (among others) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Managing stack deployments - Applications are made of many resources (Deployments, Services, and much more) - We need to automate the creation / update / management of these resources - There is no "absolute best" tool or method; it depends on: - the size and complexity of our stack(s) - how often we change it (i.e. add/remove components) - the size and skills of our team .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## A few tools to manage stacks - Shell scripts invoking `kubectl` - YAML resource manifests committed to a repo - [Kustomize](https://github.com/kubernetes-sigs/kustomize) (YAML manifests + patches applied on top) - [Helm](https://github.com/kubernetes/helm) (YAML manifests + templating engine) - [Spinnaker](https://www.spinnaker.io/) (Netflix' CD platform) - [Brigade](https://brigade.sh/) (event-driven scripting; no YAML) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Cluster federation --  -- Sorry Star Trek fans, this is not the federation you're looking for! -- (If I add "Your cluster is in another federation" I might get a 3rd fandom wincing!) .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- ## Cluster federation - Kubernetes master operation relies on etcd - etcd uses the [Raft](https://raft.github.io/) protocol - Raft recommends low latency between nodes - What if our cluster spreads to multiple regions? -- - Break it down in local clusters - Regroup them in a *cluster federation* - Synchronize resources across clusters - Discover resources across clusters .debug[[k8s/whatsnext.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/whatsnext.md)] --- class: pic .interstitial[] --- name: toc-links-and-resources class: title Links and resources .nav[ [Previous part](#toc-next-steps) | [Back to table of contents](#toc-part-4) | [Next part](#toc-) ] .debug[(automatically generated title slide)] --- # Links and resources - [Microsoft Learn](https://docs.microsoft.com/learn/) - [Azure Kubernetes Service](https://docs.microsoft.com/azure/aks/) - [Cloud Developer Advocates](https://developer.microsoft.com/advocates/) - [Kubernetes Community](https://kubernetes.io/community/) - Slack, Google Groups, meetups - [Local meetups](https://www.meetup.com/) - [devopsdays](https://www.devopsdays.org/) .footnote[These slides (and future updates) are on → http://container.training/] .debug[[k8s/links-bridget.md](https://github.com/jpetazzo/container.training/tree/main/slides/k8s/links-bridget.md)] --- class: title, self-paced Thank you! .debug[[shared/thankyou.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/thankyou.md)] --- class: title, in-person That's all, folks! <br/> Questions?  .debug[[shared/thankyou.md](https://github.com/jpetazzo/container.training/tree/main/slides/shared/thankyou.md)]